 1133
1133 
Содержание
Продолжая разбирать сходства и различия Apache Pulsar с Kafka и RabbitMQ, сегодня попытаемся выяснить, какой Big Data фреймворк все-таки лучше: погрузимся в особенности бенчмаркинговых исследований, сравнивающих эти платформы. Читайте далее, почему не стоит безоговорочно доверять локальным бенчмаркинг-тестам оценки производительности и какие факторы действительно нужно учитывать при выборе фреймворка для разработки надежной масштабируемой распределенной системы потоковой аналитики больших данных.
Яблоки или апельсины: бенчмаркинговый тест Confluent
Вчера мы упоминали, что из-за разницы архитектур и моделей работы с сообщениями прямое сравнение Apache Pulsar с Kafka и RabbitMQ напоминает спор о яблоках и апельсинах. Тем не менее, чтобы доказать превосходство одной системы над другими, вендоры и энтузиасты продолжают выпускать различные бенчмаркинговые тесты.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
8 июня, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
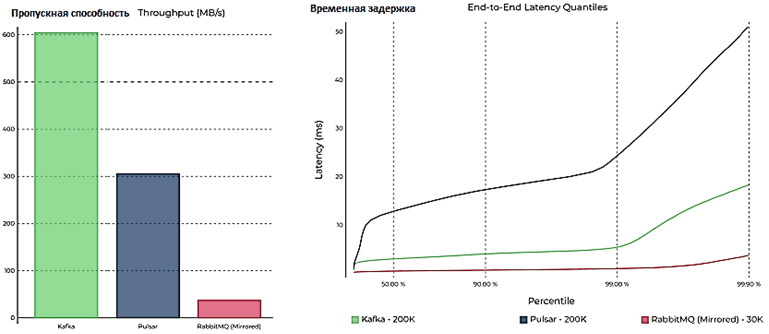
Например, компания Confluent, разработчик множества коммерческих решений вокруг Apache Kafka, в августе 2020 года показала, что пропускная способность этой платформы потоковой обработки событий почти в 2 раза превышает возможности Pulsar и RabbitMQ, а скорость обработки данных – быстрее в 5 раз. Однако, чемпионом по скорости оказался RabbitMQ, в случае зеркалированных очередей. При этом в тестировании на основе бенчмаркингового фреймворка OpenMessaging учтено, что временные задержки RabbitMQ значительно снижаются при пропускной способности выше 30 МБ/с, но при этом брокер сообщений ограничен вычислительной емкостью ЦП. Кроме того, зеркалирование очередей влияет на пропускную способность: меньшие задержки могут быть достигнуты за счет классических очередей без их репликации на несколько узлов кластера. Напомним, такая избыточность обеспечивает отказоустойчивость, позволяя сохранить данные и доступность всей системы при сбое одного из узлов. Кроме того, в бенчмаркинговом сравнении Confluent прокомментировано, что производительность RabbitMQ реализуется в асинхронном режиме и зависит от обмена данными как на стороне производителя, так и на стороне потребителя. И все же в результате сравнения именно Apache Kafka заняла 1-ое место, опередив Pulsar и RabbitMQ по пропускной способности и скорости обработки Big Data [1].
Первенство Pulsar в бенчмаркинге Gigaom vs тонкости fsync-настроек Kafka и пропускной способности всей Big Data системы
Примечательно, что другой подобный тест демонстрирует превосходство Pulsar. В частности, аналитическая компания Gigaom в 2018 году оценила Apache Pulsar и Kafka с помощью того же бенчмаркингового фреймворка OpenMessaging и пришла к совершенно другим выводам [2]:
- показатели максимальной пропускной способности Apache Pulsar в 1,5 раза выше чем у Kafka;
- временная задержка сообщений ниже на 40% и более стабильная;
- масштабируемость Pulsar лучше обеспечивает согласованные результаты для различных размеров сообщений и количества разделов топика.
Однако, презентация результатов этого теста умалчивает, что в данном исследовании не проводилась оптимизация настроек Apache Kafka, которая была намерена замедленна из-за синхронизации каждого сообщения с жестким диском. Установка конфигурационного параметра flush.messages=1 провоцировала вызов fsync (запись каждого отдельного сообщения на жесткий диск) на любой запрос. Это значительно снижает пропускную способность всей системы, особенно в случае пакетов данных от производителей небольшого размера (1 КБ и 10 КБ). Впрочем, при увеличении размера пакетов (100 КБ и 1 МБ) стоимость fsync в Apache Kafka амортизируется, а пропускная способность сравнима с настройками fsync по умолчанию [1].
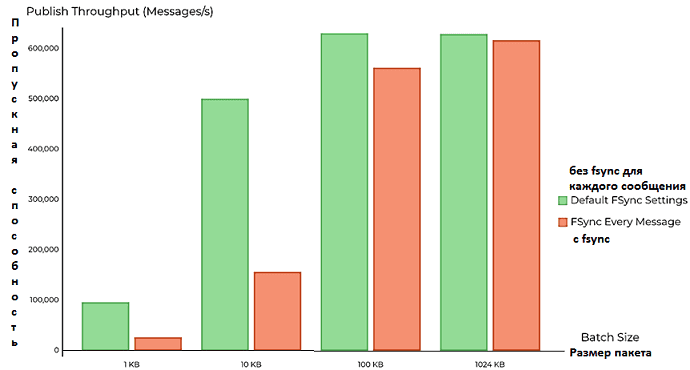
Однако, игнорирование особенностей fsync Kafka в тесте Gigaom вынуждает потребителя работать синхронно, а в случае Pulsar — асинхронно. Поэтому, неудивительно, что в этом бенчмаркинговом сравнении именно Apache Pulsar стал очевидным победителем. Кроме того, при сравнении Big Data фреймворков следует учитывать всю систему в целом, а не только показатели производительности отдельных ее компонентов. В частности, архитектура Pulsar предъявляет повышенные требования к сети передачи данных, активно используя ее из-за проксирования брокеров перед букмекерами BookKeeper, а также удвоенного количества операций ввода-вывода, т.к. BookKeeper записывает данные в WAL-журнал и основной сегмент.
Таким образом, выбирая лучшую производительность в споре Apache Kafka vs Pulsar, стоит помнить об инфраструктуре окружения всей Big Data системы, которую вы хотите построить на базе той или иной платформы. Универсального рецепта не бывает, для каждого конкретного случая будут свои требования, допущения, ограничения и ключевые характеристики, из которых производительность – всего лишь один параметр во всем множестве многофакторной оценки [3].
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Завтра мы продолжим разбираться с особенностями Apache Pulsar и Kafka, анализируя мифы вокруг администрирования и эксплуатации этих фреймворков. А подробно освоить практические детали конфигурирования кластеров и разработки Kafka-приложений для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

