 719
719 
Содержание
Вчера мы опровергали мифы о превосходстве молодого Apache Pulsar над зрелой Kafka, наглядно показав, что именно второй Big Data фреймворк больше подходит для построения по-настоящему масштабных и высоконадежных распределенных масштабируемых систем потоковой аналитики больших данных. Тем не менее, благодаря своим архитектурным особенностям Pulsar постепенно завоевывает собственную нишу и становится все более известным. В этой статье мы собрали для вас 3 реальных примера, когда стартапы и крупные корпорации выбрали Pulsar вместо Apache Kafka.
Почему Nutanix выбрала Apache Pulsar вместо Kafka
В 2019 году Nutanix, американская компания-разработчик аппаратно-программных кластерных виртуализированных комплексов и ПО для построения гиперконвергентной инфраструктуры на базе оборудования массового класса, рассказала о применении Apache Pulsar в своем новом SaaS-продукте под названием Beam. Nutanix Beam – это инструментарий оптимизации затрат при размещении инфраструктуры в облачных сервисах, система мультиоблачного управления, которая анализирует и отображает суммарное потребление облачных ресурсов с детализацией по приложениям, группам и бизнес-модулям. Это позволяет бизнесу и IT-менеджменту правильно оценивать и прогнозировать затраты подразделений и компании в целом на облачные сервисы, чтобы экономить и правильно распределять ресурсы на SaaS/PaaS благодаря встроенным механизмам оптимизации, анализа затрат и неиспользуемых ресурсов [1].
Nutanix Beam основан на микросервисной архитектуре и сетке сервисов (service mesh) с использованием Consul, Nomad, Vault, Envoy и Docker для синхронных RPC-запросов. Для пакетной обработки используются Disque и Conductor, основанные на очередях. К этому требовалось добавить возможности потоковой публикации/подписки, чтобы надежно хранить события и воспроизводить их при необходимости. При этом была необходимость получать сообщения, используя как очереди сообщений, так и модель «Издатель-Подписчик». Поэтому была сделан выбор в пользу Apache Pulsar, где, в отличие от Kafka, поддерживаются обе концепции.
Кроме того, одним из существенных ограничений Apache Kafka является лимит максимальное количество worker’ов по количеству разделов, из-за чего нет возможности подтверждать сообщения на уровне отдельных записей. В Kafka придется вручную фиксировать смещения, поддерживая запись подтверждений отдельных сообщений в собственном хранилище данных, что добавляет слишком много накладных расходов.
Дополнительным аргументом в пользу Pulsar стала модель масштабирования его топиков: в отличие от Apache Kafka, где для каждого топика создаются несколько ресурсов (файлов), что усложняет выборку отдельных данных и увеличивает количество используемых ресурсов. Благодаря наличию сегментного хранилища Apache BookKeeper, в Pulsar количество создаваемых сегментов не зависит от количества топиков. Поэтому именно этот Big Data фреймворк отлично подходит для типового сценария Nutanix Beam, когда из миллиона клиентов для каждого можно легко создать (и удалить) топик, чтобы подписаться на него и оперативно выбрать нужные данные, не используя впустую ресурсы брокеров и потребителей [2].
Курс Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
26 января, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Опыт Yahoo!JAPAN
Японская интернет-компания Yahoo!JAPAN, изначально созданная как совместное предприятие Yahoo! и SoftBank лидирует в стране восходящего солнца: ее веб-портал является самым популярным сайтом, предоставляя пользователям более 100 сервисов.
