Сегодня рассмотрим пример построения интеллектуальными конвейера потоковой обработки видео с Apache Kafka и алгоритмами машинного обучения. Читайте далее, зачем для этого нужен протокол RTSP, что такое библиотека Sarama и как интегрировать алгоритмы машинного/глубокого обучения в систему видеоаналитики реального времени. Потоковая видеоаналитика: прием мультимедиа в реальном времени Видеоаналитика – одно из...
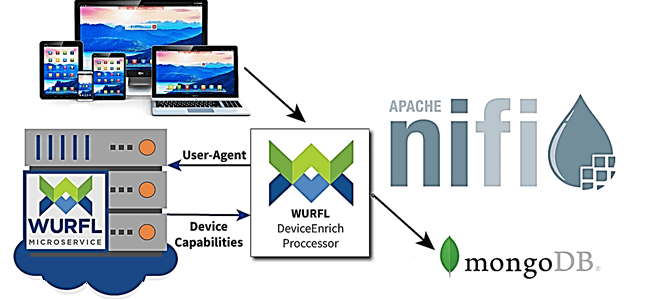
Развивая наши курсы по Apache NiFi для дата-инженеров и администраторов, сегодня рассмотрим, как как обогатить поток данных, сделав информацию об устройстве доступной для систем, которые хранят или потребляют данные в следующих этапах конвейера. Также разберем, зачем нужна технология детектирования устройств, что такое WURFL и как это реализовать в Apache NiFi....

В этой статье для дата-инженеров рассмотрим кейс компании PayPal, которая переводит свои аналитические рабочие нагрузки из локального кластера Apache Spark в Google Cloud Processing. Читайте далее, чем это решение оказалось лучше выполнения Spark-заданий в кластере DataProc с использованием данных BigQuery и облачного хранилища Google (GCS, Google Cloud Storage) для потоковой...

Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга....

Продвигая наш новый курс по графовым алгоритмам на больших данных, сегодня рассмотрим, почему концепция графов сегодня так востребована в Big Data и Machine Learning. Вас ждет краткий ликбез по модулю GraphX в Apache Spark и его отличия от API GraphFrames, а также особенности кластерной обработки и сохранения данных графа свойств....
Появившись более 10 лет назад, Apache Hive до сих пор является самым популярным инструментом стека SQL-on-Hadoop и активно используется для аналитики больших данных. Однако, технологии Big Data постоянно развиваются: Spark все чаще заменяет Hadoop MapReduce, а вместо HDFS все чаще используются объектные облачные хранилища: AWS S3, Delta Lake, Apache Ozone...

Недавно мы рассказывали про KafkaJS – клиент Apache Kafka для Node.js, который отличается небольшим размером и простым развертыванием с удобным API. Сегодня рассмотрим еще пару полезных инструментов визуализации данных о Kafka-кластере на базе KafkaJS и Prometheus. Читайте далее, что такое FlowKat и Monokl, а также зачем они нужны дата-инженеру, разработчику...
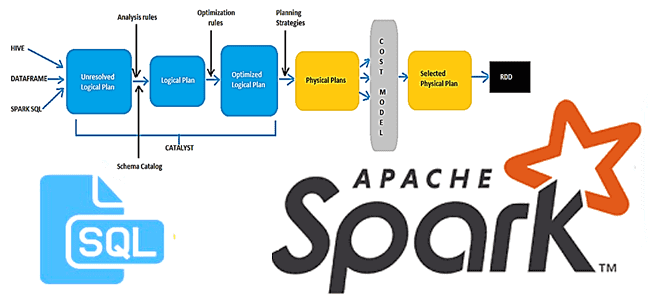
В этой статье для разработчиков Spark-приложений и дата-аналитиков рассмотрим новый оптимизатор этого фреймворка, Radiant. Он основан на SQL-оптимизаторе Catalyst и представляет собой open-source проект от энтузиастов сообщества Apache Spark. Читайте далее, чем хорош Spark-Radiant и как использовать его для оптимизации SQL-запросов при аналитике больших данных. Что такое SQL-оптимизатор Spark-Radiant и...
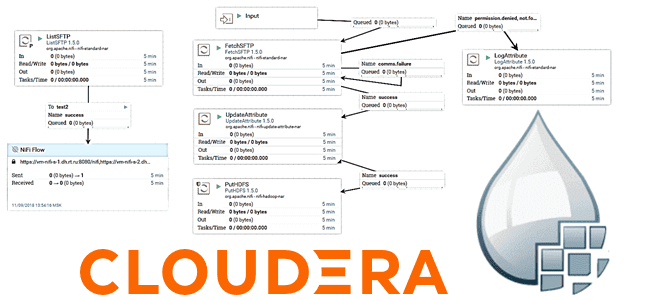
В рамках обучения дата-инженеров сегодня заглянем под капот системы Cloudera Flow Management, которая является частью платформы Cloudera DataFlow и основана на Apache NiFi. Вас ждет разбор основных концепций жизненного цикла потоковой разработки и их реализация в Apache NiFi с практическими примерами и рекомендациями по применению. Что такое Cloudera Flow Management...

Когда имеются графы (dags), зависимые от других, то лучше всего объединить их в один или использовать TaskGroup, о котором говорили в прошлой статье. Но если по каким-то причинам сделать это не удается, то Apache Airflow предоставляет различные способы запуска графа внутри другого. Одним из таких является TriggerDagRunOperator. В этой статье...