 1049
1049 
Сегодня заглянем под капот ИТ-инфраструктуры самой знаменитой франшизы быстрого питания. Как устроена унифицированная платформа потоковой обработки событий в McDonald’s на базе облачного полностью управляемого сервиса Apache Kafka в AWS и что гарантирует высокую доступность и надежность решения.
Архитектурный дизайн
Архитектуры, основанные на событиях, обеспечивают гибкость интеграции, масштабируемость и некоторые возможности работы в реальном времени. Однако для успешной реализации такой архитектуры требуется надежная платформа. Будучи огромной корпорацией, McDonald’s использует события по всему технологическому стеку для асинхронной, транзакционной и аналитической обработки, включая отслеживание выполнения мобильных заказов и отправку маркетинговых сообщений (предложений и рекламных акций) своим клиентам.
Унифицированная платформа нужна для масштабируемой, безопасной и надежной обработки потока данных в режиме реального времени между службами и приложениями в разных доменах. Это обеспечивает согласованность и снижает сложность реализации и эксплуатации, связанную с поддержкой и внедрением архитектур обработки событий. Однако, несмотря на популярность решений подобного уровня, каждая большая компания реализует его под себя, т.к. отсутствуют универсальные лучшие практики и стандартные продукты. Поэтому на старте проекта архитекторы McDonald’s определили следующие высокоуровневые цели к будущей потоковой обработки событий:
- автоматическое масштабирование для размещения растущего числа событий без потери качества обслуживания;
- высокая доступность, чтобы выдерживать сбои в своих компонентах;
- высокая производительность, события должны доставляться в режиме реального времени с возможностью обработки высококонкурентных рабочих нагрузок;
- соответствие корпоративным рекомендациям по безопасности данных в части шифрования и контроля доступа;
- управляемая надежность, чтобы избежать потери каких-либо событий;
- согласованность реализации шаблонов, связанных с обработкой ошибок, отказоустойчивостью, развитием схемы данных, мониторингом и аварийным восстановлением;
- простота реализации и эксплуатации.
События, создаваемые приложениями-продюсерами, будут отправляться в платформу потоковой обработки в виде сообщений, откуда их будут считывать потребители, т.е. другие приложения для последующих вычислений. Этот архитектурный дизайн реализуется следующими компонентами:
- брокер сообщений, например, собственный кластер Apache Kafka или полностью управляемый облачный сервис типа AWS Managed Streaming for Kafka Service (MSK) для размещения топиков с событиями и предоставления семантики их создания и использования. В McDonald’s выбран AWS MSK, поскольку он интегрируется с другими сервисами AWS, которые используются в компании. При выборе также учитывался баланс между снижением эксплуатационных расходов и гибкостью настройки для сценариев использования.
- реестр схем типа Confluent Schema Registry в Apache Kafka, нужный для проверки схемы данных и совместимости между версиями событий. События должны следовать четко определенному контракту, обеспечивая качество данных в нижестоящих приложениях-потребителях. Но потоковые данные имеют динамический характер, а потому эволюционируют. Реестр схем обеспечивает возможность работы приложений при изменении схемы событий.
- Резервное хранилище событий. Чтобы избежать потери сообщений в случае недоступности MSK, платформа подключена к резервному хранилищу данных, где она записывает события в базу данных. Архитектура предоставляет инструменты и утилиты для чтения сообщений и публикации их обратно в MSK, как только этот облачный брокер сообщений вновь станет доступен.
- SDK-инструменты разработки ПО, т.е. библиотеки для конкретных языков программирования, которые предоставляют продюсерам и потребителям API для записи и чтения событий со встроенной логикой проверки схемы, обработки ошибок и реализации шаблонов повторных попыток. SDK помогают разработчикам, повышая их производительность и обеспечивая последовательный подход к внедрению лучших практик.
- вспомогательные утилиты и инструменты для разработчиков и SRE-инженеров, которые обеспечивают исправление событий в топиках недоставленных сообщений, видимость состояния кластера и администрирование кластера.
- шлюз событий, который обеспечивает гибкость и абстракцию, не раскрывая внутреннее управление топиками Kafka, поскольку платформа потоковой обработки событий работает как с внутренними приложениями, так и с внешними системами.
