
Каждому специалисту по Data Science и инженеру данных знакома Python-библиотека pandas. Однако, для работы с большими данными она не очень подходит из-за высокого потребления памяти. Тем не менее, отказаться от старых привычек сложно. Поэтому разбираемся, зачем использовать API Pandas в Apache Spark и как это сделать наиболее эффективно. Чем отличается...

Зачем делать моментальные снимки состояния распределенной файловой системы Apache Hadoop, почему не стоит создавать снапшоты HDFS в корневом каталоге и как найти оптимальную частоту сохранения состояния больших данных. Как устроен механизм снапшотов в HDFS Чтобы повысить надежность системы, ее состояние необходимо периодически сохранять. Для баз данных и файловых систем эта...
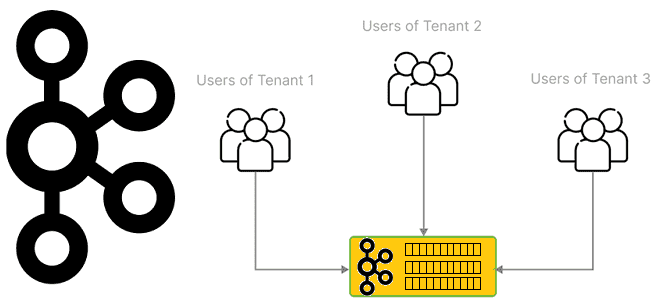
Что такое мультитенантность и как администратору Apache Kafka настроить изоляцию арендаторов в мультиарендном кластере: конфигурации, квоты и лайфхаки. Что такое мультиарендность и как реализовать эту модель для кластера Kafka Мультитенантность (мультитенантность, multitenancy) переводится с английского как множественная аренда и в контексте архитектуры ПО означает разделение одного экземпляра приложения между несколькими...

Зачем Apache Flink очередной API для создания распределенных приложений с отслеживанием состояния, чем он полезен и при чем здесь Kubernetes: ликбез по Stateful Functions. Apache Flink Stateful Functions Stateful Functions в Apache Flink – это API, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для...
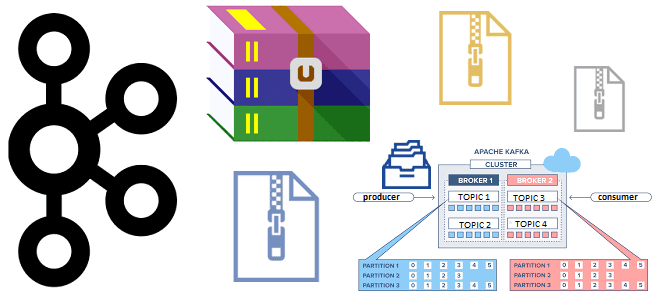
Зачем сжимать сообщения при их публикации в Apache Kafka, как устроен механизм сжатия и какие конфигурации задавать для его эффективного использования. Сжатие сообщений в Kafka: причины использования и принципы работы Единицей параллелизма в Apache Kafka является раздел топика, куда приложение-продюсер отправляет сообщение, чтобы его мог считать потребитель, назначенный на этот...

Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования. Apache Flink vs Spark: сходства и отличия Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее...

Как разница между Scala и Java отражается на работе Spark-приложения, почему код на Scala работает быстрее и когда выбирать этот язык программирования для разработки приложений аналитики больших данных. Scala vs Java: ключевые отличия Хотя Apache Spark позволяет разработчику писать код на нескольких языках программирования (Scala, Java, R, Python), сам фреймворк...
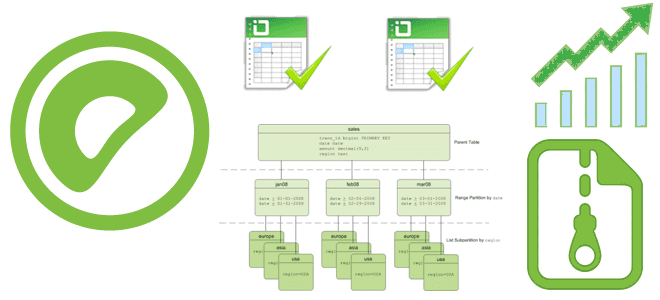
Как включить сжатие данных в Greenplum, какие алгоритмы сжатия поддерживает эта MPP-СУБД и можно ли установить разные параметры сжатия для отдельных столбцов и разделов больших таблиц. Примеры SQL-запросов и рекомендацию по настройке. Как Greenplum сжимает данные: примеры настроек и SQL-запросов Эффективное сжатие данных позволяет Greenplum снижать потребление памяти и повышать...
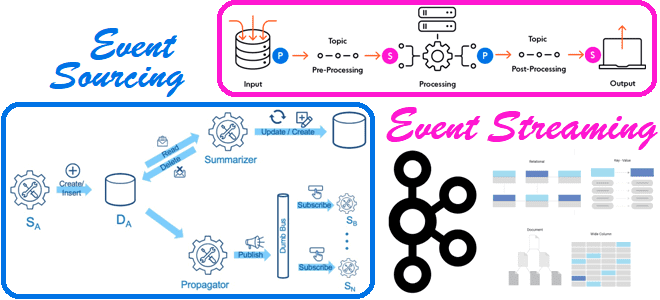
В чем разница между потоковой передачей событий и источником событий и при чем здесь Apache Kafka: разбираемся с паттернами проектирования событийно-ориентированной архитектуры. 2 паттерна проектирования EDA-архитектуры Напомним, что сегодня для построения сложных систем, зачастую состоящих из множества взаимодействующих компонентов, и реактивно реагирующих на события внешнего мира, активно используется идея архитектуры,...

13 сентября 2023 года вышел Apache Spark 3.5. Знакомимся с самыми важными новинками свежего релиза: расширения Spark Connect и SQL, поддержка DeepSpeed, улучшения потоковой передачи и свежие UDF-функции Python. ТОП-5 новинок Apache Spark 3.5.0 В Apache Spark 3.5. добавлено много исправлений и улучшений, а также реализованы новые функции. Наиболее интересными...