
Сегодня поговорим про администрирование кластера Apache Kafka и разработку потоковых приложений передачи и разберем, как обеспечить их работу в бессерверном режиме с платформой Upstash. Финансовая экономия, простота сопровождения и другие преимущества FaaS-сервисов и serverless-подхода с RESTfull API для обработки событий в реальном времени. Снова про serverless: что такое Upstash Kafka...
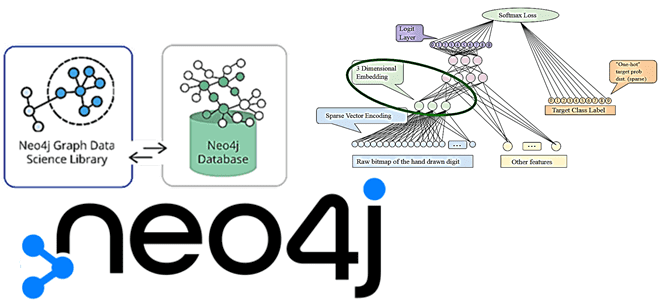
В рамках нашего нового курса графовым алгоритмам в бизнес-приложениях, сегодня разберем эмбеддинг-алгоритмы в библиотеке Graph Data Science СУБД Neo4j: их особенности и возможности практического использования для задач обработки естественного языка (NLP). Также рассмотрим, чем FastRP отличается от GraphSAGE с Node2Vec. NLP, эмбеддинги и Graph Data Science В обработке естественного языка...

Что такое Hive Transform, зачем это нужно дата-инженеру и разработчику распределенных приложений, где и как использовать эту функцию популярного средства SQL-on-Hadoop. Краткий обзор альтернативного способа операций с данными в Apache Hive, его возможности и ограничения, а также связь с HiveQL. Преобразования в Apache Hive Apache Hive – это популярная экосистема...

В рамках обучения дата-инженеров и ML-специалистов лучшим практикам MLOps, сегодня рассмотрим практический пример построения конвейера машинного обучения на Airflow, MLFlow, SageMaker и других сервисах Amazon. А также как Apache Spark версии 3 сократил расходы на облачный EMR-кластер почти в 2 раза. MLOps с AirFlow и MLFlow в облаке AWS Ранее...

В октябре прошлого года вышел крупный релиз Apache AirFlow 2.2.0. Разбираем его главные фичи, которые больше всего интересны с точки зрения инженерии данных: пользовательские расписания и декораторы, отложенные задачи, а также валидация параметров DAG по JSON-схеме. Краткий обзор обновлений AirFlow 2.2.0 Хотя последней версией популярного batch-планировщика задач Apache Airflow на...
Мы уже рассматривали особенности обработки вложенных структур данных на примере парсинга JSON-файлов с Apache Spark и Hive. Развивая эту тему, сегодня поговорим про перенос записей с вложенными массивами из топиков Apache Kafka в реляционные СУБД с пользовательскими SMT-преобразователями и JDBC-коннектором: кейс для разработчиков. Проблемы обработки сложных структур данных с JDBC-коннектором...
Сегодня рассмотрим, как использовать статистический язык R для анализа данных в Greenplum. Что такое GreenplumR, как работает этот интерактивный клиент, чем он полезен специалисту по Data Science и каковы недостатки этого инструмента аналитики больших данных. Что такое GreenplumR Хотя основным языком в области Data Science сегодня считается Python, иногда специалисты...

В рамках нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим популярную сегодня тему про невзаимозаменяемые токены в криптовалютах и не только. Пример анализа графа по NFT-транзакциям в графовой СУБД Neo4j с помощью инструкций языка запросов Cypher. Что такое NFT и причем здесь блокчейн с криптовалютами Уникальный или невзаимозаменяемый...

Недавно мы писали про декабрьский релиз Apache NiFi. Спустя месяц, 18 января 2022 года сообщество выпустило новую версию фреймворка – 1.15.3 с аутентифицированным доступом к SFTP-серверам через прокси-серверы SOCKS и улучшенным потреблением памяти. Разбираем 9 исправленных багов и 2 улучшения, а также особенности миграции на свежий выпуск. Снова про библиотеки...

В этой статье для дата-инженеров и аналитиков рассмотрим пример мониторинга состояния электрогенераторов с помощью анализа данных временных рядов и ранжирования в pandas для предупреждения выхода оборудования из строя. А также разберем основы анализа временных рядов на больших данных с открытой библиотекой Flint для Apache Spark. Постановка задачи: температура и производительность...