 1053
1053 
Содержание
При том, что большинство современных озер данных представляют собой облачные объектные хранилища типа AWS S3, многие предприятия хранят данные в собственном кластере HDFS или даже MinIO. Поэтому сегодня специально для обучения дата-инженеров и ИТ-архитекторов рассмотрим, что представляет собой это хранилище и насколько хорошо с ним взаимодействует Apache Spark.
Что такое MinIO
MinIO предлагает высокопроизводительное объектное хранилище, совместимое с AWS S3. MinIO может быть развернуто в публичном или частном облаке на платформе программной виртуализации Kubernetes. В MinIO хранилище и вычислительные ресурсы могут масштабироваться независимо друг от друга. В отличие от Hadoop, MinIO – это не хранилище файлов. В HDFS файл разделяется и реплицируется на различных узлах, а MinIO — это объектное хранилище, где есть файлы и метаданные, которые создают объект. Хотя HDFS можно эмулировать, при этом теряется совместное размещение вычислений и хранилища, как и в случае, если кластеры Spark и Hadoop находятся на разных серверах. И в этом случае MinIO работает быстрее HDFS. Поэтому проекты миграции данных с HDFS на это облачное объектное хранилище весьма актуальны. Как выполнить этот переход, читайте в нашей новой статье.
MinIO предлагает детализацию на уровне сегментов и поддерживает как синхронную, так и почти синхронную репликацию в зависимости от выбора архитектуры и скорости изменения данных. MinIO IAM построен на основе совместимости с AWS Identity and Access Management (IAM) и предоставляет эту платформу приложениям и пользователям независимо от среды, обеспечивая одинаковые функциональные возможности в различных общедоступных облаках, частных облаках и на периферии. MinIO расширяет совместимость AWS IAM с поддержкой популярных внешних провайдеров удостоверений, таких как ActiveDirectory/LDAP, Okta и Keycloak. Это позволяет администраторам переложить управление удостоверениями на предпочтительное решение SSO в своей организации. MinIO оптимизирует шифрование, что практически устраняет накладные расходы, обычно связанные с операциями шифрования хранилища.
С MinIO объекты имеют независимые версии в соответствии со структурой/реализацией Amazon S3. MinIO присваивает уникальный идентификатор каждой версии данного объекта — приложения могут указать идентификатор версии в любое время, чтобы получить доступ к моментальному снимку этого объекта. Сегодня MinIO считается самым быстрым хранилищем объектов на рынке с пропускной способностью GET/PUT 325 и 165 ГиБ/с соответственно всего на 32 узлах NVMe. Эти скорости позволяют выполнять любую рабочую нагрузку на MinIO, от расширенной аналитики до AI/ML. Далее рассмотрим, какова производительность MinIO в качестве серверной части хранилища для Apache Spark в условиях сильной нагрузки в рамках эталонного теста TPC-H™.
Производительность Apache Spark
TPC-H – это эталонный тест, предоставленный TPC, который используется для генерации фиктивных данных и проверки возможностей чтения/записи базы данных. Данные, предоставляемые Spark, лучше всего распараллеливать, когда на них наложена схема. Бенчмарк TPC-H основан на 8 взаимосвязанных наборах данных. Размер датасета для теста связан с коэффициентом масштабирования. Если задать коэффициент масштабирования равным 1000, датасет для тестирования будет объемом 1 ТБ. Этот набор данных для тестирования отформатирован в строковом формате ORC и сохранен в корзине MinIO. Преобразование в этот формат автоматически сжимает данные, в результате чего размер данных уменьшился до 273 ГБ. Тем не менее, это все еще огромный объем данных, который требует большого кластера для эффективной обработки. Чтобы понять, насколько производительность взаимодействия Apache Spark с MinIO отличается от AWS S3, выбрано 8 узлов высокопроизводительных, оптимизированных для вычислений инстансов (c5n.18xlarge) на AWS для запуска Spark. Для MinIO выбрано 8 высокопроизводительных узлов, оптимизированных для хранения (13en.24xlarge). Оба эти экземпляра подключены к сетевым каналам 100 Gbe.
