 723
723 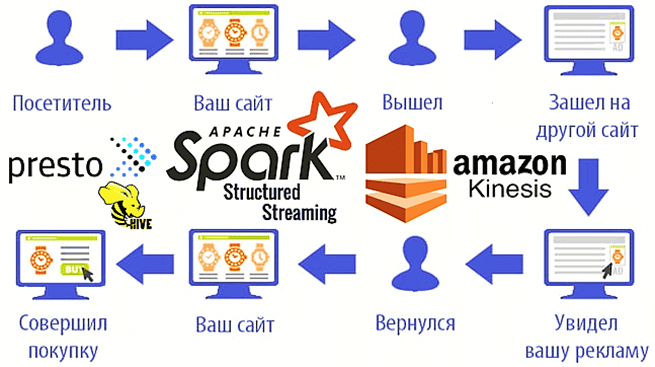
Содержание
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon, создавая конвейеры потоковой передачи и аналитики больших данных с использованием готовых соединителей и операторов, а также компонентов экосистемы Apache Hadoop — Presto и Hive.
Еще раз о том, что такое ретаргетинг и при чем здесь Big Data c Machine Learning
Ретаргетинг в сфере e-commerce – это техника убеждения потенциальных клиентов вернуться на веб-сайт после того, как этот ресурс был закрыт без покупки или другого конвертирующего действия (оставить заявку, подписаться на рассылку и пр.). Главное в ретаргетинговых стратегиях – знать, кому и когда показывать рекламу. Чтобы такое рекламное обращение к клиенту было эффективным, многие маркетинговые компании сегодня прибегают к прогнозированию намерений пользователя в реальном времени. Для этого используются алгоритмы машинного обучения (Machine Learning). За сбор и подготовку датасетов для таких ML-моделей предиктивной аналитики отвечают технологии больших данных, обеспечивающие их сбор, агрегацию и обработку в режиме онлайн: Apache Kafka и Spark Streaming, а также ее более современная модификация – Spark Structured Streaming. Чем отличаются Apache Spark Streaming и Spark Structured Streaming, мы рассматривали здесь.
Для сбора событий пользовательского поведения на сайт требуется, чтобы каждая страница на этом веб-ресурсе имела крошечный участок Javascript-кода (пиксель). Маркетинговые компании, такие как MIQ, вместе с рекламодателями и сторонними игроками размещают эти пиксели на своих сайтах. Пиксельный сервер MIQ прослушивает пиксельные вызовы и постоянно генерирует из них события, чтобы направить их в систему очередей, например, AWS Kinesis [1]. Как это работает, разберем далее.

Конвейеры Spark Structured Streaming на базе платформы Qubole
Apache Spark Structured Streaming может иметь разные источники входных данных: Kafka, Amazon S3 или Amazon Web Services (AWS) Kinesis, который используется в MIQ. Напомним, Kinesis – это платформа для работы с потоковыми данными в AWS. Она предлагает сервисы, которые обеспечивают легкую загрузку и анализ потоковых данных, а также позволяет создавать свои настраиваемые приложения для решения специфических задач при обработке потоковых данных с веб-приложений, мобильных и IoT/IIoT-устройств, промышленных датчиков, различных платформ и сервисов. Amazon Kinesis может непрерывно собирать, сохранять и обрабатывать до нескольких терабайтов в час легко и с малыми затратами. В состав AWS Kinesis входит целый ряд сервисов Amazon для сбора и аналитики больших данных в режиме реального времени, в зависимости от их источника (видеопоток, журналы приложений, телеметрия веб-сайтов и пр. числовые данные, информация с технических устройств). За аналитическую обработку потоков данных «на лету» отвечает инструментарий SQL-запросов, NoSQL-СУБД Elasticsearch, а также фреймворков Apache Spark и Flink, развернутых в веб-сервисах Amazon [2].
Следующий пример кода показывает, как считать данные из AWS Kinesis напрямую в датафрейм Spark [1]:
var ds_kinesis = spark .readStream .format(“kinesis”) .option(“streamName”, kinesisStreamName) .option(“endpointUrl”, endpointUrl) .option(“regionName”, kinesisRegion) .option(“startingPosition”, “earliest”) .option(“kinesis.executor.maxFetchTimeInMs”, 10000) .option(“kinesis.executor.maxFetchRecordsPerShard”, 500000) .option(“kinesis.executor.maxRecordPerRead”, 10000) .load()
Интересно, что ретаргетинговая компания MIQ запускает этот код в инфраструктуре Qubole Pipelines, которая помогает создавать конвейеры потоковой передачи из пользовательского интерфейса с использованием готовых соединителей и операторов (в режиме поддержки). Платформа Qubole предоставляет высокоинтегрированный набор инструментов, которые помогут анализировать данные и создавать надежные приложения на основе данных в облаке. Qubole Data Service (QDS) заботится об организации и управлении облачными ресурсами, позволяя аналитикам Big Data сосредоточиться на поиске полезных для бизнеса-инсайтов и практического использования больших данных.
В частности, QDS подходит для исследования данных из различных источников, анализа данных, запуска вычислительных кластеров и управления ими, выполнения повторяющихся команд и использования notebook’ов для сохранения, совместного использования и повторного выполнения набора запросов к источнику данных. Qubole предлагает множество готовых решений для построения аналитических конвейеров, ускоряя возможность из запуска в production-среде, в т.ч. с помощью настраиваемых коннекторов, источников и приемников, управляемых предупреждений, контрольных точек и пр.[3].
