 1157
1157 
Сегодня рассмотрим пару кейсов по использованию Apache Flink в качестве основного фреймворка пакетной и потоковой аналитики больших данных. Читайте далее, как фото-хостинг Pinterest построил вокруг Flink собственную инфраструктуру работы с изображениями в реальном времени, а китайский ритейл-гигант Alibaba Group успешно обрабатывал 7 ТБ в секунду во время глобального дня шопинга.
Кейс фотохостинга Pinterest
Соцсеть Pinterest представляет собой платформу для размещения и шеринга фотографий и других изображений с почти 500 миллионами пользователей. В качестве движка потоковой обработки данных Pinterest использует Apache Flink, который предоставляет богатые API-интерфейсы потоковой передачи, поддерживает семантику строго-однократной доставки (exactly once) и механизм контрольных точек для stateful-приложений (state checkpointing), чтобы обеспечить их стабильную работу и масштабирование. В частности, на основе Flink сотрудники Pinterest разработали собственную платформу обработки потокового видео – Xenon, которая поддерживает следующие критически важные сценариев использования [1]:
- показ рекламы в реальном времени, расчет расходов с учетом ограничений бюджета и формирование отчетности для рекламодателей;
- быстрый анализ контента после его создания и использование результатов в конвейерах машинного обучения для индивидуального взаимодействия с пользователем, включая идентификацию небезопасного контента и оперативное распространение данных по потенциальным заинтересованным потребителям;
- обновление метаданных продуктов в реальном времени;
- передача метрик ML-инженерам для более точной настройки, проверки и оценки экспериментов.
Совместно с Apache Flink в Pinterest используются следующие технологии для потоковой аналитики больших данных [2]:
- Apache Kafka и AWS S3 как средства хранения и способы доступа к наборам данных;
- встроенный NRTG-компилятор для ускорения разработки и обеспечения согласованности с пакетной реализацией;
- Finagle – расширяемая RPC-система для JVM, позволяющая создавать высокопроизводительные сервера с высоким уровнем параллелизма, включая реализацию унифицированных клиентских и серверных API независимо от протокола;
- Apache ZooKeeper для достижения высокой доступности работы в единой зоне доступности;
- встроенный сервис управления заданиями для запуска развертывания приложений, автоматического восстановления после сбоя и переключения зоны доступности при отказе;
- CI-система поверх Spinnaker для масштабного регрессионного тестирования;
- Hive Metastore для хранения логических таблиц Flink SQL.
Подробнее о том, как Apache Flink и Kafka используются в Pinterest, читайте в нашей новой статье.
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
25 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Apache Flink в Alibaba Group
11 ноября 2020 года, во всемирный день шопинга, китайский мега-ритейлер Alibaba Group обрабатывал 7 ТБ в секунду на пике пользовательских запросов с помощью потоково-пакетной технологии на без Apache Flink. Помимо интерактивных дэшбордов о важных бизнес-показателях, Flink также обеспечивал поддержку машинного обучения в реальном времени для поиска и формирования рекомендаций, борьбу с мошенничеством, реклама мониторинг статуса заказов, обнаружение атак и многое другое. Пиковая скорость вычислений в реальном времени достигла четырех миллиардов записей в секунду. Размер кластера Apache Flink стал крупнейшим в мире, составив более 1,5 миллиона процессоров.
Вообще унификация потоково-пакетной обработки с Flink в основных сценариях Alibaba началась несколько лет назад. Сперва Flink использовался для поиска и формирования рекомендаций в реальном времени. Далее эти кейсы были расширены, чтобы достичь более точного анализа данных и принятия бизнес-решений путем перекрестной онлайн-проверки метрик с историческими данными.
Например, можно сравнить результаты крупных рекламных акций в разные периоды текущего дня со вчерашними показателями, чтобы определить эффективность маркетинга и необходимость запуска дополнительных мероприятий. В этом сценарии требуются два вида отчетов об аналитике данных: автономный суточный отчет с данными пакетной обработки и отчет с данными в реальном времени. Без унификации потоковой и пакетной обработки на базе Apache Flink эти отчеты требовалось создавать с помощью отдельных пакетных и потоковых движков, что удваивает затраты на разработку, накладные расходы на обслуживание, согласование логики обработки и консистентности (целостности и согласованности) данных.
