
Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

Продолжая разговор про Apache Zeppelin, сегодня рассмотрим, как на его основе ведущий разработчик отечественных Big Data решений, компания «Аренадата Софтвер», построила самообслуживаемый сервис (self-service) Data Science и BI-аналитики – Arenadata Analytic Workspace. Читайте далее, как развернуть «с нуля» рабочее место дата-аналитика, где место этого программного решения в конвейере DataOps и при...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...

В этой статье разберем кейс построения экосистемы управления Big Data с озером данных на примере федеральной фармацевтической сети - российской Ассоциации независимых аптек (АСНА). Читайте в этом материале, зачем фармацевтическому ритейлеру большие данные, с какими трудностями столкнулся этот проект цифровизации и как открытые технологии (Arenadata Hadoop, Apache Spark, NiFi и...

Мы уже затрагивали тему корпоративных хранилищ данных (КХД), управления мастер-данными и нормативно-справочной информаций (НСИ) в контексте технологий Big Data. В продолжение этого, сегодня рассмотрим, что такое профилирование данных, зачем это нужно, при чем тут озера данных (Data Lake) и ETL-процессы, а также прочие аспекты инженерии и аналитики больших данных. Что...

В этой статье рассмотрим интеграцию ClickHouse с Apache Kafka: когда и зачем она нужна, как связать эти две Big Data системы, каковы ограничения и недостатки существующих способов и каким образом их можно обойти. Также разберем, почему кластер Кликхаус использует Zookeeper и что такое материализованное представление таблицы Кафка. Big Data маркетинг,...

Мы уже рассказывали про интеграцию Tarantool с Apache Kafka на примере Arenadata Grid. Сегодня рассмотрим, как интегрировать Кафка с MPP-СУБД Greenplum и каковы ограничения каждого из существующих способов. Читайте в сегодняшнем материале, что такое GPSS, PXF и при чем тут Docker-контейнер с коннектором Кафка для Arenadata DB. IoT и не...

Сегодня рассмотрим ключевые достоинства и недостатки резидентных СУБД для больших данных на примере Tarantool. Читайте в нашей статье про основные сценарии использования In-Memory Database (IMDB) в области Big Data с конкретными кейсами из реального бизнеса от Альфа-Банка, Аэрофлота, Тинькофф-Банка и Мегафона. Где и как используются In-Memory в Big Data: 4...
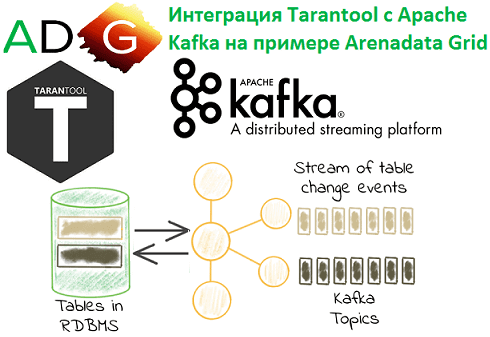
Продолжая разбираться с In-Memory СУБД Tarantool и Arenadata Grid, сегодня рассмотрим, как эти резидентные базы данных интегрируются с Apache Kafka. Читайте в нашей статье, что такое коннекторы и процессоры, а также как записать в топик Кафка сообщение, SQL-запрос или часть таблицы. Arenadata Grid и Apache Kafka: коннектор + процессоры Напомним,...

В этой статье мы рассмотрим резидентные (In-Memory) базы данных на примере Tarantool и Arenadata Grid: что это, как они работают и где используются. Еще поговорим, каким образом эти Big Data системы могут ускорить работу распределенных приложений без замены существующих СУБД, а также при чем здесь промышленный интернет вещей и экосистема...