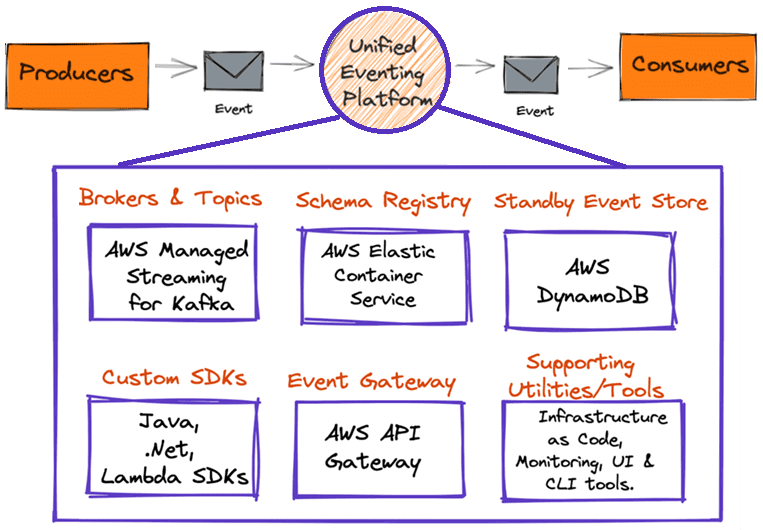
Как работает эта архитектура данных, управляемая событиями, мы рассмотрим далее.
Принципы работы и технологии реализации
События создаются и потребляются вышеописанной платформой потоковой обработки McDonald’s следующим образом:
- сперва схема события определяется и регистрируется в реестре схем;
- приложения-продюсеры используют соответствующий SDK для публикации событий;
- при запуске схема приложения-продюсера события кэшируется в нем для повышения производительности;
- SDK выполняет проверку схемы, чтобы убедиться, что событие соответствует ей;
- если проверка схемы прошла успешно, SDK публикует событие в основном топике Kafka. Иначе событие направляется в топик недоставленных сообщений для этого продюсера.
- если SDK обнаруживает ошибку, связанную с недоступностью MSK, он записывает событие в базу данных DynamoDB;
- приложения-потребители используют для чтения сообщений с событиями соответствующий SDK, который сперва выполняет проверку схемы, чтобы убедиться в корректности событий;
- успешное потребление событий приводит к фиксации смещения обратно в MSK и переводит к потреблению следующего события из топика;
- события в топике недоставленных сообщений позже исправляются с помощью утилиты администратора и публикуются обратно в основной топик Kafka;
- внешние события от сторонних систем публикуются через шлюз событий.
Ключевой проблемой в потребляющих системах обычно является целостность данных. В случае McDonald’s гарантии консистентности обеспечивает MSK и реестр схем, позволяя обеспечивать соблюдение контрактов данных между системами. Схема определяется как описание ожидаемых полей и типов данных, а также необязательных и обязательных полей. В режиме реального времени каждое сообщение проверяется с помощью библиотек сериализации по этой схеме на достоверность. При обнаружении несоответствий сообщение направляется в топик недоставленных сообщений для исправления.
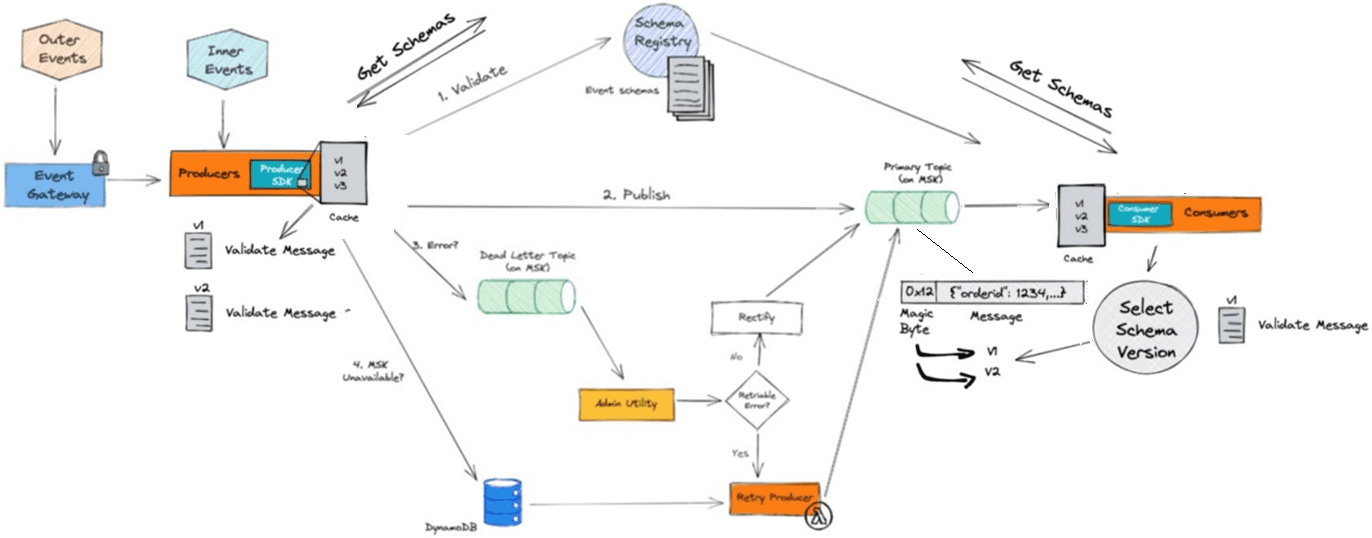
При запуске приложения-продюсеры кэшируют в памяти список известных схем данных. Схема может быть обновлена по разным причинам, включая увеличение количества полей или изменение типов данных. Когда продюсер публикует сообщение, информация о версии сохраняется в теме с использованием специального байта в начале каждого сообщения. Позже, когда сообщения потребляются, этот байт определяет, с какой схемой предполагается использовать сообщение. Такой подход сокращает количество последовательных обновлений и смешанных версий сообщений в топиках Kafka. Если нужно выполнить откат назад или сделать обновление схемы, потребители могут анализировать каждое сообщение отдельно. Использование реестра схем проверяет контракты данных в разрозненных системах и помогает обеспечить целостность данных в нижестоящих аналитических приложениях.
