 746
746 
Недавно мы писали, что такое цепь Маркова, как это используется в практических приложениях Data Science и с помощью каких инструментов реализуется этот граф состояний. В продолжение этой полезной для обучения дата-аналитиков темы посмотрим на модели маркетинговой атрибуции как на марковские цепи и разберем пользу этого представления. Практический пример в Google Colab с библиотеками pandas, networkx и matplotlib.
Математика цепи Маркова и модели маркетинговой атрибуции
Напомним, цепь Маркова — это последовательность случайных событий с конечным числом исходов, когда вероятность наступления каждого события зависит только от предыдущего состояния. В марковских цепях при фиксированном настоящем будущее состояние независимо от прошлого. Визуально цепь Маркова – это направленный взвешенный граф с вершинами в виде событий (состояний) и переходами между ними (ребрами), которые могут случиться с определенной вероятностью. С математической точки зрения марковская цепь – это вероятностный автомат, распределение вероятностей переходов между вершинами этого направленного графа можно представить в виде матрицы. Поскольку цепи Маркова отлично подходят для моделирования случайных событий, они активно применяются во многих доменах.
Неудивительно, что цепи Маркова могут быть полезны при анализе данных пользовательского поведения, в частности, в рамках построения моделей маркетинговой атрибуции, которые позволяют понять, маркетинговые усилия приносят желаемый результат. Можно сказать, что модель маркетинговой атрибуции — это механизм для определения ценности различных маркетинговых усилий, от контекстной рекламы до email-кампаний. Такой анализ помогает понять, какой именно канал привлечения (реклама в ТГ-чате, баннер РСЯ, почтовая рассылка или реферальная программа) превратил посетителя в покупателя. В результате такого анализа маркетолог может сделать объективные выводы о наиболее эффективном канале маркетингового привлечения для конкретного продукта или сегмента целевой аудитории и повысить ROMI (Return Of Marketing Investments). Эти модели строятся по событиям пользовательского поведения и следуют по пути пользователя, а точками данных здесь являются факты взаимодействия пользователя с продуктом рекламного привлечения.
В зависимости от количества точек взаимодействия в пути пользователя его можно классифицировать как путь пользователя с одной или несколькими точками взаимодействия. Маркетологи выделяют несколько способов построения моделей маркетинговой атрибуции: по первому взаимодействию, по последнему взаимодействию, по всем точкам контакта или строят собственные кастомизированные модели.
Моделирование маркетинговой атрибуции предполагает назначение веса точкам взаимодействия с клиентом на его пользовательском пути к нужному бизнесу результату (покупка товара, заказ услуги и прочие результаты конверсии). В моделях атрибуции с одним касанием (первым или последним) 100% веса относится только к единственной точке взаимодействия с клиентом на его пользовательском пути. А в многоточечных моделях этот вес распределяется между всеми точками взаимодействия в соответствии с правилом конкретной модели: учитываются все точки взаимодействия, но распределение веса варьируется.
В традиционных моделях методология присвоения веса ограничена определенными правилами. В моделях, управляемых данными это решается сложными алгоритмами. Поэтому модели, основанные на данных, более точны по сравнению с традиционными. Существует множество моделей атрибуции на основе данных:
- Upstream Data-Driven Attribution (UDDA) – атрибуция на основе данных восходящего потока;
- Time to Event Data Driven Attribution (TEDDA) – атрибуция на основе данных о времени до события;
- Shapley value — значение Шепли, концепция решения в кооперативной теории игр, согласно которому выигрыш оптимально распределяется между игроками согласно среднему вкладу каждого игрока в благосостояние тотальной коалиции при определенном механизме её формирования.
- цепи Маркова.
Принимая во внимание случайный и вероятностный характер процесса продвижения клиента по его пользовательскому пути, Марковская цепь предлагает наиболее рациональный подход к атрибуции маркетинговых усилий. По сути, все пользовательские пути клиентов в наборе данных моделируются в виде ориентированных графов, где узлы представляют точки взаимодействия (состояния), а соединительные ребра графа представляют вероятность перехода между ними. При этом следует помнить два основных свойства классической марковской цепи:
- отсутствие памяти, т.е. вероятность будущего не зависит от прошлого при данном текущем состоянии;
- эффект удаления, который помогает определить эффективность маркетингового канала, удаляя его с графика и моделируя путь клиента, чтобы измерить изменение показателя успешности в отсутствие канала.
Как реализовать эти идеи на практики, посмотрим на примере построения модели маркетинговой атрибуции в интерактивном блокноте Google Colab.
Пример Google Colab
Построим пример модели маркетинговой атрибуции в интерактивном блокноте Google Colab, используя библиотеки pandas, networkx и matplotlib. Предположим, у нас имеются исходные данные о том, как пользователь пришел на сайт: страницы предлагаемых товаров (обучающих курсов) и блога. Также в данных уже рассчитана вероятность перехода.
Следующий код показывает, как решить задачу определения вклада каждого канала (телеграмм, блог, email-рассылка, видео с YouTube), что означает модель маркетинговой атрибуции по первому касанию. Сперва импортируем библиотеки, внесем исходные данные в массив и построим на его основе датафрейм, который будет использоваться для дальнейшего анализа.
