 1045
1045 
Содержание
В этой статье для обучения дата-инженеров и администраторов кластера разберем способы организации совместного использования DAG-файлов при развертывании Apache AirFlow в Kubernetes. Чем хорош вариант с общими томами и почему от него лучше отказаться в пользу Git.
Как организовать обмен DAG-файлами в Apache AirFlow на Kubernetes
Развертывание Apache AirFlow в кластере Kubernetes для эффективной оркестрации пакетных заданий в проектах аналитики больших данных сегодня становится стандартом де-факто, о чем мы писали здесь и здесь. При всех преимуществах такого развертывания, оно имеет ряд ограничений. В частности, могут быть сложности в совместном использовании DAG и плагинов. Напомним, DAG является основной концепцией Apache AirFlow и представляет собой цепочку задач в виде направленного ациклического графа (Directed Acyclic Graph). Каждая задача выполняется с помощью оператора, написанного на Python. Популярная платформа контейнерной виртуализации Kubernetes позволяет пользователям запускать произвольные модули (поды) и конфигурации, чтобы полностью управлять своими средами выполнения, ресурсами и данными. Это превращает AirFlow в универсального оркестровщика рабочих процессов. Однако, использование Kubernetes накладывает определенные ограничения на AirFlow. К примеру, чтобы разные команды дата-инженеров могли совместно использовать DAG, необходимо обеспечить это на уровне Kubernetes.
Проще всего сделать это через общие тома (shared volumes) – постоянные или эфемерные каталоги на диске с данными, доступными для контейнеров в поде Kubernetes. То, как создается этот каталог, носитель, который его поддерживает, и его содержимое определяются конкретным используемым типом тома. Таким образом, при развертывании Apache AirFlow на Kubernetes есть следующие варианты совместного использования DAG:
- предварительная упаковка DAG в Airflow-образ, что требует повторного развертывания образа для изменения или добавления DAG-файлов.
- совместное использование DAG через общие тома. Этот способ часто используют управляемые развертывания Apache Airflow, предлагая синхронизированные решения объектного хранилища в AWS S3 и Google Cloud Storage. Такие облачные решения эквивалентны реализации с помощью PVC (Persistent Volume Claims) – запроса пользователя на хранение данных. Поды потребляют ресурсы узлов, а PVC — ресурсы постоянного хранилища, запрашивая определенный размер и режим доступа (ReadWriteOnce, ReadOnlyMany или ReadWriteMany).
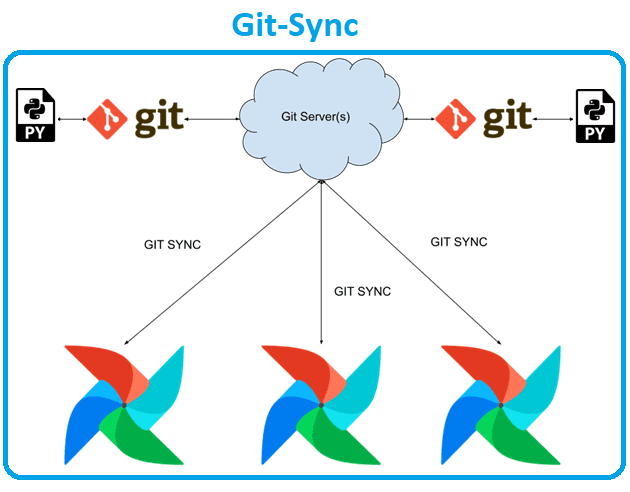
- использование git-sync для синхронизации DAG-файлов. Это простая команда, которая загружает репозиторий git в локальный каталог – контейнер в Kubernetes. Также она может периодически извлекать файлы из репозитория, чтобы приложение могло их использовать. Данные будут повторно извлекаться только в том случае, если цель запуска изменилась в вышестоящем репозитории. При повторном извлечении каталог назначения обновляется атомарно, используя рабочее дерево git в подкаталоге –root и изменяя символическую ссылку. Команда git-sync может использовать HTTP(S) с аутентификацией или без нее или SSH. Ее также можно настроить для вызова веб-перехватчика после успешной синхронизации репозитория git. Вызов выполняется после обновления символической ссылки. При использовании KubernetesExecutor команда git-sync будет работать как контейнер инициализации на рабочих подах.
Первый способ предполагает много ручной работы, а потому не предназначен для крупных проектов, где задействована одна или несколько команд. А вот второй и третий способы ориентированы на совместную работу. Каковы их достоинства и недостатки, и что лучше выбрать для совместного использования DAG-файлов при развертывании Apache AirFlow на Kubernetes, мы рассмотрим далее.
