 976
976 
Содержание
Сегодня рассмотрим пример построения гибридной архитектуры LakeHouse c Apache Kafka и Snowflake, которая гарантирует высокую масштабируемость и обеспечивает безопасность данных от несанкционированного доступа с помощью маскирования.
От пакетного озера данных на AWS S3 к потоковому LakeHouse
Будучи высоконадежной распределенной платформой потоковой передачи событий, Apache Kafka часто используется для обработки потока данных в режиме реального времени. При этом из соображений безопасности могут применяться приложения-сборщики, где используется документ схемы JSON, чтобы публиковать события только определенных топиках Kafka. Хотя эти данные собираются в реальном времени, они не всегда обрабатываются настолько же быстро. Например, задержка может составлять до пары дней, если данные обрабатываются пакетно с использованием AWS S3 и Apache Spark в кластере EMR. При этом может теряться до 15% масштабного трафика входящих событий. Введение новых топиков и событий выполняется вручную, а потому требует много времени и может быть выполнено с ошибками.
Чтобы улучшить показатели задержки, масштабируемости, стоимости, безопасности, целостности данных и адаптивности системы, можно построить гибридную архитектуру данных – LakeHouse, которая сочетает в себе все преимущества озер и хранилищ данных. Реализовать ее можно без изменения существующего документа схемы JSON, внедрив управление метаданными.
Напомним, Data Lake представляет собой репозиторий для хранения большого объема структурированных и частично структурированных данных. Озеро данных обычно содержит много уровней и реализуется с использованием собственного хранилища облачного провайдера, например, AWS S3. Подобно классическому DWH, озеро данных тоже имеет слоистую структуру. Оно принимает данные из нескольких источников и сохраняет их без изменений на уровне приема, который также называют слой сырых данных или бронзовый уровень (Bronze). Следующий промежуточный stage-уровень называется серебряным (Silver), а последний – золотым (Gold), где данные ближе подходят к своему конечному варианту использования: BI-отчеты, модели машинного обучения и пр.
LakeHouse объединяет озеро данных с хранилищем данных в единую связную платформу данных. Одним из популярных инструментальных средств, которые могут воплотить эту идею, является, Snowflake – облачная платформа обработки и хранения данных, позволяющая объединить данные из множества источников. Она предоставляет эластичное хранилище данных в виде сервиса, реализуя модель DWH as a Service. Будучи развернутым в облаке AWS, Snowflake может использовать Amazon S3 в качестве объектного хранилища. В Snowflake можно создать интеграцию хранилища и ссылаться на нее как на Stage-уровень. Таким образом, все постоянные объекты в конечном итоге хранятся в корзинах AWS S3, управляемых Snowflake. А слои озера данных можно создавать в Snowflake как отдельные базы данных.
Таким образом, можно создать механизм генерации кода, который принимает существующую схему JSON в качестве входных данных, генерирует DDL-запрос на создание таблиц в базе и выполняет операторы механизма, создающего инфраструктуру для всех определенных объектов в документе конфигурации. Источниками этого решения являются Amazon Managed Streaming for Apache Kafka (AWS MSK) и схема JSON. Как это реализовано, мы рассмотрим далее.
Безопасная реализация на Apache Kafka и SnowFlake
AWS MSK представляет собой полностью управляемый кластер Apache Kafka на платформе Amazon, где осуществляется вся потоковая передача событий в реальном времени. А схема JSON — это существующий объект, который включает в белый список все разрешенные топики в кластере Kafka вместе с дополнительными атрибутами. В дополнение к названию топика в каждой конфигурации указывается его владелец и набор ролей, которые могут видеть все поля в событии незамаскированным образом. Поскольку это архитектура, управляемая метаданными и конфигурацией, схема JSON определяет, что происходит в других частях системы:
{
"mapping":[
{"topic":"topic1","owner":"A","ddm_roles":["A_DBADMIN"]},
{"topic":"topic2","owner":"B","ddm_roles":["B_DBADMIN"]}
]
}
В таблице конфигурации хранятся текущие активные версии для всех разделов. Согласно схеме JSON, в этой таблице будет несколько сотен активных конфигураций/строк. Система использует потоки Snowflake для захвата изменений в таблицах конфигурации и при обнаружении изменений выполняет задачу создания всех компонентов Snowflake для этого конкретного топика. Таблица необработанных сообщений служит слоем сырых данных Lakehouse, состоящим из столбца VARIANT, поддерживающего частично структурированные данные. Это является целевой зоной для событий, поступающих из кластера Kafka для одного конкретного топика. Система создает политику динамического маскирования данных из схемы JSON и применяет ее к таблице необработанных сообщений. С точки зрения безопасности это означает, что эта таблица, а также объекты, производные от этой таблицы, имеют замаскированные определенные поля. И лишь отдельные роли, указанные в схеме JSON, могут видеть немаскированные данные.
