 691
691 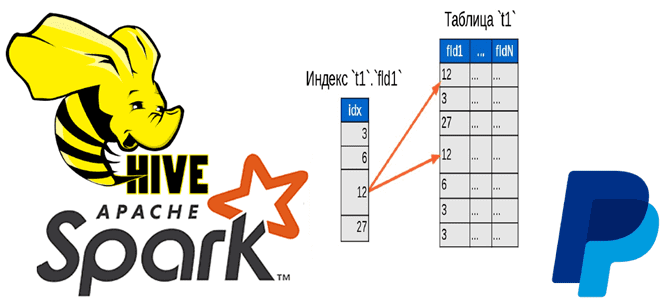
Содержание
Чтобы добавить в наши курсы по Apache Hadoop и Spark еще больше интересных примеров, сегодня рассмотрим кейс компании PayPal, которой удалось ускорить работу Hive с помощью open-source библиотеки Dione. Зачем индексировать данные в HDFS и как это сделать быстро.
Трудности бакетирования в Hive и Spark
Вычислительный движок Apache Spark отлично работает с хранилищами данных на базе HDFS — распределенной файловой системой Hadoop. Одним из таких хранилищ является NoSQL-СУБД Apache Hive, которая позволяет обращаться к данным, хранящимся в HDFS средствами стандартных SQL-запросов. Все эти технологии ориентированы на аналитическую обработку огромных объемов данных с их полным сканировании. Но на практике часто требуется выполнение сценариев, отличающихся от типовых OLAP-задач, например, многострочная загрузка данных, чтобы исследовать небольшие датасеты по определенным идентификаторам, или выборка одной строки по запросу REST API. Обычно такие задачи решаются с использованием выделенных хранилищ типа HBase, Cassandra и пр., которые требуют дублирования данных и значительно увеличивают эксплуатационные расходы.
Однако, инженеры крупнейшей дебетовой электронной платёжной системы PayPal решили пойти другим путем и использовать для этих задач имеющиеся инструменты в виде Spark и Hive. В частности, чтобы выявить из 30 миллионов пользователей своей платформы мошенников и нарушителей правил, компания периодически использует автоматизированные инструменты веб-сканирования для сбора общедоступной неконфиденциальной информации с отдельных веб-сайтов клиентов. Многие из этих сайтов являются очень объемными, поэтому данные сканирования в итоге получаются большими. Ежедневно результаты сканирования вместе с дополнительными метаданными сохраняются в таблице Hive, партиционированной по дате. В среднем размер данных составляет примерно 150 ТБ сжатых файлов из 2 миллионов веб-страниц, со средним размером каждой веб-страницы около 100 КБ.
Аналитические приложения получают доступ к этим данным следующими способами:
- полное сканирование, когда процессы пакетной аналитики сканируют все данные, например, для кластеризации похожих клиентов. Это может длиться часами.
- многострочная загрузка, когда аналитикам и Data Scientist’ам надо выбрать из множества веб-страниц набор данных для своих моделей обучения. На это уходит пара минут.
- однострочная выборка, когда нужно получить определенную веб-страницу по ее URL-адресу, например, с помощью REST-сервис для групп поддержки клиентов. Это должно выполняться за несколько секунд.
В PayPal этот шаблон доступа к данным, который чаще всего используется в пакетной аналитики специальных задач, характерен для множества доменных областей, включая анализ рисков (данные транзакций, попытки входа в систему), поиск соответствий (кредитные обзоры), маркетинг и пр. Чтобы реализовать этот паттерн, дата-инженеры PayPal решили определить таблицы Hive поверх отсканированных данных и запроса к ней с помощью Spark. Это хорошо сработало для задачи пакетной обработки полного сканирования. Но задача с многострочной выборкой URL-адресов (0,1–1% строк) выполнялась намного дольше, чем ожидалось. Впрочем, это не удивительно, если вспомнить, что shuffle — это самая тяжелая операция в распределенных системах с точки зрения загрузки процессора и сетевого ввода-вывода. Для набора URL-адресов среднего размера Apache Spark использует соединение в случайном порядке либо хэш-соединение, либо соединение с сортировкой-слиянием, о чем мы рассказывали здесь. При этом полные данные веб-страниц передаются по сети, даже если большинство строк отфильтровывается соединением с небольшой выборкой.
