 1024
1024 
Содержание
Что такое гонка данных, почему она опасна в ETL-заданиях и как ее избежать: зачем разделять задания репликации в RAW-слой хранилища от их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений.
Что такое гонка данных в дата-инженерии
Одна из главных особенностей распределенных систем – это задержка между обновлением одних и тех же данных на разных компонентах. Это очень важно при реализации конвейеров обработки данных, которые зависят друг от друга. Проектирование таких ETL-конвейеров усложняется, если есть строгие требования к последовательности обработки данных и ссылочной целостности. А когда данные поступают с разной скоростью из разных источников с различными соглашениями об уровне обслуживания, возникает так называемая гонка данных.
Вообще состояние гонки или неопределенность параллелизма довольно характерно для распределенных систем стека Big Data из-за большого количества сервисов и огромного количества событий. Гонка данных является одним из случаев состояния гонки, возникающим при параллельном выполнении кода в многопоточном режиме, когда поведение системы зависит от того, в каком порядке выполняются части кода. Проблемы параллелизма обычно незаметны при разработке и тестировании, а проявляются только в производственных средах на высоких рабочих нагрузках. Если поведение системы зависит от последовательности событий, которая не является детерминированной и явно не контролируется, состояние гонки рано или поздно возникнет. Это характерно для многопоточных и многопроцессорных систем, а также проявляется в конвейерах обработки данных в виде гонки данных, когда один процесс обращается к фрагменту данных, который в это время изменяется другим процессом. Чтобы понять, как это может случиться, чем опасно и какие способы позволят избежать этого, далее рассмотрим практический пример.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
20 апреля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Оркестрация заданий ETL для корпоративного хранилища данных
