 1136
1136 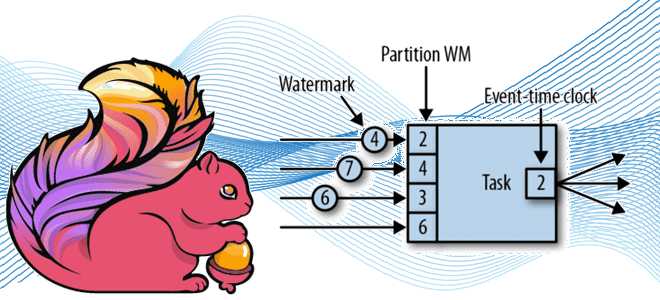
Продолжая разговор про оконные операции в Apache Flink для потоковой аналитики больших данных, сегодня рассмотрим, как это связано с другим важным концептом потоковой обработки событий – водяным знаком. Что такое Watermark и каковы стратегии его генерации в Apache Flink: самое главное для дата-инженера.
Потоковая синхронизация данных c SQL для Flink и Spark
Напомним, в потоковой обработке данных окно разбивает поток на конечные сегменты, над которыми выполняются вычисления. Окно создается, как только появляется первый элемент, который должен принадлежать ему, и полностью удаляется, когда время события или обработки проходит отметку окончания плюс заданное пользователем допустимое время задержки (AllowedLateness). Какие бывают окна, и чем они отличаются друг от друга, мы подробно рассматривали здесь.
Сам процесс обработки потоковых данных в Apache Flink строится так:
- сперва помечается водяным знаком каждое событие, поступающее из потокового источника данных, например, топика Apache Kafka, что мы разбираем здесь;
- временная метка извлекается из входящего события и преобразуется в миллисекунды;
- поток данных преобразуется в ключевой, куда помещается оконный оператор. Если нужно работать со временем события, а не временем обработки данных, рекомендуется использовать функцию кувыркающегося окна TumblingEventTimeWindows().
Функция keyBy(…) разделит бесконечный поток на потоки с логическими ключами. В качестве ключа может использоваться любой атрибут входящих событий. Наличие ключа в потоке позволит оконным вычислениям выполняться параллельно несколькими независимыми задачами. Все элементы, относящиеся к одному и тому же ключу, будут отправлены в одну и ту же параллельную задачу. Без использования ключа исходный поток не будет разделен на несколько логических потоков, и вся оконная логика будет выполняться одной задачей, то есть с параллелизмом 1.
Перед использованием оконного оператора исходному потоку требуется WatermarkStrategy – стратегия назначения водяного знака. Watermark или водяной знак — это метод измерения хода события во времени. Со временем события каждое входное событие имеет встроенную временную метку. Эта временная метка может использоваться для водяных знаков, чтобы указать оператору время поступления событий. Можно сказать, что водяной знак — это глобальная метрика прогресса, которая указывает момент времени, когда больше не будет поступать отложенных событий. По сути, водяные знаки представляют собой логические часы, которые информируют систему о текущем времени события. Водяные знаки должны монотонно возрастать, чтобы гарантировать, что часы событий задач идут вперед, а не назад. Также они связаны с отметками времени записи. Водяной знак с временной меткой T указывает, что все последующие записи должны иметь временные метки > T. Во Flink водяные знаки реализованы в виде специальных записей, содержащих отметку времени в виде длинного значения. Водяные знаки текут в потоке обычных записей с аннотированными отметками времени.
Чтобы работать со временем события, Flink должен знать временные метки событий, то есть каждому элементу в потоке должна быть назначена временная метка события (timestamp). Обычно это делается путем извлечения временной метки из некоторого поля в элементе с помощью TimestampAssigner. А функция withTimestampAssigner() извлекает значение метки времени, встроенное в тело события. Метки времени, как и водяные знаки, указаны в миллисекундах с эпохи Java 1970–01–01T00:00:00Z.
Отметка времени в записи связывает ее с определенным моментом времени, обычно моментом времени, когда произошло событие, представленное записью. Когда задача получает запись, которая нарушает свойство водяного знака и имеет меньшие временные метки, чем ранее полученный водяной знак, может оказаться, что вычисление, к которому она относится, уже завершено. Такие записи называются поздними записями.