Использование единого механизма потоковой и пакетной обработки для анализа данных естественным образом обеспечивает согласованность. В результате объединения потоков и пакетов для нескольких режимов обработки вычислений нужен только один набор кода. Причем с Apache Flink скорость вычислений в два раза выше, чем у других фреймворков, а запросы выполняются в 4 раза быстрее. Помимо повышения эффективности бизнеса и производительности вычислений, унифицированная архитектура потоковых и пакетных вычислений улучшает утилизацию ресурсов кластера. Кластер Apache Flink в Alibaba содержит миллионы процессоров, на которых выполняются десятки тысяч вычислительных задач в реальном времени. А ночью свободные вычислительные ресурсы используются для автономной пакетной обработки без дополнительных затрат.
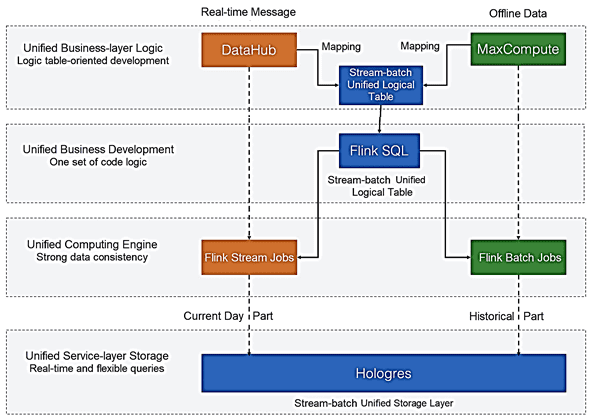
Полная унификация потоковой и пакетной архитектуры Flink достигнута с помощью SQL-модуля этого фреймворка, богатый API которого позволяет пользователям работать только с одним набором операторов, снижает затраты на разработку. В частности, после отправки задания потоковой передачи пользователи создают другое пакетное задание для воспроизведения исторических данных. Хотя DataStream может эффективно удовлетворить различные требования сценариев потоковых вычислений, его поддержка пакетной обработки может быть расширена. Поэтому начиная с версии Flink 1.11, в API DataStream добавлена семантика пакетной обработки. Теперь, применяя унифицированную концепцию пакетной и потоковой обработки к дизайну коннекторов, Flink может соединять API DataStream с различными типами источников данных, от Kafka до HDFS.
С функциональной точки зрения Apache Flink по-прежнему представляет собой комбинацию потоковых и пакетных вычислений с использованием SQL и API-интерфейсов DataStream. Код пользователя выполняется в потоковом или в пакетном режиме, включая автоматическое переключение между ними потоковыми и пакетными вычислениями. Например, при интеграции данных из СУБД с озером данных (Data Lake) полный набор данных в СУБД следует сначала синхронизировать с HDFS или облачными службами хранения, а затем автоматически синхронизировать инкрементные данные в базе данных. При такой синхронизации выполняется единая потоковая и пакетная обработка ETL. В перспективе Apache Flink будет поддерживать больше интеллектуальных сценариев объединения потоков и пакетов.

В случае Alibaba Group унификация потоковой и пакетной обработки с Apache Flink показало отличные результаты в основной системе принятия маркетинговых решений Tmall, а также успешно завершило процессы индексирования и машинного обучения в сценариях поиска и формирования рекомендаций. О новинках свежего релиза Apache Flink, выпущенного в сентябре 2021 года, читайте в нашей новой статье.
В заключение отметим, что аналогичными возможностями Flink также обладает другой Big Data фреймворк — Apache Spark, который также имеет SQL-модуль и средства пакетной и потоковой обработки данных практически в реальном времени. Разобраться с ним на практике, а также освоить другие особенности разработки распределенных приложений аналитики больших данных с Apache Spark, Flink и другими компонентами экосистемы Hadoop, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Hadoop для инженеров данных
Источники
- https://medium.com/pinterest-engineering/unified-flink-source-at-pinterest-streaming-data-processing-c9d4e89f2ed6
- https://www.ververica.com/blog/the-apache-flink-story-at-pinterest-flink-forward-global-2021
- https://www.ververica.com/blog/apache-flinks-stream-batch-unification-powers-alibabas-11.11-in-2020