Дополнительную задержку создает десериализация, т.к. даже для небольшого образца URL-адреса, когда Spark оптимизировал широковещательное соединение, все равно нужно десериализовать все строки полных данных веб-страниц. А извлечение одной строки конкретной веб-страницы по запросу REST API было еще медленнее: пользователям приходилось по несколько минут ждать, пока Spark просканирует все данные веб-страниц.
Чтобы обойти эти недостатки, дата-инженеры PayPal вспомнили про бакетирование Hive и Spark, которое ускоряет выполнение SQL-запросов, исключая рандомизацию при JOIN-соединениях и агрегациях за счет хранения данных в одних сегментах или столбцах кластеризации, называемых бакеты (bucket). По сути, это механизм хранения предварительно перетасованных данных для последующего использования их в операциях соединения, избегая повторяющихся перетасовок одних и тех же данных. Но такой способ требует тесной связи между метаданными и самими данными, т.е. пользователи не могут напрямую добавлять данные в базовые папки. В этом подходе нужно использовать Spark или Hive для сохранения данных в бакетах. При этом все данные сохраняются в файлах, где каждый файл содержит только определенные ключи по их хэш-значениям и сортируется по этим ключам. Такой подход может значительно улучшить многострочное соединение с данными. Но он имеет целый ряд недостатков:
- нужно владеть данными или дублировать их;
- допустим только один ключ на таблицу;
- нет готовой поддержки для быстрого извлечения одной строки из данных (за секунды) из-за отсутствия в Spark API произвольного доступа;
- механизмы бакетирования в Spark и в Hive отличаются друг от друга: в Spark есть сортировка по времени чтения, что снижает производительность выполнения запроса. Когда Spark записывает данные в бакетированную таблицу, он может генерировать множество небольших файлов, которые не эффективно обрабатываются HDFS, о чем мы недавно писали.
- при чтении из нескольких файлов бакетов возникает проблема со Spark. При том, что сам механизм бакетирования нужен, чтобы пропустить стадию перемешивания и ускорить выполнение запросов, время по-прежнему тратится на оператор сортировки, хотя данные уже отсортированы.
Поняв несостоятельность этого подхода, дата-инженеры PayPal решили реализовать собственную альтернативу на Spark и Hive, которую мы рассмотрим далее.
Индексация данных в HDFS, Hadoop и Spark с библиотекой Dione
Итак, анализируемые данные очень огромны: миллиарды строк, каждая из которых может иметь много столбцов. Данные только добавляются, например, ежедневно добавляется новый раздел с новыми данными. Данные имеют естественные ключи, которые пользователи захотят запросить, при этом может быть более одного ключа, и ключ может быть не уникальным. Данные могут принадлежать другой команде, т.е. невозможно изменить их формат, расположение и другие характеристики. Пользователям необходимо взаимодействовать с данными тремя вышеупомянутыми способами: пакетная аналитика, быстрая многострочная загрузка и выборка одной строки. Чтобы снизить стоимость эксплуатации, включая расходы на хранение и вычисления, нужно избежать дублирования данных. Учитывая все эти требования, дата-инженеры PayPal пришли к выводу необходимости индексов, которые будут выступать как тонкий слой, содержащий метаданные и указатели на нужные данные. Так можно выполнять большую часть работы с этим индексом, избегая тяжеловесных вычислений с самими данными.
В рамках задачи создания системы индексации, интегрированной в Spark, Hive или HDFS дата-инженеры Paypal также рассматривали возможность использования key-value хранилища, т.к. для загрузки нескольких строк и выборки одной строки нужен быстрый способ выполнения выборки ключ-значение. Рассмотрев соответствующие готовые решения (HBase, Cassandra, Aerospike), разработчики пришли к выводу, что все они имеют ряд недостатков:
- избыточность для данного сценария – эти сложные технологии предназначены для обработки гораздо более сложных вариантов использования с меньшей задержкой;
- key-value хранилища управляют данными, т.е. ими нужно владеть или дублировать их;
- эти сервисы требуют выделенных ресурсов и имеют высокие накладные расходы на операции, администрирование, мониторинг и пр.