Затем визуализируем исходные данные, построим марковскую цепь пользовательского поведения как направленный граф с помощью библиотеки Networkx, сгруппируем данные по каналам привлечения и построим гистрограмму.
import networkx as nx
import matplotlib.pyplot as plt
import pandas as pd
data = [('TG','COURSE_1',0.5),('RSA','COURSE_2',0.3),('Blog','COURSE_2',0.7),('Blog','COURSE_1',0.4),
('Blog','COURSE_4',0.4),('TG','COURSE_2',0.2),('Email','Blog',0.3),('RSA','COURSE_3',0.2),
('Blog','Blog_Page_2',0.1),('YouTube','COURSE_1',0.2),('Email',' COURSE_6',0.3),('TG','COURSE_4',0.2),
('RSA','COURSE_3',0.2),('Blog','COURSE_4',0.9),('Blog',' COURSE_6',0.9),('Email',' COURSE _3',0.3)
]
df = pd.DataFrame(data=data,columns=['Channel','Page','Weigth'])
graph=nx.DiGraph()
graph.add_weighted_edges_from(data)
pos = nx.spring_layout(graph, k=1000)
nx.draw(graph, pos, with_labels=True)
plt.show()
#df = pd.DataFrame(data)
print(df)
a=df.groupby(['Channel']).sum(sum(df['Weigth']))
print(a)
x = [i for i in range(len(a))]
plt.bar([i for i in range(len(a))], a['Weigth'])
plt.plot(a)
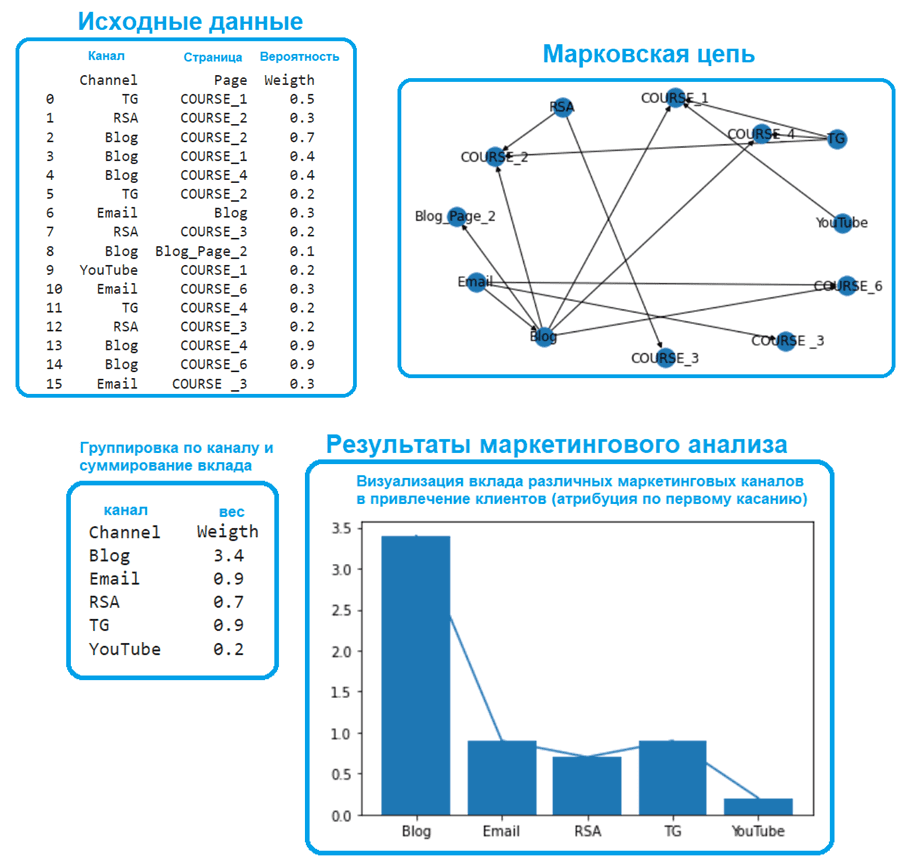
Полученные результаты анализ показывают, что наиболее эффективным каналом привлечения является блог компании с полезными статьями, поскольку именно он в большинстве случаев является точкой входа потенциальных клиентов на сайт. Поэтому целесообразно и дальше развивать этот маркетинговый канал, что мы и делаем в рамках этого материала.
Разумеется, в реальных проектах данные, полученные из нескольких источников (Google Analytics, Яндекс.Метрика, система email-рассылки, TG-каналы и пр.) будут иметь намного больший объем. Также помимо сбора и предварительной обработки этих данных к анализу, также нужно будет вычислить вероятность перехода, чтобы построить марковскую цепь. Тем не менее, даже с учетом этих упрощений, рассмотренный пример отлично иллюстрирует полезную идею повышения эффективности маркетинговых усилий за счет построения моделей атрибуции с помощью анализа данных. Как сделать это самостоятельно, а также применять другие методы и средства анализа графов для аналитики больших данных в реальных проектах, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