Для работы с таким большим количеством пользователей нужны высокопроизводительные и масштабируемые сервисы, географически распределенные по нескольким дата-центрам, чтобы гарантировать надежность обработки данных. Проведя собственное бенчмаркинговое сравнение по OpenMessaging фремворку, о котором мы писали здесь, Yahoo!JAPAN предпочла Pulsar вместо Apache Kafka по следующим причинам [3]:
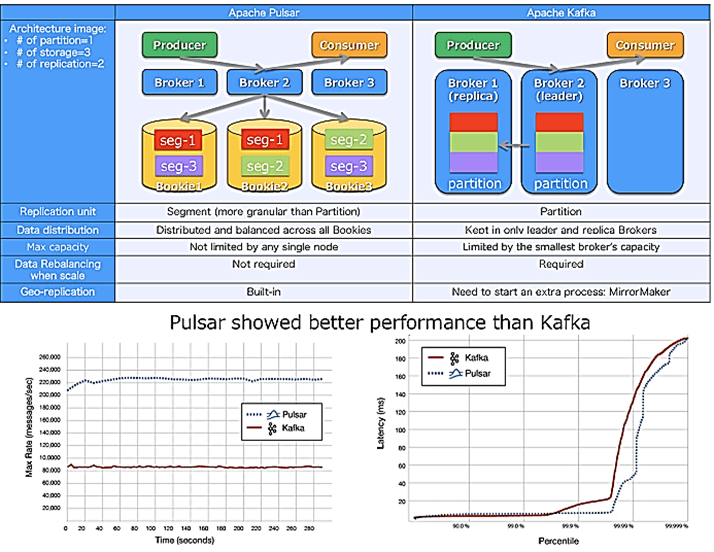
- Pulsar не требует перебалансировки данных между брокерами благодаря наличию Apache BookKepper;
- георепликация в Pulsar является встроенной функцией, тогда как Kafka нуждается в использовании дополнительных решений, например, MirrorMaker, Confluent Replicator, Multi-Region-Clusters или Global Kafka, которыми нужно управлять как дополнительными процессами.
- высокая пропускная способность и низкая временная задержка надежной обработки миллионов топиков с гибкой масштабируемостью благодаря разделению уровней обслуживания и хранения;
- мультиарендность (Multi-tenancy) – несколько сервисов могут использовать одну платформу Pulsar в качестве «арендатора» без организации собственной изолированной систему обмена сообщениями. Apache Pulsar предоставляет различные механизмы аутентификации и авторизации для защиты сообщений от перехвата в рамках пространства имен или топика. Это снижает затраты на обслуживание всей Big Data системы.
- Наличие Pulsar Functions – облегченной вычислительной среды наподобие AWS Lambda или Google Cloud Functions. Это позволяет не запускать дополнительные платформы обработки Big Data, например, Apache Storm или Spark. Достаточно реализовать логику обработки данных в самом Pulsar и развернуть ее в кластере. Pulsar Functions поддерживает языки программирования Java, Python и Go.
Пульсар вместо Кафка в StreamSQL
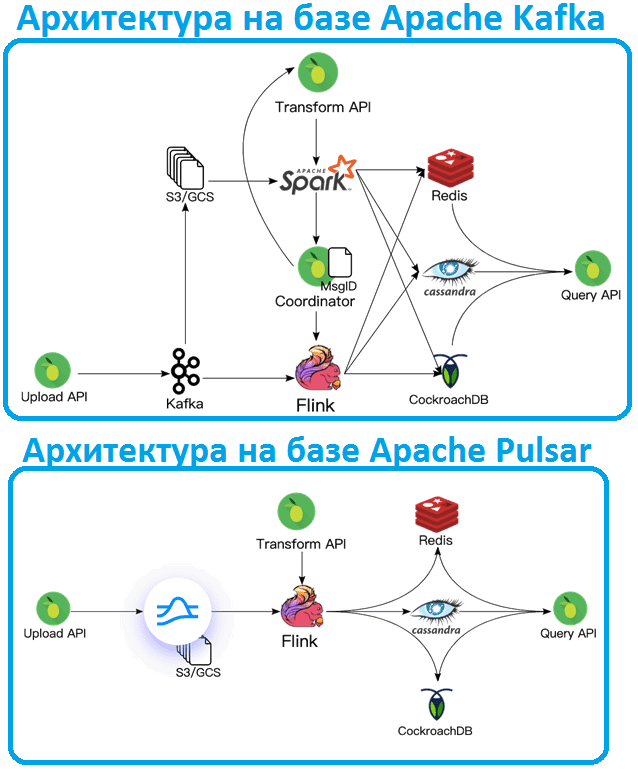
Еще один интересный случай предпочтения Apache Pulsar вместо Kafka отмечают пользователи StreamSQL, это система хранения данных, построенная на базе событий. О вариантах использования StreamSQL в качестве хранилища фичей (Feature Store) для машинного обучения мы рассказывали здесь. Система на базе StreamSQL включает 3 компонента [4]:
- хранилище событий –неизменяемый реестр каждого события домена, отправляемого в систему;
- материализованное состояние с API, аналогичными Cassandra, Redis и CockroachDB;
- преобразования – чистые функции, которые преобразуют события в состояние. Каждое полученное событие обрабатывается и применяется к материализованному состоянию в соответствии с преобразованием.
