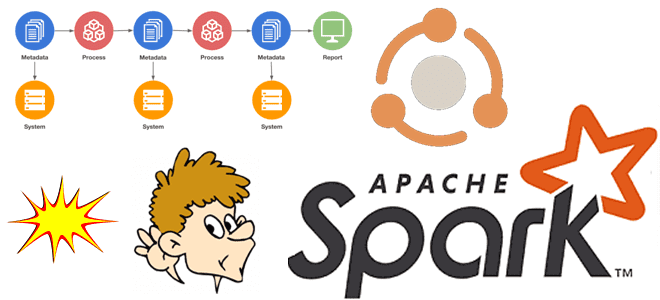
Вчера мы рассказывали, почему важна наблюдаемость данных какие платформы помогают комплексно обеспечить все ее аспекты. В продолжение этой темы сегодня заглянем под капот происхождения данных в Apache Spark с помощью агента Spline и других способов. Трудности data lineage в Apache Spark Когда конвейер данных выходит из строя, дата-инженеру нужно скорее...
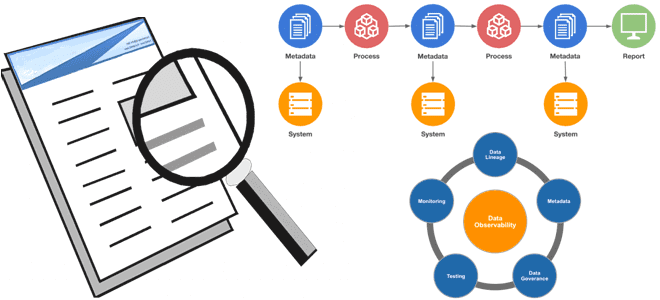
Сегодня рассмотрим, почему наблюдаемость данных так важная для проектов Big Data, какие компоненты обеспечивают ценную информацию о качестве и надежности данных, чем это похоже на DataOps, а также как эти идеи реализовать на практике с использованием популярных инструментов современной дата-инженерии. Почему важна наблюдаемость данных Цифровизация предполагает управление на основе качественных...

Сегодня рассмотрим 2 основные категории технологий обработки данных: пакетную и потоковую. Что общего между batch и stream processing, где они применяются, какими технологиями поддерживаются, можно ли их использовать вместе и как это сделать: ликбез по архитектуре больших данных. Потоковая и пакетная обработка: краткий обзор с примерами Обработки данных в режиме...

Что такое SparkListener, какие встроенные слушатели бывают в Apache Spark, как написать собственный перехватчик событий и зачем это нужно разработчику распределенного приложения. Также рассмотрим, как реализовать свой слушатель для приложения на PySpark и зачем включать уровень логирования INFO для SparkContext. Что такое слушатель Spark Apache Spark позволяет быстро обрабатывать большие...

В недавней статье про современные архитектуры данных мы упоминали Data Fabric и Data Mesh. Сегодня поговорим про эти стратегии Data Governance более подробно: разберем их главные достоинства и недостатки, основные сходства и принципиальные отличия, ключевые вызовы и технологии реализации, а также возможности совместного применения на практике. Что такое Data Fabric...

Сколько ядер ЦП выделить на каждый исполнитель и каково оптимальное количество памяти для Spark-приложения при статическом и динамическом выделении ресурсов. Важные вопросы эффективной утилизации кластера, с которыми сталкивается каждый дата-инженер и разработчик распределенных программ. Запуск распределенного приложения через spark-submit Повысить эффективность работы приложения Apache Spark можно не только через оптимизацию...

Что такое архитектура данных, какие модели чаще всего используются в современных Big Data системах, почему традиционные BI-системы не справляются со всем разнообразием текущих бизнес-сценариев, чем Лямбда отличается от Каппа, а Data Fabric от Data Mesh и зачем внедрять MLOps-инструменты в аналитическую платформу. Немного истории: почему архитектуры данных до сих пор...
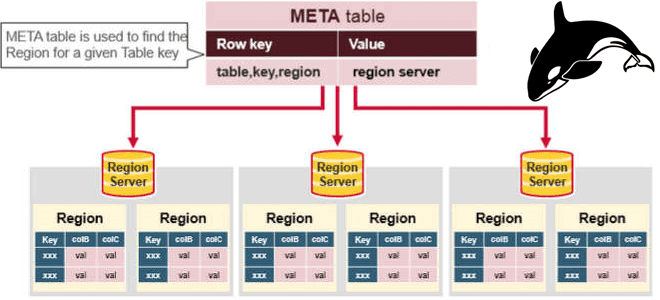
Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка. Регионы и сервера Apache HBase Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности...

Как изменять правила фильтрации данных без перезапуска потокового Flink-приложения: практический пример для разработчиков и дата-инженеров. Чем подход с ключами состояний отличается от широковещательных соединений, каковы достоинства и недостатки этих альтернатив. Фильтрация данных в статике и динамике Практически каждая платформа потоковой передачи событий позволяет использовать фильтрацию операторов для отбора данных согласно...

В этой статье для дата-инженеров и администраторов кластера рассмотрим, как считать данные из распределенной файловой системы Apache Hadoop в MPP-СУБД Greenplum. Архитектура и принцип работы PXF-коннектора к HDFS с примерами команд. Интеграция Greenplum и Hadoop через PXF-коннекторы Мы уже писали, что представляет собой интеграционный фреймворк PXF (Platform Extension Framework), который...