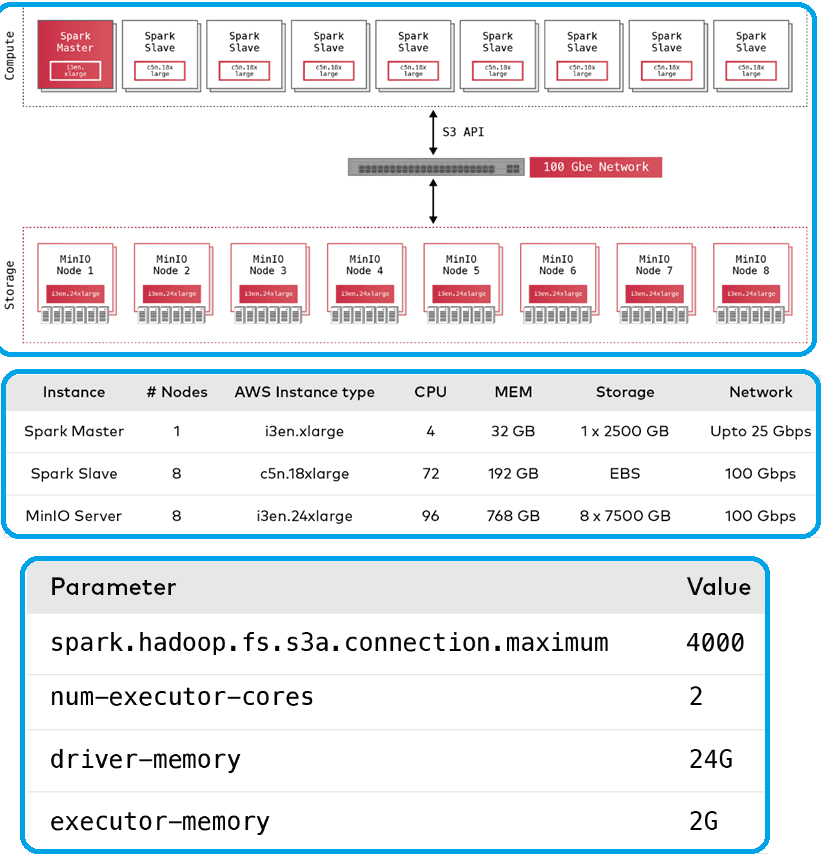
Те же тесты производительности были проведены для данных, хранящихся в Amazon S3, с использованием того же оборудования для Apache Spark. В отличие от AWS S3, который обеспечивает согласованность в конечном счете, MinIO строго согласован. А сама производительность объектных хранилищ MinIO и AWS S3 для рабочих нагрузок Apache Spark оказалась примерно одинакова.
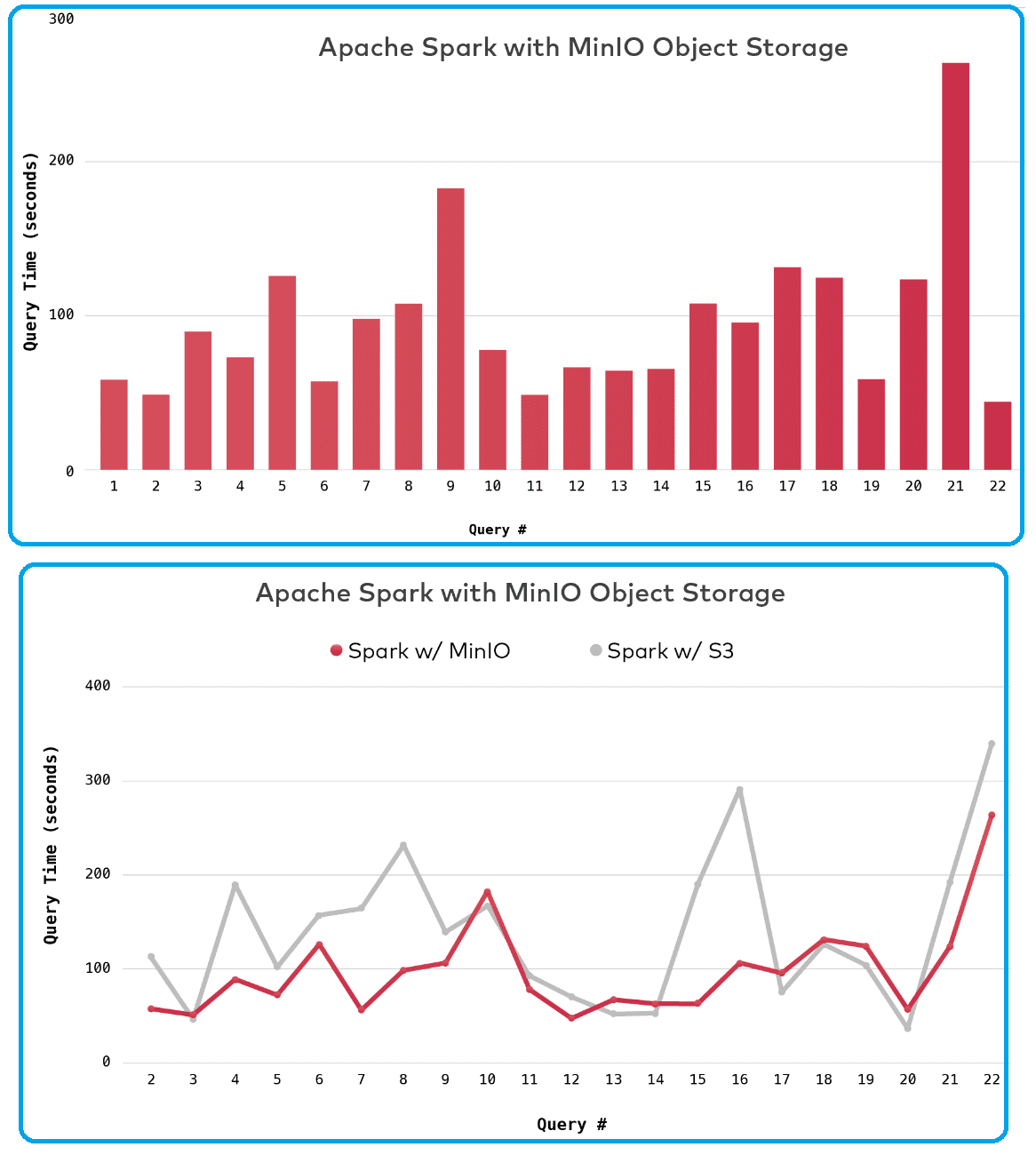
Тем не менее, в некоторых случаях MinIO превосходит AWS S3. Таким образом, легковесное объектное хранилище дает такие преимущества, как масштабируемость, отказоустойчивость и низкая стоимость использования вместе с высокой производительностью при выполнении крупномасштабных рабочих нагрузок в облачных средах. Поэтому сегодня MinIO стало весьма популярным средством хранения объектов в частном облаке , о чем свидетельствует более 200 миллионов его Docker-установок по всему миру. Дополнительным триггером стремительного развития этого объектного хранилища стал API для выборки данных с помощью Apache Spark, о чем мы поговорим далее.
Spark API для выборки данных из Data Lake на MinIO
В 2019 году MinIO представил свою реализацию API, который позволяет пользователям выполнять запросы Select к своим объектам и извлекать часть данных вместо полной загрузки всего объекта. До выпуска этой библиотеки извлечение данных из Data Lake на MinIO происходило так:
- приложения загружают весь объект, используя GetObject();
- объект загружается в локальную память;
- пока объект находится в памяти, запускается процесс запроса данных.
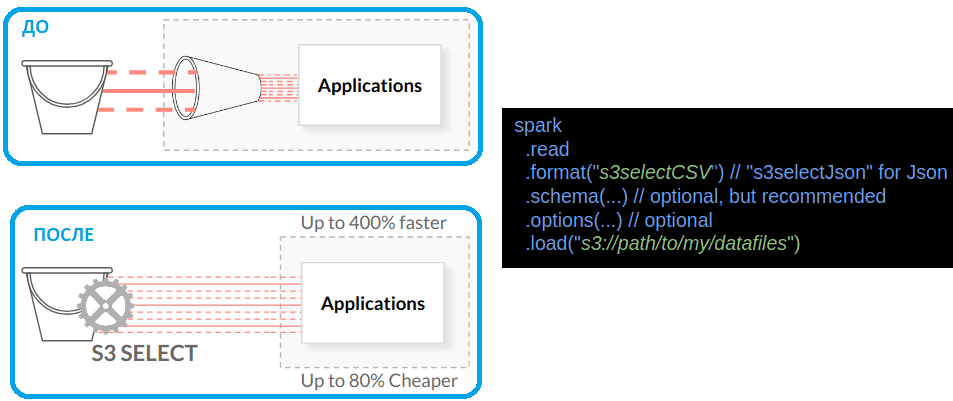