- эти системы используются критически важными приложениями в режиме реального времени, а массовое сканирование пакетными приложениями снизит их общую производительность, вызывая задержку в критически важных приложениях.
Из-за невозможности использовать готовое решение, инженеры PayPal реализовали собственное в виде новой библиотеки индексирования данных в HDFS и Spark под названием Dione. Эта библиотека с открытым исходным кодом выпущена в конце 2021 года и доступна на Github. Основная идея в том, что индекс представляет собой «теневую» таблицу исходных данных и содержит только ключевые столбцы и указатели на данные. Он сохраняется в специальном формате по типу AVRO с группированием. На основе этого индекса библиотека предоставляет API-интерфейсы для быстрого соединения, запроса и извлечения исходных данных.
Главным преимуществом Dione является API для построения индекса данных в HDFS и запроса индекса для многострочной загрузки и однострочной выборки. В случае многострочной загрузки Spark используется как механизм распределенной обработки, позволяя загружать подмножество данных (от 0,1% до 100% ключевого пространства) намного быстрее, чем соединения Spark/Hive. А однострочная выборка дает возможность получения ключ с секундной задержкой и низкой пропускной способностью. Так можно повторно использовать данные HDFS, которые в основном используются для пакетной обработки, для нетиповых сценариев.
Hadoop для инженеров данных
Код курса
HDDE
Ближайшая дата курса
в любое время
Продолжительность
40 ак.часов
Стоимость обучения
89 600
Dione включает следующие основные компоненты:
- HdfsIndexer — библиотека для индексации данных HDFS и обратной загрузки данных с учетом метаданных индекса;
- AvroBtreeFile — формат файла на основе Avro для хранения строк в файле в порядке B-дерева для быстрого поиска;
- IndexManager — высокоуровневый API для управления индексами с помощью Spark.
Это делает данные и индекс доступными для пакетной обработки без дублирования, а также поддерживает несколько индексов для одних и тех же данных без необходимости владения ими. Dione основана только на Spark, Hive и HDFS без внешних сервисов, а сам индекс предоставляется как стандартная таблица Hive. Специальный формат Avro B-Tree поддерживает одноранговую выборку одной строки за считанные секунды.
Поскольку индекс сохраняется как стандартная таблица Hive, доступная для запросов пользователей, они могут загружать индексную таблицу как стандартную таблицу Hive и фильтровать ее с помощью стандартного соединения Hive/Spark со своей выборкой данных. А API на основе столбцов метаданных индекса, позволяет быстро извлечь исходные данные.
Формат AvroBtreeFile представляет собой просто файл Avro, куда добавлено еще одно поле в каждую строку со ссылкой, не связанной с указателем Index, на другую строку в том же файле. А благодаря сортировке строк в каждом файле в порядке B-дерева, сокращается количество переходов при чтении файла, когда нужно случайным образом искать и выбирать по определенному ключу.
Библиотеки Indexer и AvroBTreeFile являются независимыми пакетами и полагаются только на HDFS. Пользователи могут сохранить любую таблицу в формате Avro B-Tree, чтобы она была доступна как для пакетной аналитики с помощью Spark, так и для выборки одной строки. А для упрощения работы пользователей Spark в Dione был добавлен высокоуровневый Scala и Python API для создания и использования индекса.
Таким образом, решая собственную задачу, дата-инженеры PayPal создали новый полезный инструмент, выпустив Dione, библиотеку индексирования Spark. Это дает пользователям возможность использовать данные пакетной аналитики для более интерактивных задач, таких как загрузка нескольких строк и выборка одной строки за считанные секунды. В будущем разработчики Dione планируют добавить в решение оптимизацию соединений, улучшить интеграцию с оптимизатором Spark и реализовать другие полезные возможности.
Больше подробностей про администрирование и эксплуатацию Apache Spark, Hive и других компонентов экосистемы Hadoop для хранения и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Hadoop SQL администратор Hive
- Интеграция Hadoop и NoSQL
- Hadoop для инженеров данных
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
[elementor-template id=»13619″]
Источники

