 717
717 
Содержание
Сегодня рассмотрим пример построения интеллектуальными конвейера потоковой обработки видео с Apache Kafka и алгоритмами машинного обучения. Читайте далее, зачем для этого нужен протокол RTSP, что такое библиотека Sarama и как интегрировать алгоритмы машинного/глубокого обучения в систему видеоаналитики реального времени.
Потоковая видеоаналитика: прием мультимедиа в реальном времени
Видеоаналитика – одно из наиболее востребованных приложений машинного обучения и технологий Big Data. Например, в ритейле активно используются системы слежения за товарами, помещениями, покупателями и продавцами. Подробнее о таких кейсах FMCG мы писали здесь и здесь. А кейс построения масштабируемого конвейера видеоаналитики в реальном времени с нейросетями YOLO на Apache Kafka, Spark Structured Streaming и Cassandra разбирали в этой статье.
Сейчас разберем подобный пример по созданию конвейер, который принимает видеопоток и делает его доступным для последующей обработки с применением алгоритмов Machine Learning: обнаружение лиц или классификация объектов.
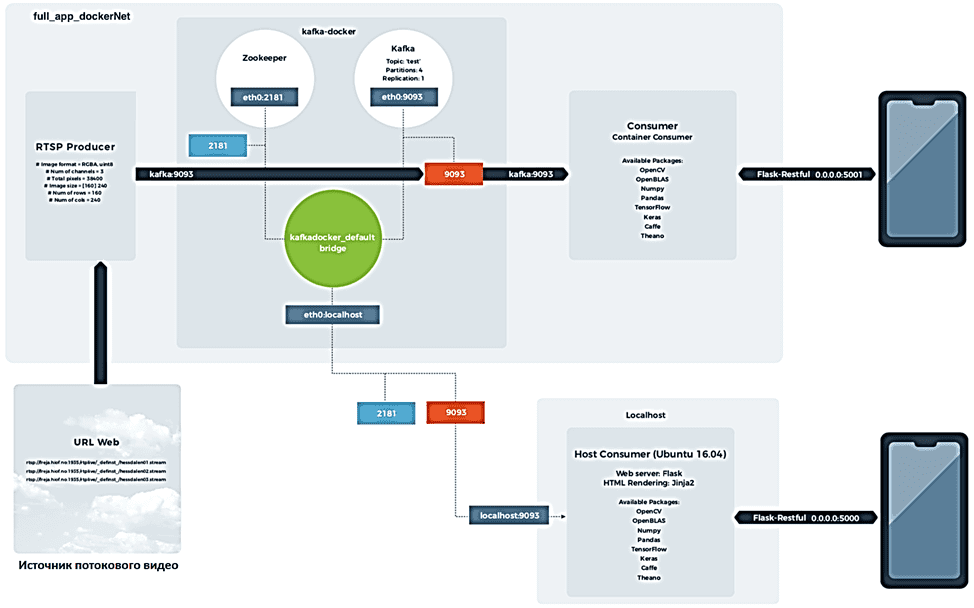
Предположим источником видео является некоторый стриминговый веб-сервис, видео с которого собирает Kafka-продюсер в реальном времени с использованием протокола RTSP [1]. RTSP (Real Time Streaming Protocol) — это прикладной потоковый протокол реального времени для мультимедийных систем, позволяющий удалённо управлять потоком данных с сервера с помощью команд запуска, паузы и остановки вещания мультимедийного содержимого. Также RTSP предоставляет доступ по времени к файлам на сервере, но не выполняет сжатие, а также не определяет метод инкапсуляции мультимедийных данных и транспортные протоколы. Передача потоковых данных сама по себе не является частью протокола RTSP, для этого большинство серверов используют стандартный транспортный протокол реального времени.
По синтаксису и операциям RTSP похож на HTTP, но с здесь возможность генерировать запросы есть как у сервера, так и у клиента. Например, видеосервер может послать запрос для установки параметров воспроизведения определенного видеопотока. Также в отличие от HTTP, RTSP предполагает, что управление состоянием или связью должен осуществлять сервер, а данные могут передаваться вне основной полосы (out of band) другими протоколами, например, RTP (Real-time Transport Protocol). Сами RTSP-сообщения посылаются отдельно от мультимедийного потока. В качестве клиентов RTSP моугт выступать как готовые приложения типа мультимедиа-проигрывателей (MPEG4IP, Winamp, VLC, Windows Mutimedia и пр.), так и собственный сервис [2].
Реализация потокового конвейера c Apache Kafka
В рассматриваемом кейсе его роль играет разработанный Kafka-продюсер. Используя поток URL-адресов продюсер, написанный на Go, отправляет данные в топик Kafka. При этом следует изменить размер изображения, чтобы конвейер не перегружался, а библиотека Sarama не генерировала исключение [1].
Напомним, пакет Sarama — это клиентская библиотека Go для работы с Apache Kafka от версии 0.8 и выше. Она включает высокоуровневый API для простого создания и использования сообщений и низкоуровневый API для управления байтами в сети, когда высокоуровневого API недостаточно. Для создания сообщений используется асинхронный (AsyncProducer) или синхронный (SyncProducer) продюсер. AsyncProducer принимает сообщения по каналу и создает их асинхронно в фоновом режиме с максимальной эффективностью, что подходит для большинства случаев. SyncProducer предоставляет метод отправки сообщений в топик, который будет блокировать поток до тех пор, пока Kafka не подтвердит создание сообщения. Обычно это менее эффективно, а фактические гарантии долговечности зависят от настроенного значения Producer.RequiredAcks. Существуют конфигурации, в которых сообщение, подтвержденное SyncProducer, иногда может быть потеряно. Для получения сообщений из топика Kafka в библиотеке Sarama есть API потребителя (Consumer) и группы потребителей (Consumer-Group).
Для более низкого уровня объекты Broker и Request/Response позволяют точно контролировать каждое соединение и сообщение, отправленное по сети. А клиент обеспечивает управление метаданными более высокого уровня, которые совместно используются продюсерами и потребителями [3].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
В рассматриваемом примере будет 2 потребителя [1]:
- один работает внутри контейнерной сети, взаимодействуя с каналом Kafka;
- другой предназначен для запуска с локального хоста, обращающегося к каналу Kafka через localhost: 9092.
В обоих случаях можно сгенерировать Docker-образ и локальную среду с одними и теми же пакетами, включая популярные фреймворки компьютерного зрения и ML/DL-библиотеки, например, OpenCV, TenforFlow, Keras, Theano и Caffe. Можно также добавить собственные алгоритмы машинного или глубокого обучения, имея прямой доступ к пикселям изображения.
Программный код рассматриваемого примера приведен в источнике [4] и доступен для свободного скачивания с Github.
Освойте все тонкости администрирования и эксплуатации Apache Kafka для разработки распределенных приложений потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

