 1316
1316 
Содержание
В этой статье рассмотрим интеграцию ClickHouse с Apache Kafka: когда и зачем она нужна, как связать эти две Big Data системы, каковы ограничения и недостатки существующих способов и каким образом их можно обойти. Также разберем, почему кластер Кликхаус использует Zookeeper и что такое материализованное представление таблицы Кафка.
Big Data маркетинг, непрерывный мониторинг и IoT: зачем нужна интеграция ClickHouse с Apache Kafka
Напомним, ClickHouse – это колоночная СУБД от отечественной компании «Яндекс» с открытым кодом для быстрой обработки аналитических запросов в режиме реального времени на структурированных больших данных [1]. Изначально разработчики ClickHouse предусмотрели возможность потоковой заливки данных из Apache Kafka. На практике такая задача может возникнуть, например, при маркетинговой аналитике, когда необходимо оперативно оценить успешность рекламного блока с минимальной задержкой. Вычисления производятся на основе данных о множестве событий около 100 миллионов в час. Apache Kafka отлично справляется с таким потоком сообщений, собирая и агрегируя их, однако она не подходит для интерактивной маркетинговой аналитики [2]. ClickHouse превосходно решает подобные задачи благодаря столбцовой организации хранения данных, когда значения из разных столбцов хранятся отдельно, а данные одного столбца — вместе. Это обусловливает высокую скорость считывания данных, что особенно важно для аналитики Big Data в режиме онлайн [3]. Похожий кейс с маркетинговой аналитикой больших данных мы описывали здесь, рассматривая применение Arenadata QuickMarts, основанной на ClickHouse, в Х5 Retail Group.
Другой реальный пример использования ClickHouse и Kafka для оперативной аналитики больших данных – это централизованная система сбора и обработки системных логов для оценки качества сервисов и ускорения реакции на скрытые проблемы при эксплуатации корпоративных ИТ-активов [4]. Также подобная связка может быть востребована в системах интернета вещей (Internet of Things, IIoT), особенно промышленного (Industrial IoT, IIoT), когда требуется в реальном времени анализировать различные показатели технологических процессов по множеству срезов.
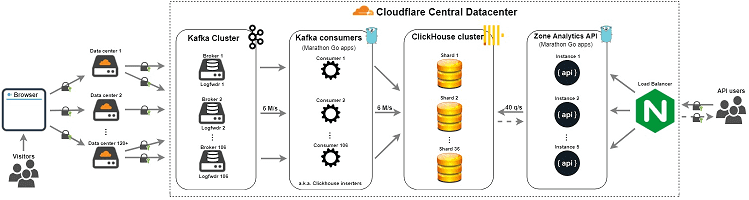
Интересен также опыт американской ИТ-компании Cloudflare, которая предоставляет услуги CDN, защиту от DDoS-атак, безопасный доступ к ресурсам и серверы DNS. На базе Apache Kafka и ClickHouse Cloudflare построила собственный конвейер данных для аналитики пользовательских логов и высокоскоростной обработки около 6 миллионов запросов в секунду [5].
В высоконагруженных Big Data проектах для обеспечения отказоустойчивости и масштабируемости ClickHouse разворачивается в кластерном режиме. Как и в случае Apache Kafka, для координации процесса репликации используется ZooKeeper [1]. Зачем Кафка использует Зукипер и можно ли обойтись без него, мы разбирали в этой статье. Напомним, Zookeeper выполняет роль координации распределенных сервисов, не обеспечивая передачу данных из одного источника в другой. За интеграцию Кликхаус с Кафка отвечают соответствующие средства, о которых мы поговорим далее.
Построение DWH на ClickHouse
Код курса
CLICH
Ближайшая дата курса
20 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Движок интеграции и материализованные представления таблиц Кафка
Связь ClickHouse с другими системами хранения и обработки данных обеспечивают специальные интеграционные движки (engines). В частности, движок Kafka позволяет публиковать потоки данных и подписываться на них, организовать отказоустойчивое хранилище и обрабатывать потоки по мере их появления через использование таблиц с указанием специальных параметров. Например, следующий код показывает заливку данных из топика Kafka в таблицу Кликхаус под названием queue (очередь) [6]:
CREATE TABLE queue (timestamp UInt64, level String, message String)
ENGINE = Kafka(‘localhost:9092’, ‘topic’, ‘group1’, ‘JSONEachRow’);
На практике стоит учитывать следующие ограничения встроенного движка для интеграции ClickHouse с Apache Kafka [6]:
- на один раздел (партицию) топика Кафка может быть назначен лишь один потребитель;
- общее число потребителей не должно превышать количество партиций в топике Кафка;
- в пределах одной группы сообщений каждое из них считывается только один раз, что реализует автоматическое отслеживание, но делает неэффективным применение запроса SELECT. Обойти это ограничение, чтобы организовать многократное чтение потока данных в реальном времени, позволяет специальная концепция ClickHouse — материализованное представление (MATERIALIZED VIEW).
Материализованное представление таблицы Kafka в ClickHouse позволяет СУБД непрерывно получать сообщения от Кафка в фоновом режиме. Преобразование данных с помощью SELECT в нужный формат выполняется следующим образом:
- поток данных реализуется через потребителя Kafka, созданного с помощью движка;
- материализованное представление преобразует данные от движка и помещает их в заранее созданную таблицу с нужной структурой;
Одна таблица Кафка в Кликхаус может иметь любое число материализованных представлений, поскольку они не считывают данные непосредственно, а блоками получают новые записи. Материализованные представления в ClickHouse не читают Kafka-таблицы, а получают данные от них при срабатывании триггера на INSERT. Поэтому одну Kafka-таблицу можно использовать как для сырых запросов, так и для агрегированных и сгруппированных данных по ним [4]. Благодаря этому данные можно записать в несколько таблиц с разным уровнем детализации. Пример программного кода будет выглядеть следующим образом [6]:
CREATE TABLE queue (timestamp UInt64, level String, message String)
ENGINE = Kafka('localhost:9092', 'topic', 'group1', 'JSONEachRow');
CREATE TABLE daily (day Date, level String, total UInt64)
ENGINE = SummingMergeTree(day, (day, level), 8192);
CREATE MATERIALIZED VIEW consumer TO daily
AS SELECT toDate(toDateTime(timestamp)) AS day, level, count() as total
FROM queue GROUP BY day, level;
SELECT level, sum(total) FROM daily GROUP BY level;
На практике интеграция ClickHouse с Kafka посредством встроенного движка не всегда проходит гладко. Завтра мы рассмотрим, какие проблемы могут при этом возникнуть и как их решить. А технические подробности по интеграции Apache Kafka с другими внешними источниками для потоковой обработки больших данных вы узнаете на практических курсах по Кафка в нашем лицензированном учебном центре повышения квалификации и обучения руководителей и ИТ-специалистов (разработчиков, архитекторов, инженеров и аналитиков Big Data) в Москве:
Источники
- https://ru.wikipedia.org/wiki/ClickHouse
- https://dou.ua/lenta/articles/experience-with-clickhouse/
- https://clickhouse.tech/docs/ru/single/#chto-takoe-clickhouse
- https://gon.gl/blog/2020/02/03/nginx-log-processing-with-clickhouse/
- https://blog.cloudflare.com/http-analytics-for-6m-requests-per-second-using-clickhouse/
- https://clickhouse.tech/docs/ru/engines/table-engines/integrations/kafka/#kafka

