
Запуская наш новый курс по Эксплуатация Apache NIFI, сегодня рассмотрим 3 популярных вопроса про этот Big Data фреймворк с комментариями компании Cloudera. Читайте далее, может ли NiFi заменить пакетные ETL-оркестраторы, как использовать REST API для управления потоками данных в этом фреймворке, а также где настраивать политики управления доступом в многопользовательской...

Сегодня в рамках обучения разработчиков распределенных приложений и дата-инженеров рассмотрим практический пример потоковой интеграции данных из 2-х разных источников с Apache Kafka. Читайте далее, как мгновенно передать данные между реляционными СУБД с помощью готовых JDBC-коннекторов через cURL-вызовы к REST API Kafka Connect. Apache Kafka как средство потоковой интеграции данных Интеграция...

Мы уже рассказывали, что приложения Kafka Streams используют RocksDB в качестве хранилища состояний. Сегодня рассмотрим, как это key-value NoSQL-СУБД используется для разработки stateful-приложений Apache Flink. Читайте далее о преимуществах и особенностях применения RocksDB для управления состоянием Flink-приложения, а также заблуждениях, связанных с этими фреймворками. 3 бэкенда Apache Flink для хранения...
Продвигая наши курсы по Apache Spark для разработчиков, сегодня рассмотрим пользовательские функции и особенности работы с ними в API SQL-модуле этого фреймворка. Читайте далее про идемпотентность UDF-функций и их влияние на распределение данных в кластере Apache Spark. Как устроены UDF в Apache Spark: краткий ликбез Пользовательские функции (User Defined Functions,...
Сегодня рассмотрим 2 важных понятия архитектуры распределенных систем для хранения и аналитики больших данных на примере платформы потоковой обработки событий Apache Kafka.Читайте далее, что такое согласованность и полнота, а также в чем преимущества строго однократной доставки сообщений на основе транзакционной записи и фиксации смещений в журналах, и как все это...
В рамках обучения разработчиков Apache Spark, сегодня рассмотрим еще несколько интересных особенностей этого фреймворка, ограничивающих его типовые возможности и на PySpark-примерах разберем, как с этим бороться. Читайте далее, что такое оконные функции и зачем они нужны, как сортировка влияет на фрейм окна в Spark SQL и чем опасны действия над...
Чтобы сделать наши курсы по Apache Spark еще более полезными, мы рассказываем о неочевидных тонкостях этого фреймворка, знание которых позволит разработчику распределенных приложений использовать возможности этой технологии более эффективно. Сегодня на практических примерах PySpark в API DataFrame рассмотрим разницу между функциями сортировки массивов и особенности объединения контенкации, а также разберемся...
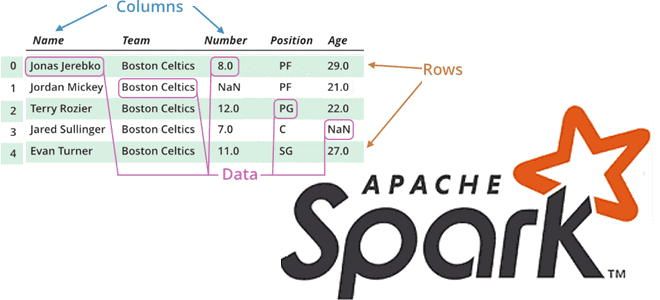
Продолжая разговор про вычислительные операции над датафреймами в Apache Spark, сегодня рассмотрим, какие преобразования (transformations) и действия (actions) чаще всего используются при разработке распределенных приложений и аналитике больших данных. Читайте далее, про виды столбцовых преобразования и отличия действия collect() от take(). Преобразования в Apache Spark: виды и особенности реализации Напомним,...
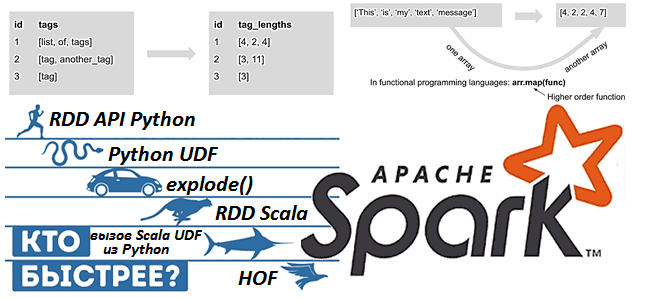
Apache Spark предоставляет для разработчика распределенных приложений множество возможностей, позволяя достигать одной целей разными способами. Чтобы проиллюстрировать это, сегодня рассмотрим бенчмаркинговое сравнение 9 методов обработки массивов в Spark 3.1, обращая внимание на их производительность и особенности использования. Также разберем важные для обучения разработчиков Spark темы про отличия преобразований от действий...

Сегодня рассмотрим пример построения системы потоковой аналитики больших данных на базе Apache Kafka, Spark, Flink, NoSQL-СУБД, BI-системой Tableau или визуализацией в Kibana. Читайте далее, кому и зачем исследовать Twitter-посты в реальном времени, как это реализовать технически, визуализировать в наглядных BI-дэшбордах для принятия data-driven решений и при чем здесь Kappa-архитектура. Еще...