
Зачем Apache Flink очередной API для создания распределенных приложений с отслеживанием состояния, чем он полезен и при чем здесь Kubernetes: ликбез по Stateful Functions.
Apache Flink Stateful Functions
Stateful Functions в Apache Flink – это API, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для бессерверных архитектур. Этот API объединяет преимущества потоковой обработки больших наборов данных с отслеживанием состояния со средой выполнения для моделирования stateful-объектов, которая поддерживает прозрачность их местоположения, параллелизм, масштабирование и отказоустойчивость. Stateful Functions подходит для работы с облачными развертываниями и FaaS-платформами, управляемыми событиями, такими как AWS Lambda и KNative, а также для обеспечения готового согласованного состояния и обмена сообщениями, сохраняя бессерверный подход и гибкость.
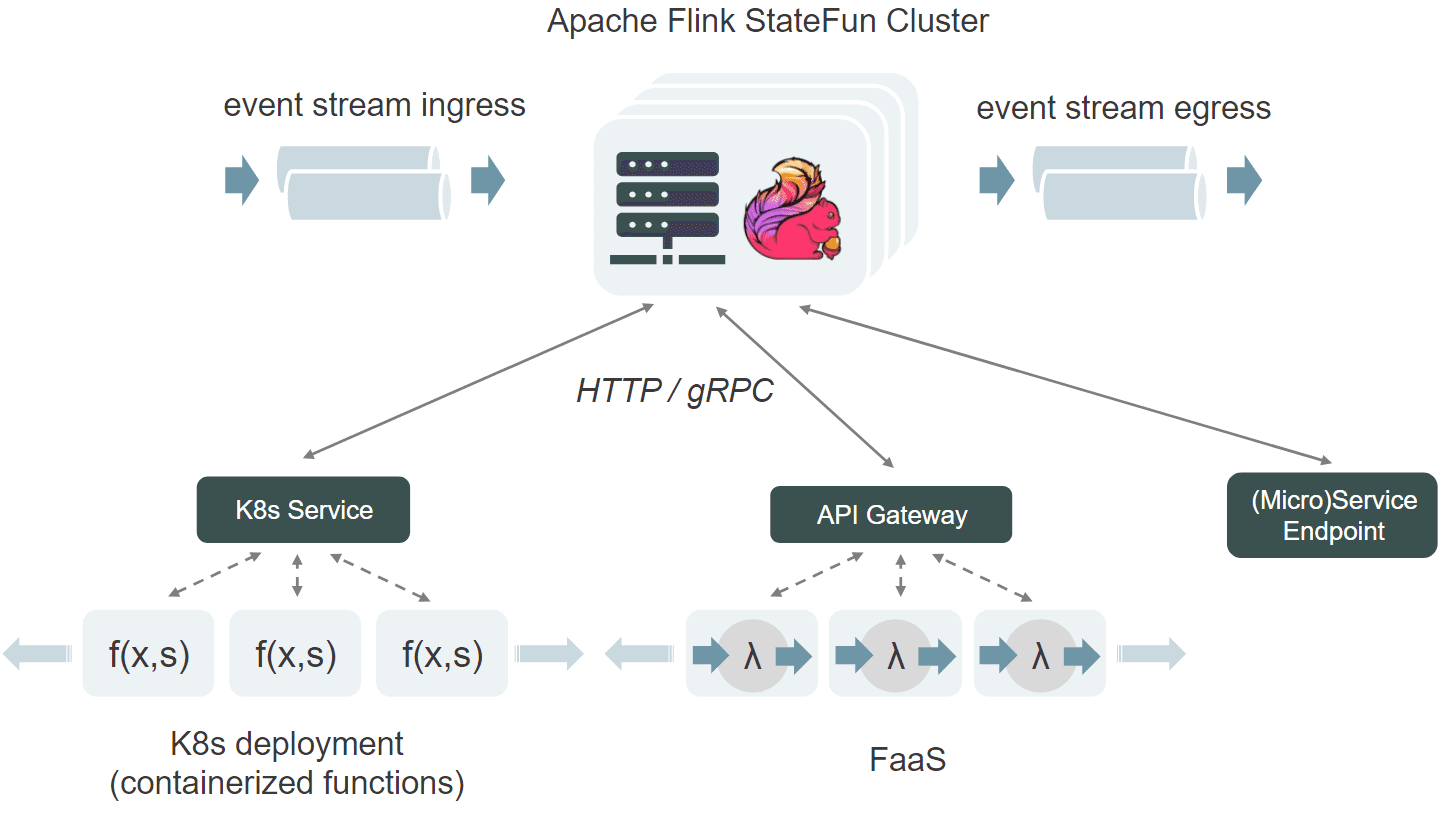
Методы API являются строительными блоками приложений, атомарными единицами изоляции, распределения и устойчивости. Как объекты, они инкапсулируют состояние одного объекта, например, конкретного пользователя, устройства или сеанса, и кодируют его поведение. Stateful Functions могут взаимодействовать друг с другом и с внешними системами посредством передачи сообщений. Поэтому Stateful Functions отлично подходит для реализации EDA-архитектуры, управляемой событиями.