Git-управление vs простота общих томов
Главным достоинством общих томов является простота этого способа для пользователей: можно просто положить файл в папку с помощью команды cp. Это отличный вариант для небольшой установки и нескольких DAG, к которым в основном обращается один пользователь. Но если команда растет, то может случиться неуправляемое редактирование кода непосредственно на общем томе без какого-либо контроля версий. Ведь DAG — это не просто файл с каким-то контентом, а программный код на Python. Поэтому для управления кодом следует применять лучшие инженерные практики. Хотя некоторые версионные объектные хранилища общих томов позволяют отслеживать историю загруженных файлов, здесь нет возможности увидеть, что изменилось, кто внес изменения и когда это произошло. Эту проблему решают Git-подобные системы контроля версий. В частности, Git-Sync позволяет всем компонентам AirFlow независимо синхронизировать свой код с репозиторием, гибко контролируя распространение изменений в коде.
С общими томами есть и другая проблема повышенного потребления ресурсов. Внешне общие тома похожи на локальную файловую систему: они отображают содержимое папки, в них можно читать и записывать файлы, будто они находятся на локальном диске. Но на самом деле эта файловая система является сетевой (NFS, Network File System). И планировщик AirFlow постоянно сканирует папку c DAG-файлами, считывая все ее содержимое. Когда этих файлов становится много, это занимает слишком много времени и ресурсов. В NFS вся связь с серверами происходит через серийные удаленные вызовы процедур (RPC): чем больше мелких запросов происходит, тем более сериализована связь. Хотя сервер может предоставить клиенту делегирование для определенных файлов на основе шаблонов доступа, позволяя кэшировать файлы клиента и работать с ними так, будто к ним обращаются локально, этой функцией нельзя управлять со стороны клиента. Она полностью серверная, и есть много факторов, которые могут ее нарушить: например, делегирование не работает за NAT-шлюзом, требуя обратных вызовов сервера.
Даже если в локальном NFS есть место для хранения файлов, его часто не хватает. Поэтому в случае больших DAG-файлов или их большого количества локальный кэш будет постоянно вытесняться, а файлы будут повторно загружаться. При этом выполняется сканирование папки и постоянное повторное чтение всех файлов, а также их загрузка по сети.
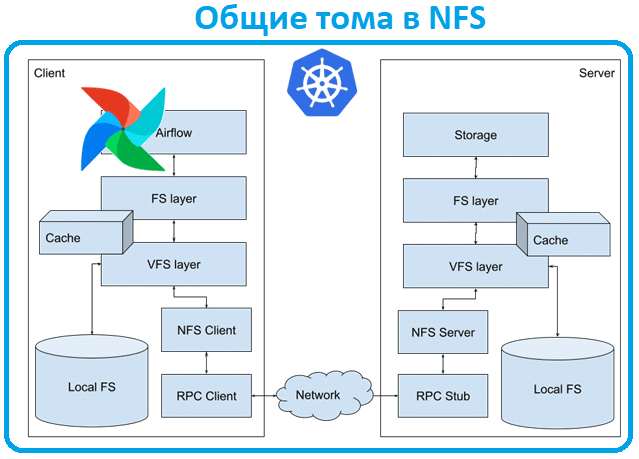
Хотя на практике файлы DAG часто имеют небольшой объем, NFS требуется много операций ввода-вывода в секунду, чтобы обеспечить масштабируемость, надежность и распределение данных. А при росте системы задержка увеличивается: когда NFS не получает достаточно IOPS для синхронизации файлов, файлы обновляются с задержкой. И сетевые файловые системы не обеспечивают согласованность всей папки DAG. Поэтому при сетевых задержках и множестве изменений в DAG-файлах вполне вероятно обнаружить старую версию. Общие тома не гарантируют атомарных изменений более чем в одном файле. Таким образом, стабильность AirFlow снижается, а количество случайных сбоев растет.
С git-sync нужны только локальные тома для планировщика AirFlow, которые можно сканировать с любой частотой и скоростью. Git-Sync имеет встроенные атомарные обновления: не требуется сетевой обмен данными, когда рабочий процесс выбирает другую задачу и анализирует DAG-файл для запуска кода. Это все происходит локально внутри worker’а.
В заключение отметим, что протокол Git изначально был разработан для отслеживания и обмена изменениями в исходных файлах и очень оптимизирован именно для этой цели. По сравнению с NFS способу git-sync нужно синхронизировать изменения только с DAG и только при их изменении вместо непрерывного сканирования и загрузки всех данных.
Освойте администрирование и эксплуатацию Apache Hive для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