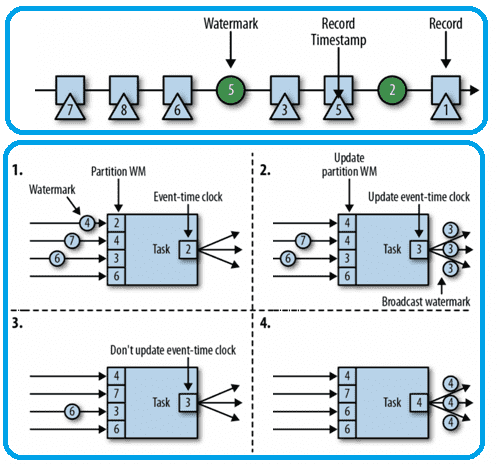
Очень разреженные водяные знаки увеличивают задержку обработки, но улучшают полноту результатов, в то время как водяные знаки с небольшим интервалом обеспечивают низкую задержку обработки. Flink реализует водяные знаки в виде специальных записей, получаемых и выдаваемых операторскими задачами. Задачи имеют внутреннюю службу времени (часы времени событий), которая поддерживает таймеры и активируется при получении водяного знака.
Таким образом, назначение метки времени сопутствует с созданием водяных знаков, которые сообщают системе о прогрессе во времени события согласно настройкам WatermarkGenerator. Flink API ожидает WatermarkStrategy, который содержит TimestampAssigner и WatermarkGenerator. Как правило, операторы должны полностью обработать заданный водяной знак, прежде чем пересылать его дальше по конвейеру. Например, WindowOperator сначала оценит все окна, которые должны быть запущены, и только после создания всех выходных данных, вызванных водяным знаком, сам водяной знак будет отправлен далее. Другими словами, все элементы, созданные из-за появления водяного знака, будут испускаться перед водяным знаком. Аналогичное применяется к TwoInputStreamOperator, но в этом случае текущий водяной знак оператора определяется как минимум от обоих его входов.
Ряд общих стратегий доступен в виде статических методов в WatermarkStrategy, но при необходимости разработчик может создать собственную стратегию. По умолчанию в Apache Flink есть два генератора водяных знаков:
- forMonotonousTimestamps() — используется, когда известно, что поступающие события всегда будут приходить по порядку;
- forBoundedOutOfOrderness() — используется, если известно, что события происходят не по порядку и допускается определенная степень задержки. Это значение может быть установлено в минутах, секундах или миллисекундах, которое разрешает события после сравнения с текущей меткой времени. Когда событие выходит за пределы временных рамок установленной задержки, оно удаляется из потока, если только значение AllowLateness не задано выше этой задержки. Функция AllowLateness() позволяет обрабатывать события, которые могут выйти за пределы, установленные с помощью forBoundedOutOfOrderness(), т.е. работать с событиями, которые пришли с опозданием, но в отдельном окне.
Особенности работы разных стратегий генерации водяных знаков в Apache Flink мы рассмотрим далее.
Как работает WatermarkStrategy
Во Flink-приложениях WatermarkStrategy можно использовать непосредственно в источниках данных и после операции без источника. Первый вариант предпочтительнее, потому что он позволяет источникам использовать знания о разделах в логике водяных знаков. Источники могут отслеживать водяные знаки на более точном уровне. Указание WatermarkStrategy непосредственно в источнике обычно означает, что разработчик должен использовать интерфейс, зависящий от источника. Второй вариант установка WatermarkStrategy после произвольных операций следует применять только в том случае, если вы невозможно установить стратегию генерации водяных знаков непосредственно на источнике данных. Следующий пример кода на Java показывает применение рассмотренных функций.
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<MyEvent> stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo);
DataStream<MyEvent> withTimestampsAndWatermarks = stream
.filter( event -> event.severity() == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>);
withTimestampsAndWatermarks
.keyBy( (event) -> event.getGroup() )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
Использование WatermarkStrategy таким образом берет исходный поток и создает новый с элементами с отметками времени и водяными знаками. Если в исходном потоке уже были временные метки и водяные знаки, средство назначения временных меток перезаписывает их.
