Сегодня заглянем под капот особых операторов Apache AirFlow, разберемся с режимами работы датчиков, а также рассмотрим, как создать собственный сенсор. Краткий ликбез по разработке своего sensor’а с лучшими практиками настройки и использования в DAG’ах AirFlow. Что такое сенсор: краткий ликбез по AirFlow Сенсоры или датчики AirFlow — это особый тип...
Вчера мы писали о недавно вышедшем свежем релизе Apache Kafka 3.1.0, который вышел в январе 2022 года. Сегодня рассмотрим, как безболезненно перейти на эту версию и избежать возможных побочных эффектов, связанных с некоторыми архитектурными изменениями платформы. Побочные эффекты и подводные камни обновления Напомним, в Apache Kafka 3.1.0 добавлена новая фича...

24 января 2022 года вышел новый релиз Apache Kafka. Главные новинки самой последней на сегодня стабильной версии 3.1.0: добавленные фичи, улучшения и исправленные баги краткий обзор для разработчиков распределенных приложений Kafka Streams и администраторов кластера этой платформы потоковой передачи событий. Новинки Apache Kafka 3.1.0 для администратора кластера В свежем релизе...
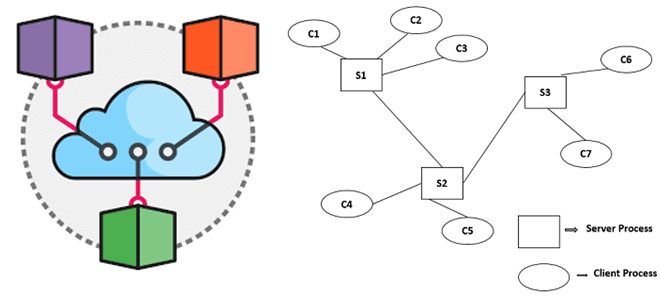
Недавно мы писали про архитектурный шаблон CQRS и его реализацию на базе Apache Kafka. В продолжение этой темы для обучения ИТ-архитекторов и разработчиков Big Data приложений, сегодня рассмотрим еще несколько популярных шаблонов проектирования распределенных систем: достоинства, недостатки, примеры реализации и способы их использования. Шаблоны проектирования распределенных систем: что это и...

Развивая наши курсы по Apache Spark и AirFlow для дата-инженеров и администраторов кластеров, сегодня рассмотрим кейс крупного маркетплейса Joom по переходу от 2-ой версии фреймворка на облачной платформе EMR к развертыванию сотен распределенных заданий на 3-ей версии в Amazon Elastic Kubernetes Service. Про сокращение расходов, повышение производительности и апдейт вычислительных движков. Постановка...
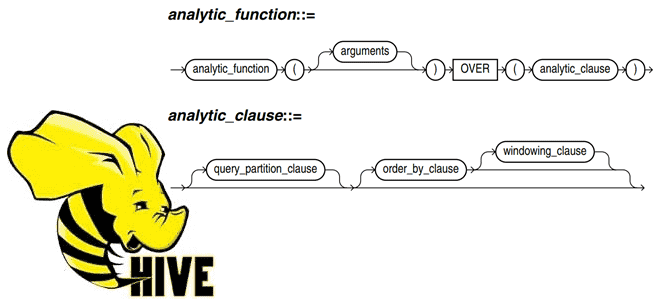
Постоянно добавляя в наши курсы по SQL-on-Hadoop для дата-инженеров и разработчиков распределенных приложений интересные примеры, сегодня рассмотрим пару практических техник по работе с Apache Hive. Читайте далее, как автоматически пронумеровать строки Hive-таблицы, исключив дубликаты в последовательности, и чем аналитическая функция row_number() отличается от rank() с dense_rank(). Генерация порядкового номера строки...

Недавно на примере ИТ-компании Salesforce мы рассказывали про вторичную индексацию таблиц Apache HBase с помощью Phoenix – средства обращения к NoSQL-хранилищу через SQL-запросы. В продолжение этого кейса, сегодня рассмотрим, как были перепроектированы глобальные вторичные индексы для обеспечения более высокого уровня согласованности, чем предлагает Apache Phoenix. Реализация вторичных индексов в таблицах...
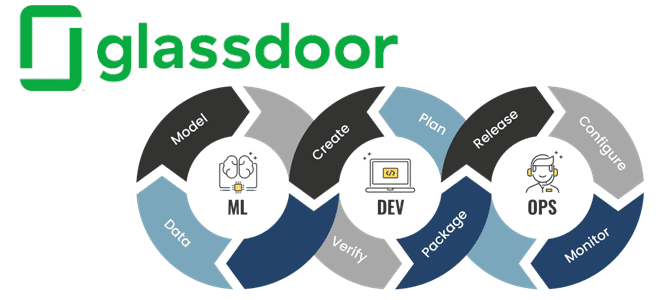
Практическая реализация MLOps-концепции на примере международной рекрутинговой компании Glassdoor. Как построить самоуправляемую автоматизированную систему разработки и сопровождения ML-моделей с MLFlow, Apache Spark и AirFlow, Kubernetes, GitLab, SageMaker Feature Store, Whylogs, Jenkins, Spinnaker и Prometheus с Grafana. Предыстория: зачем MLOps в Glassdoor Glassdoor с 2008 года помогает соискателям по всему миру...

Чтобы сделать наши курсы по Apache Spark еще более полезными, сегодня разберем 2 варианта решения типовой задачи инженерии данных. Как быстро и эффективно считать данные из множества CSV-файлов с одинаковой схемой за несколько строк кода на PySpark. Постановка задачи: рутинная работа с CSV-файлами Наряду с JSON-файлами, про которые мы писали...
Сегодня обсудим ключевые тренды развития дата-инженерии и инструментальные средства их реализации. Как это применяется на практике, рассмотрим на примере эволюции хранилища данных в индонезийской ИТ-компании Bukalapak, от локального кластера Apache HBase до Лямбда-архитектуры в облаке Google Cloud Platform с Kafka, Spark и AirFlow. 7 главных драйверов развития дата-инженерии В наши...