Почему планировщик Apache AirFlow чувствителен к всплескам рабочих нагрузок, из-за чего тормозит база данных метаданных, как исправить проблемы с файлом DAG, лог-файлами и внешними ресурсами: разбираемся с ошибками пакетного оркестратора и способами их решения. Проблемы с планировщиком Хотя Apache AirFlow позиционируется как довольно простой фреймворк для оркестрации пакетных процессов с...
Что такое модификатор FINAL в SELECT-запросе ClickHouse, с какими табличными движками он работает, почему снижает производительность и как этого избежать. Тонкости потокового выполнения SQL-запросов в колоночной СУБД. Зачем в SELECT-запросе ClickHouse нужен модификатор FINAL? Хотя SQL-запросы в ClickHouse имеют типовую структуру, их реализация зависит от используемого движка таблиц. Например, запрос...
От чего зависит задержка передачи данных из Apache Kafka в ClickHouse, как ее определить и ускорить интеграцию брокера сообщений с колоночной СУБД: настройки и лучшие практики. Интеграция ClickHouse с Kafka Чтобы связать ClickHouse с внешними системами, в этой колоночной СУБД есть специальные механизмы – интеграционные движки таблиц. Например, для взаимодействия...
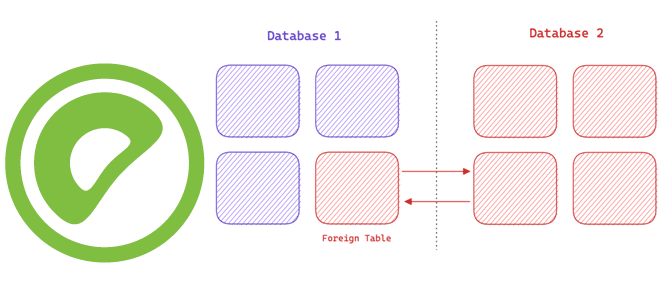
Чем внешняя таблица Greenplum отличается от сторонней, и как они преобразуются друг в друга: организация доступа к данным вне базы, FDW-обертки и протоколы для интеграции MPP-СУБД с другими источниками информации. Сторонняя таблица в Greenplum Термины внешняя (external) и сторонняя (foreign) table похожи, но нюансы их использования в Greenplum отличаются. Такие...
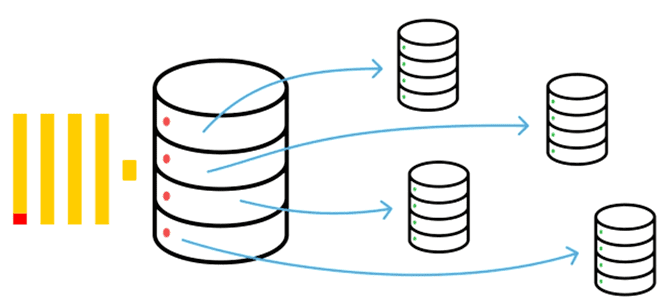
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера. Шардирование в ClickHouse Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью...
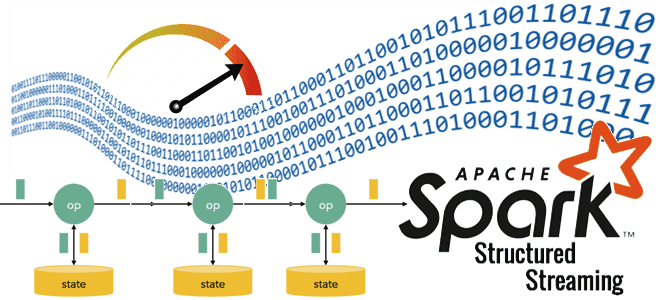
Где хранятся состояния операторов в stateful-приложениях Apache Spark Structured Streaming, зачем разработчику нужны данные о состояниях, как их получить и чем для этого полезен новый API State Reader от Databricks. Хранение состояние в Apache Spark Structured Streaming В феврале 2024 года компания Databricks выпустила очередную версию Databricks Runtime – среду...
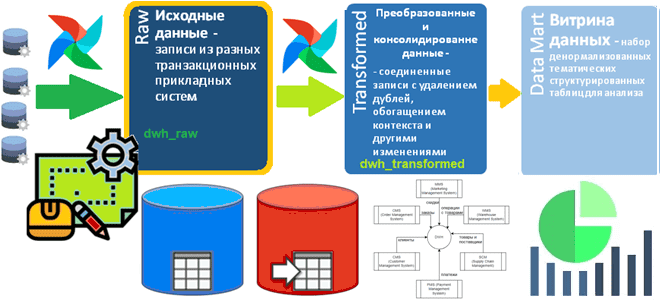
Как определить структуру Raw-слоя корпоративного хранилища данных: пример проектирования и DDL-скрипт для кейса электронной коммерции, выбор компонентов решения для архитектуры данных. Постановка задачи: анализ систем-источников Сегодня корпоративные хранилища данных (DWH, Data Warehouse) обычно реализуются в виде нескольких баз данных, связанных ETL-процессами. Причем каждая из этих гомогенных или гетерогенных, т.е. на...
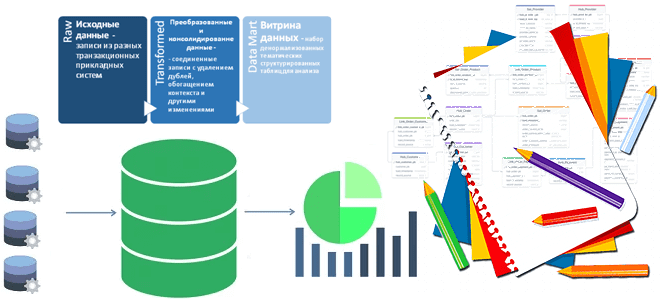
Как построить хранилище данных с подходом Data Vault: пример проектирования схемы данных и разработка DDL-скрипта для Transformed-слоя DWH интернет-магазина. Слоистая структура DWH и подход Data Vault Корпоративное хранилище данных (DWH, Data Warehouse) часто бывает гетерогенным, т.к. организованным с помощью нескольких баз данных, связанных ETL-процессами. Согласно концепции слоистой архитектуры (LSA, Layered...

Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Что такое гонка данных в дата-инженерии Одна из главных особенностей распределенных систем – это задержка между...
29 января 2024 года вышла очередная веха 2-ой версии Apache NiFi, которая включает ряд новых функций и существенных обновлений зависимостей, а также несколько критических изменений. Рассмотрим самые интересные из них. Новые процессоры Apache NiFi 2.0.0-M2 С точки зрения управления версиями, веха рассматривается как некоторое значимое обновление, контрольная точка, меняющая дальнейшее...