Одной из основных сильных сторон Apache Flink является его способность обеспечивать отказоустойчивое локальное состояние. Находясь внутри функции, пока она выполняет некоторые вычисления, разработчик всегда работает с локальным состоянием в локальных переменных, что гораздо проще обработки распределенного состояния. В случае сбоя все сохраненные состояния и сообщения откатываются, чтобы имитировать полностью безотказное выполнение. Эти гарантии отказоустойчивости позволяют отказаться от постоянного хранилища, т.е. базы данных. Вместо этого Stateful Functions использует проверенный механизм создания моментальных снимков Apache Flink.
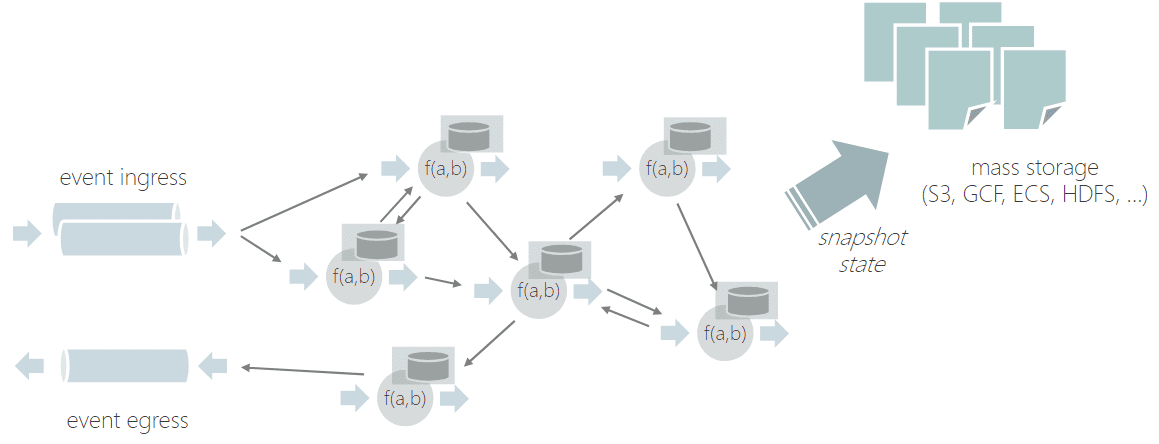
Объекты Stateful Functions распределяются логически, т.е. система может поддерживать неограниченное количество экземпляров с ограниченным количеством ресурсов. Логические экземпляры не используют ЦП, память или потоки, когда они не вызываются активно, поэтому не существует теоретического верхнего предела количества создаваемых экземпляров.
В локальной среде адрес объекта совпадает со ссылкой на него. Но в приложении с функциями с отслеживанием состояния экземпляры функций являются виртуальными, и их местоположение во время выполнения не раскрывается пользователю. Вместо этого Address используется для ссылки на конкретную функцию состояния в системе.
Адрес состоит из двух компонентов: FunctionType и ID. Тип функции аналогичен классу объектно-ориентированного языка; он объявляет, на какую функцию ссылается адрес. Идентификатор — это первичный ключ, который ограничивает вызов функции конкретным экземпляром типа функции. При вызове функции все действия, включая чтение и запись постоянных состояний, ограничиваются текущим адресом. Например, в приложении Stateful Functions для отслеживания запасов на складе может быть функция Inventory, которая отслеживает количество единиц товара на складе. Тогда для каждой единицы хранения запасов (SKU), которой управляет склад, будет один логический экземпляр этого типа. С каждым экземпляром можно взаимодействовать и отправлять сообщения независимо. Приложение может создавать столько экземпляров, сколько типов предметов есть в ассортименте.