Например, при репликации данных из OLTP-базы данных в корпоративное хранилище каждый час, выполнение каждого задания репликации занимает около 20 минут. Поскольку OLTP-сценарии ориентированы на запись и предполагают высокую нормализацию модели, в системе источнике, т.е. транзакционной БД, обеспечивается ссылочная целостность между реплицируемыми таблицами. Возьмем в качестве наглядного примера интернет-магазин, о проектировании и реализации которого я писала в блоге нашей Школы прикладного бизнес-анализа здесь и здесь, со следующей схемой данных.
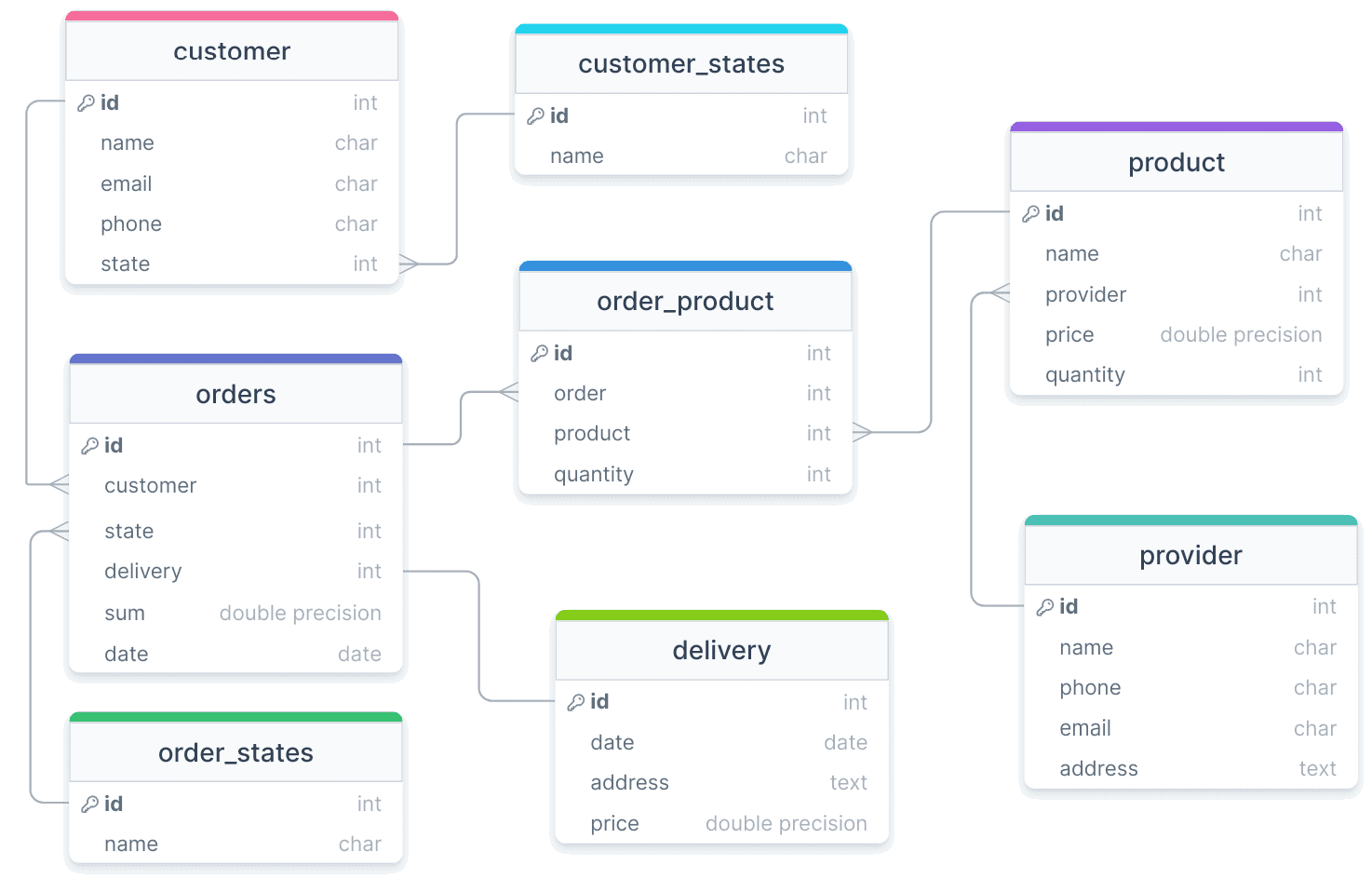
Предположим, ETL-конвейер настроен на последовательную репликацию таблиц с товарами и заказами, т.е. orders и product. Обе таблицы связаны через order_product, которая имеет ограничение внешнего ключа и требование ссылочной целостности, т.е. каждый order и product в ней должны существовать в таблицах orders и product соответственно. В таком случае таблица order_product должна загружаться в хранилище данных только после orders и product, чтобы избежать остановки задания из-за нарушения целостности по причине отсутствия ссылки внешнего ключа. Избежать этого поможет отделение задания репликации данных в RAW-слой хранилища от задания их преобразования и сохранения в Transformed-слое DWH перед созданием витрин данных для BI-приложений. Подробнее об этом я рассказываю в новой статье.
Это довольно простое решение, при использовании которого надо настроить оркестратор ETL-заданий. В этом случае следует запускать задание преобразования данных только после успешного выполнения задания репликации, а не просто применять триггеры по расписанию. Если задание преобразования данных запланировано на определенное время, оно может выполниться некорректно, когда предыдущее задание репликации выполнялось дольше ожидаемого.
Вместо этого можно создать моментальный снимок (snapshot) — статическую, неизменяемую необработанную базу данных, на которую будут направлять запросы по преобразованию данных. Это может быть клон исходной базы данных, созданный во время периода простоя в заданиях репликации данных. Это означает, что никакие новые данные не могут активно реплицироваться в snapshot при создании клона. Иначе есть риск столкнуться с вышеописанными проблемами реляционной целостности между исходными таблицами, случайно создав клон между репликацией двух таблиц с отношениями внешнего ключа, что приведет к еще одному состоянию гонки.