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
16 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Возвращаясь к ретаргетину, еще раз отметим важность понимания целевой аудитории клиентов. Основываясь на опыте, а также на экспериментах, команда специалистов по Data Science в компании MIQ построила с помощью Apache Spark прогностическую модель сегментации пользователей в реальном времени. Сперва применяется схема, а затем выполняются необходимые преобразования для создания предикторов (фичей) ML-модели [1]:
val mySchema = (new StructType)
.add("pixel_id", StringType)
.add("dt", StringType)
.add("uid", StringType)
.add("hostname", StringType)
.add("accept_language", StringType)
.add("user_agent", StringType)
.add("timestamp", StringType)
.add("referrer", StringType)
.add("xwap_profile", StringType)
…val df1_kinesis = df_kinesis.select(from_json($"data", mySchema).as("data2"), $"approximateArrivalTimestamp").select("data2.*", "approximateArrivalTimestamp").withColumn("date", $"approximateArrivalTimestamp".cast("timestamp")).withColumn("year", year(col("date")))
// Business logic model below
…
Не только предиктивный ретаргетинг: еще больше аналитики больших данных в реальном времени с Hadoop-компонентами Apache Presto и Hive
Протестировав успешность прогнозирующего ретаргетинга на вышеописанных технологиях Big Data, сотрудники MIQ выявили ряд новых сценариев использования для глубокого анализа данных из AWS Kinesis в реальном времени. Для этого было решено использовать другие компоненты экосистемы Apache Hadoop, такие как SQL-движок Presto и NoSQL-СУБД Hive. Apache Presto – это механизм интерактивного выполнения распределенных параллельных аналитических запросов, оптимизированный для малой задержки. Примечательно, что один запрос Presto может обрабатывать данные из нескольких источников данных, от файловой системы Hadoop HDFS до реляционных и NoSQL-СУБД, в т.ч. Apache Hive.
Для этого в MIQ вместе с прогнозированием намерения пользователя в реальном времени конвейер также записывает данные в Parquet-формате в секционированное местоположение Amazon S3 [1]:
val query = df1_kinesis.writeStream .outputMode(“Append”) .trigger(ProcessingTime(“60 seconds”)) //write micro batches every 1 min .format(“parquet”) // write as Parquet partitioned by date .partitionBy(“year”, “month”, “day”, “hour”) .option(“path”, parquetOutputPath) .option(“checkpointLocation”, checkPointPath) .start()
Поверх этого хранилища создана Hive-таблица со структурой разделов, описывающих время события, например, s3: // data / year = 2020 / month = 08 / day = 31 / hour = 10. Запланированное задание ежедневно добавляет разделы в Hive-таблицу, чтобы обеспечить некоторый запас времени на случай сбоя. Из потокового конвейера файлы S3 продолжают добавляться в ежечасные папки в S3 в соответствии с интервалом микропакетов, который составляет 60 секунд (ProcessingTime).
Apache Presto позволяет анализировать данные из созданных Hive-таблиц, куда они постоянно вносятся в режиме реального времени. При том, что данные и записываются в Amazon S3 каждую минуту, это не всегда отражает время, когда событие случилось в реальном мире. Для этого используются конфигурационные настройки Apache Hive: hive.metastore-refresh-interval и hive.metastore-cache-ttl. В MIQ оба значения установлены на 5 минут. Это означает, что данные о событиях запрашиваются почти в реальном времени с максимальной задержкой 5 минут, что подходит для всех случаев ретаргетинга.
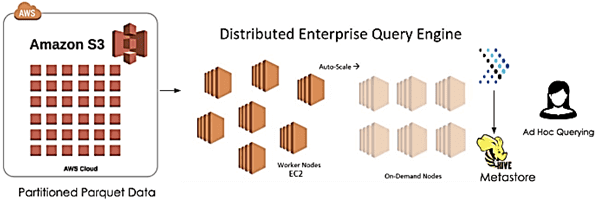
По итогам тестирования и production-эксплуатации этого решения, дата-инженеры MIQ особенно отмечают его масштабируемость и высокую производительность (500–1000 запросов в час). Разумеется, скорость выполнения запросов зависит от множества факторов: объем запрашиваемых данных, узлов кластера и пр. Однако в целом, благодаря бесшовной интеграции всех описанных технологий Big Data в облачных сервисах Amazon, ретаргетинговой компании удалось успешно построить эффективный конвейер сбора и аналитической обработки больших данных для прогнозирования пользовательского поведения. Завтра мы продолжим разговор про применение технологий Big Data и Machine Learning в рекламе и маркетинге и рассмотрим пример прогнозирования конверсии в реальном времени с помощью Apache Kafka, Spark и компонентов ELK-стека (Elasticsearch, Logstash, Kibana).
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
16 марта, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Узнайте больше про конвейеры машинного обучения и потоковой аналитики больших данных с Apache Hadoop и Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка в Apache Spark
- Основы Apache Spark для разработчиков
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Hadoop SQL администратор Hive
- Анализ данных с Apache Spark
- Машинное обучение в Apache Spark
Источники
- https://medium.com/miq-tech-and-analytics/user-intent-prediction-retargeting-via-spark-structured-streaming-6bce1cddba8b
- https://aws.amazon.com/ru/kinesis/
- https://docs.qubole.com/en/latest/user-guide/qds/

