
В заключение цикла статей о сравнении Apache Kafka с Pulsar, сегодня мы перечислим, когда следует предпочесть второй вариант для построения распределенных масштабируемых систем потоковой аналитики больших данных. Также читайте далее, с какими ограничениями придется мириться в случае выбора этого Big Data фреймворка. 5 случаев, когда Apache Pulsar лучше Kafka При...

Вчера мы опровергали мифы о превосходстве молодого Apache Pulsar над зрелой Kafka, наглядно показав, что именно второй Big Data фреймворк больше подходит для построения по-настоящему масштабных и высоконадежных распределенных масштабируемых систем потоковой аналитики больших данных. Тем не менее, благодаря своим архитектурным особенностям Pulsar постепенно завоевывает собственную нишу и становится все...

Оставив за рамками этой статьи бенчмаркинговые войны по оценке производительности Apache Pulsar в сравнении с Kafka и RabbitMQ, сегодня разберем 5 популярных мифов о превосходстве молодого Пульсар над зрелой Кафка – платформой потоковой обработки событий с точки зрения администрирования и эксплуатации. Читайте далее, правда ли управлять кластером Pulsar проще, чем...

Продолжая разбирать сходства и различия Apache Pulsar с Kafka и RabbitMQ, сегодня попытаемся выяснить, какой Big Data фреймворк все-таки лучше: погрузимся в особенности бенчмаркинговых исследований, сравнивающих эти платформы. Читайте далее, почему не стоит безоговорочно доверять локальным бенчмаркинг-тестам оценки производительности и какие факторы действительно нужно учитывать при выборе фреймворка для разработки...

Недавно мы разбирали, что такое Apache Pulsar: архитектуру, принципы работы, сходства и различия с Kafka и RabbitMQ. В продолжение этого разговора, сегодня рассмотрим основные мифы и их опровержения в горячем споре о технологиях Big Data. Читайте далее про холивар Apache Kafka vs Pulsar vs RabbitMQ: что лучше выбрать для построения...

Продвигая наши обновленные курсы по Kafka, сегодня рассмотрим, почему в последнее время эту Big Data платформу потоковой обработки событий стали активно сравнивать с Apache Pulsar. Читайте далее, как устроен этот молодой, но интересный фреймворк потоковой обработки больших данных, чем он отличается от Kafka и RabbitMQ, что между ними общего и...

Вчера мы говорили про сложности развертывания множества stateful-приложений Apache Kafka Streams в кластере Kubernetes и роль контроллера StatefulSet, который поддерживает состояние реплицированных задач за пределами жизненного цикла отдельных подов. В продолжение этой темы, сегодня рассмотрим механизм проб, которые позволяют определить состояние распределенного приложения, развернутого на платформе контейнерной виртуализации. В качестве...
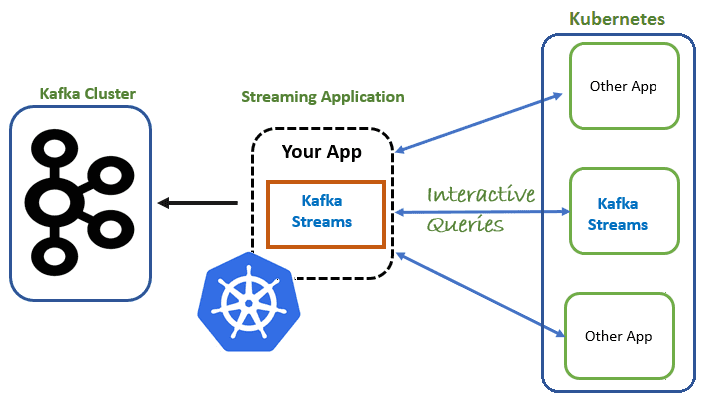
Сегодня рассмотрим особенности запуска приложений Apache Kafka Streams для потоковой обработки больших данных с отслеживанием состояния в кластере Kubernetes. Читайте далее, в чем проблема управления stateful-приложениями Kafka Streams в Kubernetes и как ее решает контроллер StatefulSet. Что обеспечивает хранение состояний в Apache Kafka Streams Напомним, Kafka Streams – это легковесная...
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...

В этой статье поговорим про интеграцию данных с помощью CDC-подхода и репликацию SQL-таблиц из корпоративной СУБД в несколько разных удаленных хранилищ в реальном времени с применением Apache Kafka и Debezium, развернутых в Kafka Connect и Confluent Cloud. Постановка задачи: CDC с Big Data в реальном времени Рассмотрим кейс, который часто...