Хотя AWS MSK обеспечивает автоматическое масштабирование хранилища, подключенного к брокеру, инженерам McDonald’s пришлось создать собственное решение для расширения кластера. Эта функция автомасштабирования срабатывает, когда загрузка ЦП брокера превышает настраиваемый порог, добавляя брокера в кластер MSK, а затем запуская другую лямбда-функцию для перемещения разделов между брокерами. Для эффективного масштабирования и минимизации сбоев события разделены по нескольким кластерам MSK на основе домена. Домен событий определяет, в каком кластере будет находиться топик Kafka, а приложения-потребители имеют возможность использовать события из любого топика разных домена. Платформа настроена для поддержки глобальных развертываний в разных регионах с конфигурацией высокой доступности каждого.
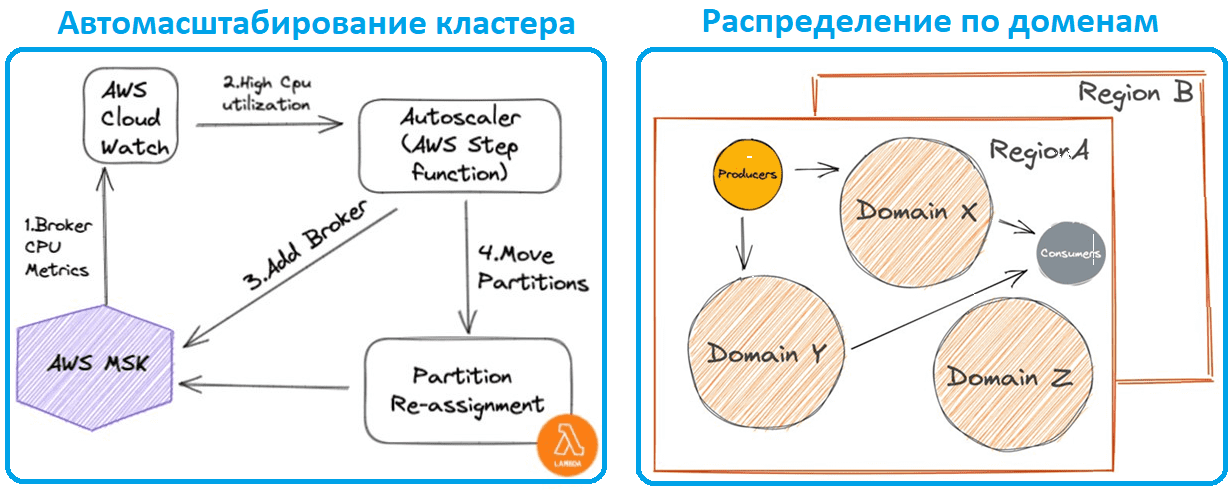
В будущем дата-инженеры McDonald’s планируют развивать реализованную платформу потоковой обработки событий, добавив поддержку формальной спецификации событий, и перейти к бессерверному подходу для MSK, а также автомасштабированию разделов топиков Kafka.
Узнайте, как внедрить современные архитектурные модели на базе Apache Kafka в свои ИТ-проекты аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://medium.com/mcdonalds-technical-blog/behind-the-scenes-mcdonalds-event-driven-architecture-51a6542c0d86
- https://medium.com/mcdonalds-technical-blog/mcdonalds-event-driven-architecture-the-data-journey-and-how-it-works-4591d108821f