Вообще прием с маскированием данных в Apache Kafka используется довольно часто. Например, защита данных при доступе к топикам, когда к ним применяется динамическая маскировка, позволяет анализировать данные в зашифрованном или открытом виде без возможности их фактического просмотра. Например, можно рассчитать среднюю зарплату по подразделению, не не видя фактических данных по конкретным людям. Для такого маскирования чувствительной информации в Apache Kafka часто используются готовые решения, например, SecuPi.
Система использует кластер Kafka Connect для загрузки данных из топика в таблицу необработанных сообщений. Для этого был создан контейнерный экземпляр Kafka Connect, который использует реализацию Snowflake Kafka Connector для загрузки данных. Кластер Kafka Connect формируется из множества экземпляров и может автоматически масштабироваться по горизонтали в зависимости от нагрузки. Работающий кластер предоставляет REST API, который можно использовать для настройки коннектора Kafka-Snowflake внутри кластера.
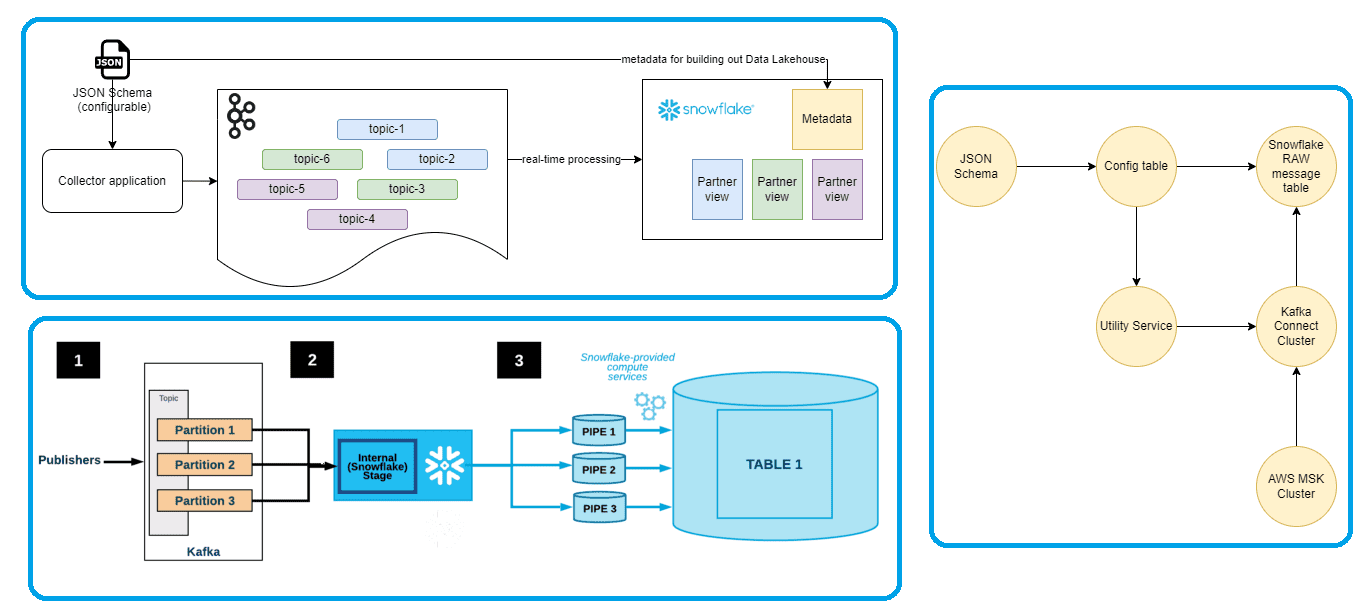
Поскольку эта архитектура управляется метаданными, система должна реагировать на изменения в метаданных. За это отвечает Utility Service. Например, когда в схему JSON добавляется новый топик, Utility Service обновляет кластер Kafka Connect через REST API, чтобы загрузить данные из недавно добавленного топика в Snowflake. При этом система должна иметь среднюю задержку между событием Kafka и таблицей Snowflake не более 5 минут, чтобы можно было своевременно принимать важные бизнес-решения. Благодаря микропакетной обработке удалась реализовать такое решение, работающее практически в реальном времени.
Сочетание горизонтальной масштабируемости Kafka Connect Cluster и бессерверной функции Snowflake под названием Snowpipe позволило отлично оценить систему во время тестов производительности более 40 топиков с 4 миллионами событий в минуту. А с помощью политики динамического маскирования конфиденциальные данные теперь по умолчанию маскируются в первом слое озера данных и во всех последующих слоях. Кроме того, данные доступны только владельцам определенных топиков, а маскированные данные недоступны даже администраторам кластера. Это решение автоматически управляется метаданными, так что внедрение изменений в метаданные заставляет систему адаптироваться к изменениям без какого-либо ручного вмешательства.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

