
Недавно мы рассматривали производительность ETL-конвейеров на Apache Spark с озером данных на MinIO. Сегодня разберем, чем это легковесное объектное хранилище отличается от распределенной файловой системы Apache Hadoop и как перейти на него с HDFS. Зачем переходить на MinIO Хотя HDFS до сих пор активно используется во многих Big Data проектах...

В связи с активным переходом от локальной ИТ-инфраструктуры в облачные полностью управляемые сервисы многие ИТ-архитекторы и дата-инженеры задумываются о замене собственного кластера Apache Kafka ее Cloud-альтернативами. Читайте, что общего у Apache Kafka с AWS Kinesis, чем они отличаются и какую платформу выбрать для потоковой передачи событий. Потоковая обработка событий с...

Чтобы добавить в наши практические курсы по Apache Spark еще больше приемов, полезных для дата-инженеров и разработчиков, сегодня рассмотрим, как упаковать PySpark-приложение, используя нативные Python-функции и сторонние решения. Отличия Virtualenv от PEX и Conda. 4 способа упаковать PySpark-приложение для запуска в кластере Apache Spark Разработчики распределенных приложений знают, что недостаточно...
В этой статье для обучения дата-инженеров и администраторов кластера разберем способы организации совместного использования DAG-файлов при развертывании Apache AirFlow в Kubernetes. Чем хорош вариант с общими томами и почему от него лучше отказаться в пользу Git. Как организовать обмен DAG-файлами в Apache AirFlow на Kubernetes Развертывание Apache AirFlow в кластере...
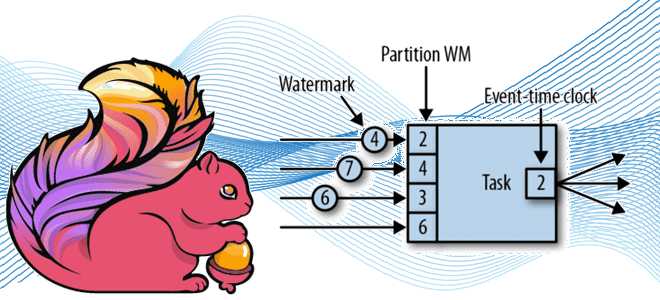
Продолжая разговор про оконные операции в Apache Flink для потоковой аналитики больших данных, сегодня рассмотрим, как это связано с другим важным концептом потоковой обработки событий – водяным знаком. Что такое Watermark и каковы стратегии его генерации в Apache Flink: самое главное для дата-инженера. Потоковая синхронизация данных c SQL для Flink...
Продвигая наш новый курс по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем особенности работы оператора MERGE во встроенном SQL-подобном языке запросов Cypher популярной NoSQL-СУБД Neo4j. Чем он отличается от запросов CREATE и MATCH, а также когда этот оператор более всего полезен. Как работает MERGE-запрос в Neo4j Data Scientist’ы и аналитики данных знают,...
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения. Архитектурный дизайн Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности...

Сегодня рассмотрим пример построения гибридной архитектуры LakeHouse c Apache Kafka и Snowflake, которая гарантирует высокую масштабируемость и обеспечивает безопасность данных от несанкционированного доступа с помощью маскирования. От пакетного озера данных на AWS S3 к потоковому LakeHouse Будучи высоконадежной распределенной платформой потоковой передачи событий, Apache Kafka часто используется для обработки потока...
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark. Что такое...
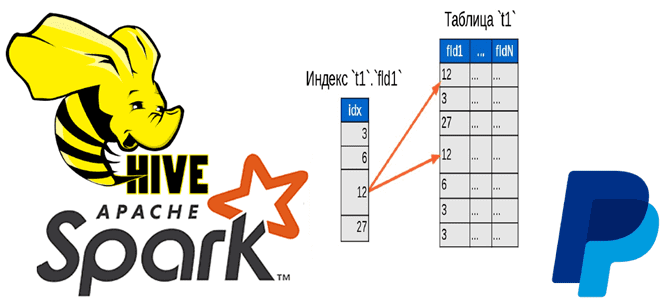
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро. Трудности бакетирования в Hive и Spark Вычислительный движок Apache Spark отлично...