
Современная аналитика больших данных ориентируется на обработку Big Data в реальном времени. Такие вычисления «на лету» позволяют в режиме онлайн узнавать о критически важных производственных показателях и оперативно понимать клиентские потребности. Это существенно ускоряет и автоматизирует цикл принятия управленческих решений в соответствии с требованиями сегодняшнего бизнеса. Обычно для реализации архитектуры потоковой обработки данных используются распределенные масштабируемые и надежные технологии Big Data, такие как Apache Kafka и Spark Streaming. Читайте далее, как на их основе нью-йоркская платформа веб-рекламы Outbrain разработала собственную систему онлайн-аналитики и при чем здесь Graceful shutdown.
На чем стоит ретаргетинг: потоковая аналитика больших данных в онлайн-рекламе
Чтобы показать важность аналитики событий в реальном времени для компании Outbrain, прежде всего поясним суть ее бизнеса. По сути, Outbrain является биржей рекламных ссылок, выступая в качестве посредника между рекламодателями и рекламными площадками. При этом размещение рекламных ссылок в контент происходит автоматически, с учетом пользовательских интересов на основании истории запросов, просмотров страниц, кликов и других подобных событий [1]. Так реализуются ретаргетинговые рекламные кампании, нацеленные на «возвращение» посетителя, интересующегося конкретным товаром. Считается, что эффективность ретаргетинга существенно выше чем других видов рекламы, поскольку идет персонализированное обращение к потенциальному покупателю, уже заинтересованному в продукте. Среди клиентов рекламной биржи Outbrain встречаются такие известные компании как DHL, FIAT, NESTLE, Mercedes-Benz, AVON, Vodafone, Volvo и множество других компаний из различных секторов экономики [2].
Аналитика больших данных для руководителей
Код курса
BDAM
Ближайшая дата курса
4 августа, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Поскольку рекламные ссылки в ретаргетинговых кампаниях зависят от поведения пользователя, бирже необходим инструмент для его быстрого анализа. В Outbrain решили реализовать такую систему онлайн-аналитики на базе Apache Kafka, Spark Streaming и Druid – высокопроизводительной аналитической СУБД, которая позволяет обрабатывать и визуализировать данные в реальном времени. Apache Druid может «на лету» получать информацию из топиков Kafka и наглядно визуализировать данные благодаря модулю Pivot. В частности, запускать специальные запросы по различным измерениям: аналитические срезы, кубы и т.д. На практике это полезно, например, для анализа эффективности конкретной рекламной кампании в определенных странах. Данные извлекаются в режиме реального времени с небольшой задержкой (около минуты). Но, прежде чем отправить данные о пользовательском поведении из Kafka в Druid, их нужно дополнить сведениями из других источников, т.е. обогатить. Для этого было решено использовать Spark Streaming. Однако, несмотря на типовой характер такого Big Data решения для потоковой аналитики больших данных, на практике Outbrain столкнулась с проблемами потери информации в случае сбоя кластера [3]. Далее мы рассмотрим, как эти ограничения были устранены с помощью механизма «плавного отключения» (Graceful shutdown), доступного в Spark Streaming.
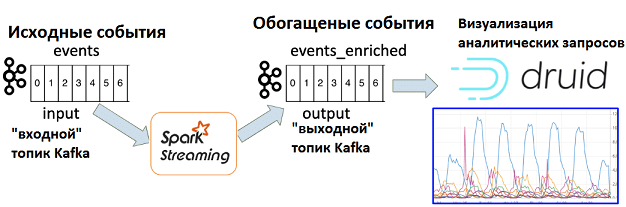
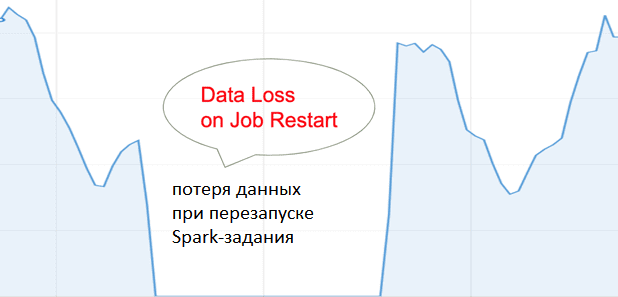
Чем опасны сбои заданий Spark Streaming при потоковой обработке данных из Apache Kafka
В теории считается, что задания потоковой обработки данных в Spark Streaming выполняются непрерывно. В случае конвейера Kafka-Spark, приложение Spark Streaming постоянно считывает события из входного топика Kafka, обрабатывает их и записывает результаты в выходной топик. Однако, в реальности в Spark-кластере может возникнуть сбой, что вызовет перезапуск задания. При этом возникнет потеря части данных, которые должны быть обработаны, т.к. за время перезапуска задания Spark, события продолжают записываться в топик Kafka.
Напомним, события в Kafka хранятся в топиках (topic), каждый из которых разбит на разделы (partition). Каждое сообщение (запись) в разделе имеет смещение (offset) – порядковый номер, определяющий порядок записи. Обрабатывать смещения можно несколькими способами: считывать последний offset (по умолчанию) или сохранить смещения, чтобы учесть эту информацию при перезапуске задания и продолжить обработку без потери данных.
При считывании последнего смещения в условиях постоянного появления новых данных возможно появление дубликатов. Это приведет к некорректным результатам аналитики и визуализации, что может ввести в заблуждение бизнес-потребителей, повлиять на их решения и снизить уровень доверия к системе. Поэтому следует не полагаться на функцию автоматической фиксации смещений Kafka, а фиксировать их самостоятельно с учетом особенностей того, как Spark Streaming считывает данные из топиков.
Потоковая обработка в Apache Spark
Код курса
SPOT
Ближайшая дата курса
25 августа, 2025
Продолжительность
16 ак.часов
Стоимость обучения
48 000
В Spark Streaming основным архитектурным концептом является дискретизированный поток (DStream, Discretized Stream), представленный непрерывной серией RDD (Resilient Distributed Dataset, надежная распределенная коллекция данных типа таблицы). Большинство заданий Spark Streaming выглядят примерно так:
dstream.foreachRDD { rdd =>
rdd.foreach { record => process(record)}
}
В рассматриваемом примере обработка записи означает запись записи в выходной топик Kafka. Чтобы зафиксировать смещения Kafka, нужно сделать следующее:
dstream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreach { record => process(record)}
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
Таким образом, при правильной обработке смещений они сохраняются после каждой операции с RDD. Но в случае сбоя, когда задание останавливается в середине обработки RDD, часть микропакета (micro-batch) записывается в выходной топик Kafka и не фиксируется. Как только задание будет запущено снова, оно обработает некоторые сообщения снова, что приведет к появлению дубликатов. Предотвратить это можно с помощью механизма «плавного» завершения Spark-заданий, который называется Graceful shutdown [3]. Как он работает и чем еще полезен, мы рассмотрим завтра. А про особенности SQL-операций в Apache Druid поговорим здесь.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
8 сентября, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000
Больше практических подробностей по администрированию, разработке и эксплуатацию Apache Spark с Kafka для потоковой аналитики больших данных в проектах цифровизации своего бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