Архитектура и развертывание приложений Stateful Functions
Логически функции не создаются и не уничтожаются, а всегда существуют на протяжении всего времени существования приложения. При запуске приложения каждый параллельный рабочий процесс платформы создает по одному физическому объекту для каждого типа функции. Этот объект будет использоваться для выполнения всех логических экземпляров этого типа, запускаемых этим конкретным работником. Когда сообщение отправляется по адресу в первый раз, это будет так, как если бы этот экземпляр существовал всегда, а его постоянные состояния были пустыми. Очистка всех сохраненных состояний типа аналогична его уничтожению. Если экземпляр не имеет состояния и не работает активно, он не занимает ни процессор, ни потоки, ни память. Экземпляр с данными, хранящимися в одном или нескольких постоянных значениях, занимает только ресурсы, необходимые для хранения этих данных. Хранилище состояний управляется средой выполнения Apache Flink и хранится в настроенном бэкэнде, например, key-value базе RocksDB, о чем мы писали здесь.
Stateful Functions использует уникальный подход к разделению логики и состояния приложения, логически совмещая состояние и вычисления, но физически разделяя их. Логическое совместное размещение обеспечивается через обмен сообщениями, доступ к состоянию/обновлению и вызовы функций. Состояние разделяется по ключу, и сообщения направляются в состояние по ключу. Для каждого ключа одновременно существует один писатель, который также планирует вызовы функций. Физическое разделение обеспечивается тем, что функции могут выполняться удаленно, при этом доступ к сообщениям и состоянию предоставляется как часть запроса на вызов. Таким образом, функциями можно управлять независимо, как и процессами без сохранения состояния.
Сами функции с состоянием могут быть развернуты различными способами, которые компенсируют определенные свойства друг с другом: слабая связь и независимое масштабирование, с одной стороны, с накладными расходами на производительность, с другой. Каждый модуль функций может быть разного типа, поэтому некоторые функции могут выполняться удаленно, а другие — встроенно.
Удаленные функции используют вышеупомянутый принцип физического разделения при сохранении логического совместного размещения. Уровень состояния/обмена сообщениями, т. е. процессы Flink и уровень функций развертываются, управляются и масштабируются независимо. Вызовы функций происходят через протокол HTTP/gRPC и проходят через службу, которая направляет запросы на вызов в любую доступную конечную точку, например службу Kubernetes (балансировка нагрузки), шлюз запросов AWS для Lambda и т.д. Поскольку вызовы являются автономными, целевые функции можно рассматривать как любое приложение без сохранения состояния.
Альтернативный способ развертывания функций — совместное размещение с процессами JVM Flink. В такой настройке каждый диспетчер задач Flink, развернутый в поде Kubernetes в контейнере Flink, будет общаться с одним функциональным процессом через локальную сеть пода. Этот режим поддерживает разные языки, избегая маршрутизации вызовов через балансировщик, но он не может масштабировать состояние и вычислять части задания независимо. Такой стиль развертывания аналогичен тому, как Flink Table API и уровень переносимости API Beam развертывают и выполняют функции, не относящиеся к JVM.
Наконец, встроенные функции запускаются в JVM и вызываются напрямую с сообщениями и доступом к состоянию. Это наиболее производительный способ, хотя и за счет поддержки только языков JVM. Обновления функций означают обновление кластера Flink. Можно сказать, встроенные функции похожи на хранимые процедуры в базе данных, но в более принципиальном смысле: функции здесь представляют собой обычные функции Java/Scala/Kotlin, реализующие стандартные интерфейсы, и их можно разрабатывать и тестировать в любой IDE.
19 сентября 2023 года вышло обновление Stateful Functions 3.3.0, которое содержит 10 улучшений, включая обновление до Flink 1.16.2., и исправление уязвимости CVE-2023-41834. Ранее Stateful Functions версий 3.1.0, 3.1.1 и 3.2.0 допускали внедрение HTTP-заголовка из-за неправильной нейтрализации последовательностей CRLF – управляющих символов (байт-код), которые можно использовать для обозначения разрыва строки в текстовых файлах. Злоумышленник мог внедрить вредоносный контент в HTTP-ответ, отправляемый пользователю, например, поддельная форма входа или код JavaScript, который мог украсть учетные данные пользователя или выполнить другие вредоносные действия от имени пользователя. В Apache Flink Stateful Functions 3.3.0 это устранено.
Освойте возможности Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://nightlies.apache.org/flink/flink-statefun-docs-release-3.2/
- https://flink.apache.org/2023/09/19/stateful-functions-3.3.0-release-announcement/
- https://issues.apache.org/jira/secure/ReleaseNote.jspa?projectId=12315522&version=12351276
- https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-41834