API DataStream может назначать метки времени и создавать водяные знаки для потока тремя способами:
- в источнике с помощью функции SourceFunction, когда поток поступает в приложение. Эта функция создает поток записей, которые могут создаваться вместе с соответствующей отметкой времени. А водяные знаки могут создаваться в любой момент времени в виде специальных записей. Если SourceFunction больше не генерирует водяные знаки, она может объявить себя бездействующей.
- периодически с помощью UDF-функции AssignerWithPeriodicWatermarks(), которая извлекает метку времени из каждой записи и периодически запрашивает текущий водяной знак. Извлеченные временные метки назначаются соответствующей записи, а запрошенные водяные знаки загружаются в поток.
- Постоянно с помощью UDF-функции AssignerWithPunctuatedWatermarks(), которая извлекает метку времени из каждой записи. Его можно использовать для создания водяных знаков, которые закодированы в специальных входных записях. В отличие от AssignerWithPeriodicWatermarks(), эта функция может извлекать водяной знак из каждой записи.
Если один из входных разделов какое-то время не несет событий, это означает, что WatermarkGenerator также не получает никакой новой информации, на которой можно основывать водяной знак. Это называется холостым источником и становится проблемой, т.к. некоторые из разделов все еще содержат события. В этом случае водяной знак будет задержан, потому что он вычисляется как минимум по всем различным параллельным водяным знакам. Обойти это поможет WatermarkStrategy, который обнаружит бездействие и пометит вход как бездействующий:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
С другой стороны, раздел или источник могут обрабатывать записи очень быстро и увеличивать водяной знак отдельного потока быстрее других. Это может стать проблемой для нижестоящих операторов, использующих водяные знаки для передачи некоторых данных. В этом случае водяной знак такого нижестоящего оператора, например, оконные соединения на агрегациях, будет расти. Но оператору придется буферизовать чрезмерное количество данных, поступающих от быстрых источников, поскольку минимальный водяной знак из всех его входных данных удерживается запаздывающим вводом. Поэтому все записи, выдаваемые быстрым вводом, должны быть буферизированы в указанном нижестоящем состоянии оператора, что может привести к его неконтролируемому росту. Решить эту проблему поможет выравнивание водяных знаков. Оно гарантирует, что никакие источники и разделы не будут увеличивать свои водяные знаки слишком сильно по сравнению с остальными. Можно включить выравнивание для каждого источника отдельно:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withWatermarkAlignment("alignment-group-1", Duration.ofSeconds(20), Duration.ofSeconds(1));
При включении выравнивания необходимо указать Flink, к какой группе должен принадлежать источник. Для этого следует предоставить метку, например, группа выравнивания-1, которая связывает вместе все источники с этой меткой. Также надо указать максимальное отклонение от текущих минимальных водяных знаков по всем источникам, принадлежащим к этой группе. Третий параметр описывает, как часто должен обновляться текущий максимальный водяной знак. Недостатком частых обновлений является большое количество сообщений через RPC-вызовы. Чтобы добиться выравнивания, Flink приостановит потребление из источника или задачи, которая создала опережающий водяной знак. Но продолжается чтение записей из других источников и задач, которые могут переместить комбинированный водяной знак вперед и разблокировать быстрый. Начиная с версии 1.15, Flink поддерживает выравнивание задач из разных источников, но не поддерживает выравнивание разделов в одной и той же задаче. Подробнее про источники данных для Flink мы рассказываем здесь. Рекомендуется применять выравнивание водяных знаков в двух случаях:
- когда есть два разных источника, например, Kafka и файл с данными, которые создают водяные знаки с разной скоростью. Как избежать этой проблемы, мы рассказываем в новой статье.
- исходный код запускается с параллелизмом, равным количеству разделов, в результате чего каждой подзадаче назначается одна единица работы.
Читайте в нашей новой статье про реализацию строго однократной доставки из топиков Kafka в реляционную базу данных с помощью механизма двухфазной фиксации Apache Flink. А освоить все тонкости использования Apache Flink и Spark для потоковой обработки событий в распределенных приложениях аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

