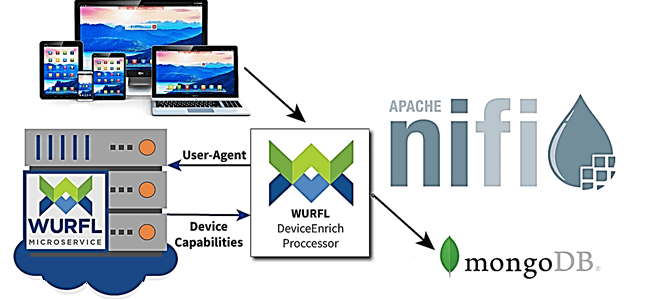
Развивая наши курсы по Apache NiFi для дата-инженеров и администраторов, сегодня рассмотрим, как как обогатить поток данных, сделав информацию об устройстве доступной для систем, которые хранят или потребляют данные в следующих этапах конвейера. Также разберем, зачем нужна технология детектирования устройств, что такое WURFL и как это реализовать в Apache NiFi.
Детектирование устройств: что это такое и зачем нужно
Начнем с краткого ликбеза по технологии детектирования устройств, которая позволяет сайтам создавать веб-страницу, оптимизированную для десктопного компьютера, смартфона или планшета, браузера и операционной системы, чтобы обеспечить удобство работы пользователей и повысить производительность интернет-ресурса. Сегодня одной из ведущих технологий определения устройств считается WURFL (Wireless Universal Resource FiLe) – набор проприетарных API-интерфейсов и XML-файл конфигурации, который содержит информацию о возможностях и функциях различных мобильных устройств. До версии 2.2 WURFL имел статус open-source проекта, а с июня 2011 года его код стал проприетарным. WURFL активно используется многими интернет-компаниями: Facebook, Google, Amazon, Akamai и пр [1].
Технология детектирования устройства анализирует строку пользовательского агента, отправленную браузером, чтобы определить устройство и приложение. Строки пользовательского агента обозначаются в стандарте HTTP и состоят из нескольких токенов, указывающих на программные и аппаратные характеристики устройства. Однако, правила создания пользовательских агентов не стандартизированы: разработчики браузеров и производители оборудования могут представлять информацию о браузере или устройстве в любом формате. Поэтому задача точного детектирования устройства достаточно сложна и требует много времени [2].
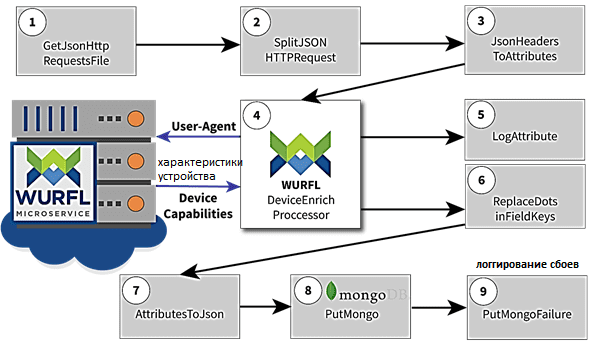
Если говорить о детектировании устройств в контексте потоковой аналитики больших данных и маршрутизации потоков с помощью Apache NiFi, то необходимо обрабатывать файлы данных, содержащие заголовки HTTP-запросов. Под обработкой понимается обогащение этих файлов информацией об устройстве с помощью WURFL, чтобы потом сохранить все в MongoDB. В Apache NiFi процесс будет выглядеть следующим образом [3]:
- загрузить файл в Apache NiFi;
- разделить содержимое файла на набор отдельных HTTP-запросов JSON;
- создать потоковый файл NiFi для каждого запроса и добавить заголовки HTTP в качестве атрибутов;
- добавить данные WURFL в каждый потоковый файл, используя процессор обогащения;
- преобразовать потоковый файл с новыми атрибутами в запись JSON;
- отправить запись JSON в коллекцию MongoDB, сохранив расширенные данные в лог-файле NiFi.
Реализация WURFL-обогащения в Apache NiFi
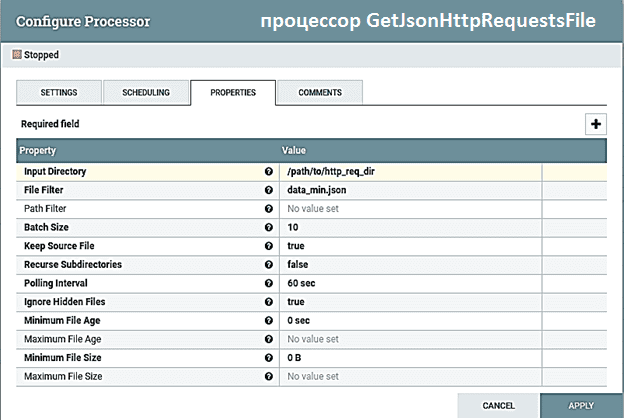
Каждое из вышеперечисленных действий выполняется с помощью соответствующего обработчика Apache NiFi – процессора. К примеру, процессор GetJsonHttpRequestsFile создает потоковый файл (FlowFile) и сохраняет в нем данные JSON. А процессор SplitJsonHttpRequest разделяет эти данные на набор потоковых файлов, каждый из которых содержит один HTTP-запрос в формате JSON. В свойстве JsonPathExpression устанавливается выражение пути JSON, которое разделяет объекты JSON на элементы в корневом каталоге файла.