С помощью S3-совместимого Select API приложения теперь могут загружать определенное подмножество объекта — то, которое удовлетворяет заданному запросу Select. Это напрямую влияет на эффективность и производительность, снижая требования к пропускной способности сети, а также к вычислительным ресурсам и объему памяти. Это позволяет Spark-приложениям выполнять больше заданий параллельно на тех же вычислительных ресурсах. Добавить S3 Select API в приложение можно с помощью AWS SDK (aws-sdk-python).
Сперва нужно запустить экземпляр сервера MinIO и настроить mc для связи с этим экземпляром. Затем загрузить образец CSV-файла в соответствующую корзину на сервере MinIO. После этого поддержка MinIO Select API станет доступна и любое приложение может использовать этот API для переноса заданий запросов на сам сервер MinIO.
Проект Spark-Select работает как источник данных Spark, реализованный через интерфейс DataFrame. Библиотека работает путем преобразования входящих фильтров в SQL-операторы Select, которые отправляются в MinIO. Поскольку MinIO отвечает подмножеством данных на основе Select-запроса, Spark считает его датафреймом, над котором можно выполнять типовые для этой структуры данных операции. Как и любой датафрейм, эти данные могут использоваться всеми библиотеками Apache Spark: MLLib, Structured Streaming и пр. Библиотека Spark-Select поддерживает форматы файлов JSON, CSV и Parquet для pushdown-запросов.
Больше подробностей про администрирование и эксплуатацию Apache Spark, Hive и других компонентов экосистемы Hadoop для хранения и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Интеграция Hadoop и NoSQL
- Hadoop для инженеров данных
Источники