StreamSQL выполняет новые преобразования задним числом для всех данных. Конечное состояние — это истинная материализация всего потока событий. Можно создать «виртуальное» состояние, откатываясь назад и воспроизводя события. Виртуальное состояние можно использовать для обучения и проверки моделей Machine Learning, а также для отладки или разработки внешнего интерфейса. Таким образом, система со StreamSQL должна выполнять следующие функции [4]:
- долговременно хранить каждое событие домена;
- поддерживать согласованность материализованного состояния, гарантируя однократную обработку каждого входящего события;
- выполнять преобразования всех исторических событий в порядке их получения;
- откатывать назад и воспроизводить журнал событий, материализуя представления в нужный момент времени.
Изначально такая Big Data система была основана на Apache Kafka и еще ряда технологий для работы с большими данными. Прошлые события сохранялись в AWS S3 и обрабатывались с помощью Spark. Для потоковой передачи данных использовались Kafka и Flink. Сохранение согласованности событий и материализованных представлений требовало сложной координации между каждой системой.
Переход с Apache Kafka на Pulsar позволил удалить из системы Spark, объединив возможности потоковой передачи и пакетной обработки с помощью коннектора Pulsar-Flink. Простота архитектуры исключает множество крайних случаев, обработку ошибок и затраты на обслуживание, которые присутствовали в версии на основе Kafka. Теперь достаточно всего одного задания обработки как для пакетных, так и потоковых данных – Apache Flink поддерживает единовременную обработку, автоматически переключаясь между режимами.
Рассмотренные примеры свидетельствуют не о превосходстве Apache Pulsar над Kafka или наоборот, а еще раз подчеркивают обоснованность выводов, которые мы сделали в статье про бенчмаркинговые сравнения этих Big Data фреймворков. Выбор инструмента зависит от особенностей каждого конкретной ситуации. В большинстве случаев Apache Kafka является идеальным вариантом для построения масштабных распределенных систем интеграции и потоковой аналитики больших данных, обеспечивая надежность и высочайшую производительность обработки событий в реальном времени. Однако, иногда дополнительно к модели Event Streaming требуется поддержка очередей сообщений в одном решении. Здесь на арену выходит молодой Apache Pulsar, смещая зрелую Kafka. Об этом мы поговорим завтра.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
2 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Как эффективно использовать оба этих фреймворка с учетом особенностей администрирования кластеров и разработки Kafka-приложений для аналитики больших данных, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://softprom.com/sites/default/files/materials/the-nutanix-design-guide-first-edition.pdf
- https://medium.com/@yuvarajl/why-nutanix-beam-went-ahead-with-apache-pulsar-instead-of-apache-kafka-1415f592dbbb
- https://streamnative.io/en/success-stories/yahoo_japan
- https://streamnative.io/en/blog/tech/2020-04-21-from-apache-kafka-to-apache-pulsar