После создания такой shapshot-базы можно иметь все те же гарантии реляционной целостности, что и у исходной системы. Еще одним преимуществом этого подхода является то, что внутридневное изменение данных ограничено для пользователей, которые потребляют преобразованные данные через уровень отчетности.
Предположим, преобразования данных происходят в течение дня посредством запланированных заданий или CI-сборок, и результаты этого немедленно предоставляются последующим BI-системам аналитической отчетности. Если источник необработанных данных представляет собой статический неизменяемый снимок, пользователи имеют точные ожидания относительно актуальности данных. Например, что они будут такими же свежими, как и в конце вчерашнего рабочего дня, поскольку колебания дневных данных не будут неожиданно поступать в систему отчетности в течение дня. Разумеется, это зависит от частоты репликации, преобразования данных и связанных с ними соглашений об уровне обслуживания, которые необходимо определить в соответствии с требованиями бизнеса.
Еще одним решением может быть внедрение «глобального фильтра временных меток» для всех источников исходных необработанных данных перед их преобразованием. Эта временная метка может быть общей отметкой времени loading_at среди всех преобразуемых исходных таблиц.
Например, если преобразуются 3 исходные таблицы, и максимальная общая временная метка между ними равна 11:00, то перед преобразованием можно отфильтровать все записи так, чтобы они были меньше или равны этому значению, даже если некоторые таблицы содержат записи с временными метками loading_at, превышающими это значение. Так можно гарантировать, что все источники отражают данные до определенного момента времени, и точно знать, что ни один источник не опередит другие при репликации, т.е. загрузке данных в хранилище. Автоматизировать эту процедуру можно с помощью таких инструментов преобразования данных, как dbt, который позволяет выполнять вычисления с данными без их фактической загрузки, с помощью макросов или предварительной обработки модели.
Более общим решением будет глобальный распределенный механизм блокировки. Он сможет динамически гарантировать, что задания репликации и преобразования данных никогда не выполняются одновременно. Например, если запланировано выполнение задания преобразования данных, когда задание репликации данных все еще выполняется, оно «дождется», пока задание репликации завершится, а затем начнется. Для реализации такого механизма блокировки можно использовать оркестраторы, например, Apache AirFlow c кросс-зависимостями между разными DAG. В частности, этот фреймворк включает 3 нативных способа создания таких перекрестных зависимостей и управления ими через операторы TriggerDagRunOperator, ExternalTaskSensor и SimpleHttpOperator.
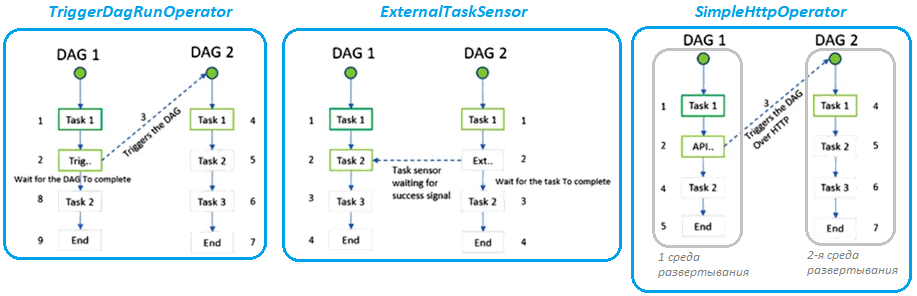
Такое решение сложнее реализовать, но оно более динамичное и лучше подходит для систем, где одновременно выполняется множество конвейеров ETL с заданиями репликации и преобразования данных.
Освоить на практике лучшие приемы использования этого оркестратора пакетных процессов в задачах реальной дата-инженерии вам помогут специализированные курсы в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Практическая архитектура данных
- Data Build Tool для инженеров данных
- Data Pipeline на Apache AirFlow и Apache Hadoop
Источники