Процессор JsonHeadersToAttributes берет объекты JSON из предыдущего процессора SplitJsonHttpRequest и преобразует их в набор атрибутов потокового файла, имя которых имеет префикс «http.headers». Причем в качестве исполнительного движка этой операции может быть указан один из языков программирования, который поддерживает Apache NiFi: Groovy, Python, Jython, Jruby, Ruby, Javascript, Lua, Luaj и Clojure.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
10 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
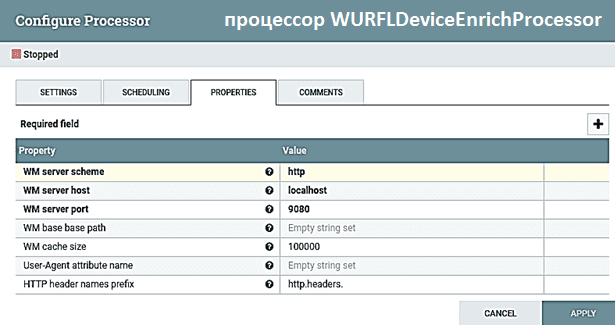
Процессор WURFLDeviceEnrich – является ключевым этапом потокового конвейера, где атрибуты FlowFile дополняются WURFL-сведениями об устройстве. Процессор WURFLDeviceEnrich использует экземпляр Java-клиента WURFL Microservice (WM) для выполнения своей логики обнаружения устройства, который следует предварительно настроить. Здесь следует отметить, что сервер микросервисов WURFL предоставляет свои функции API клиенту, который зависит от доступности WM-сервера для работы. При конфигурировании WURFL-процессора в Apache NiFi все параметры, имя которых начинается с префикса WM, являются параметрами инициализации WM-клиента: кроме кэша, все они должны относиться к работающему экземпляру сервера WURFL Microservice. Также должен быть установлен хотя бы один из имени атрибута User-Agent или префикса имен заголовков HTTP. Имя атрибута пользовательского агента User-Agent следует точно задавать, когда User-Agent является единственным HTTP-заголовком, доступным в атрибутах потокового файла. Но если имеется несколько заголовков HTTP, доступных как атрибуты FlowFile, нужно определить префикс их имен, например, http.headers. В результате WURFLDeviceEnrichProcessor загрузит все атрибуты, имя которых начинается с этого префикса. Этот подход распространен в NiFi, поскольку он позволяет обрабатывать различное количество заголовков HTTP без их точного указания.
Другие процессоры используют встроенный механизм NiFi – процессор HandleHttpRequest, который запускает HTTP-сервер и прослушивает HTTP-запросы, создавая для каждого запроса потоковый файл. Этот процессор предназначен для использования вместе с процессором HandleHttpResponse для создания веб-сервиса.
После завершения работы процессора WURFLDeviceEnrich данные переходят в процессор LogAttribute и в процессор ReplaceDotsInFieldKeys. LogAttribute просто записывает содержимое атрибутов FlowFile в стандартный лог-файл NiFi, находящийся в директории NIFI_HOME / logs / nifi-app.log. А успешно обработанные блоком WURFLDeviceEnrich попадают в процессор ReplaceDotsInFieldKeys, который заменяет все символы точек в именах атрибутов подчеркиванием, чтобы их можно было использовать в качестве имен полей для записей MongoDB, коллекции которых не принимают символы точек в именах полей.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
10 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
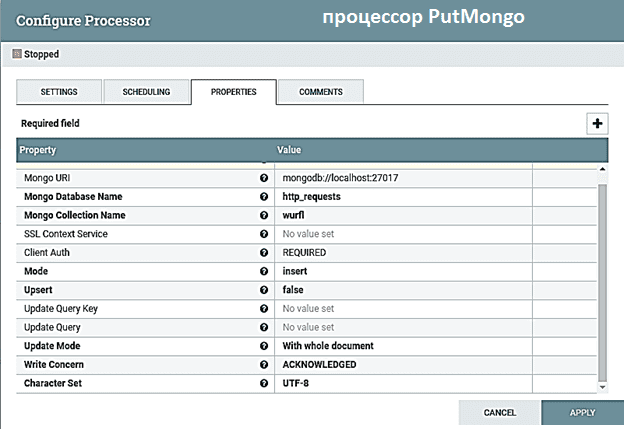
Далее процессор AttributesToJson преобразует набор атрибутов из FlowFile в сущность типа «ключ-значение», устанавливая JSON в поле содержимого потокового файла, чтобы добавить его в коллекцию MongoDB. Непосредственно за само добавление отвечает процессор PutMongo, который должен иметь информацию о параметрах подключения MongoDB, имени базы данных и коллекций. Причем, если последние не существуют, процессор сам создаст их. Доступ к экземпляру MongoDB через его графический интерфейс подтверждает, что все записи, содержащие заголовки HTTP-запросов и данные WURFL, были правильно загружены. Сбои будут логироваться процессором PutMongoFailure.
Больше практических примеров администрирования и использования Apache NiFi для современной дата-инженерии вы узнаете на специализированных курсах для разработчиков, ИТ-архитекторов, инженеров данных, администраторов, Data Scientist’ов и аналитиков Big Data в нашем лицензированном учебном центре обучения и повышения квалификации в Москве:
Источники
- https://en.wikipedia.org/wiki/WURFL
- https://www.devicedetection.com/
- https://www.scientiamobile.com/apache-nifi-data-flow-with-wurfl-device-enrich-processor/

