Сегодня затронем тему администрирования кластеров Apache HBase и рассмотрим, приносит ли реальную пользу совместное размещение нескольких региональных серверов (RegionServer) на одном узле кластера. Сравнительный анализ по тестам YCSB-бенчмарка.
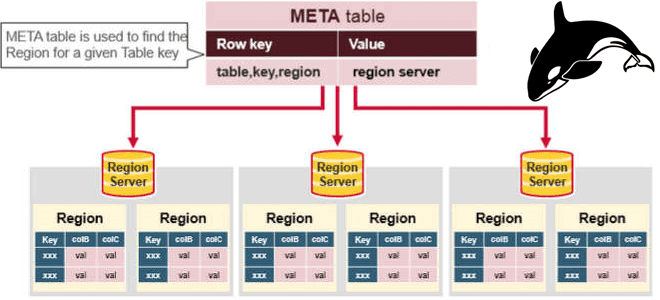
Регионы и сервера Apache HBase
Напомним, Apache HBase является популярной колоночной NoSQL-СУБД, которая работает поверх распределенной файловой системы HDFS и обеспечивает возможности BigTable для Hadoop, реализуя отказоустойчивый способ хранения больших объёмов разреженных данных. HBase обеспечивает случайный доступ в реальном времени к данным в Hadoop в сочетании с удобством пакетной обработки.
Будучи распределенной СУБД, HBase может работать на десятках и сотнях физических серверов, обеспечивая бесперебойную работу даже при сбое некоторых узлов. Распределение данных по разным физическим машинам кластера обеспечивает механизм регионирования, когда строки таблиц, соответствующие определенному диапазону идущих подряд первичных ключей, автоматически группируются по горизонтали в единый диапазон – регион. Один или несколько регионов обслуживаются региональным сервером (RegionServer). А за распределение регионов по региональным серверам отвечает главный узел в кластере, MasterServer.
Через системные службы (демоны) региональных серверов в Apache HBase выполняется любой запрос на CRUD-операцию для создания, чтения, обновления и удаления данных. В производственных средах на каждом вычислительном узле развертывается один сервер RegionServer, что позволяет масштабировать как рабочие нагрузки, так и совместное использование хранилища путем добавления дополнительных узлов.
Несмотря на ярко выраженную тенденцию движения в облачные инфраструктуры, до сих пор многие компании по-прежнему предпочитают обрабатывать свои данные локально, в собственных кластерах. Однако, развертывание серверов на «голом железе» использует все пространство памяти каждой машины. Поэтому те узлы кластера, рабочие нагрузки которых составляют операции HBase, не всегда используют все свои ресурсы, поскольку объем ОЗУ, который может потреблять RegionServer, ограничен JVM. Кстати, именно это является одним из недостатков HBase, которая написана на Java.
Если бы каждый RegionServer мог использовать всю доступную ему оперативную память, его производительность могла бы значительно возрасти. А удаление «лишних» узлов из кластера позволило бы сократить расходы и лучше использовать имеющиеся ресурсы. Поэтому возникает вопрос: можно ли в локальной инфраструктуре позволить каждому региональному серверу использовать больше ресурсов памяти, чтобы поддерживать рабочую нагрузку из-за удаления одного или нескольких рабочих процессов? Рассмотрим эту гипотезу, протестировав несколько экземпляров RegionServer на производительность с помощью набора тестов YCSB. Что это такое и при чем здесь Apache HBase, читайте далее. А о том, как некорректные настройки HDFS могут провоцировать отказы региональных серверов, мы рассказываем в новой статье.
YCSB-бенчмаркинг
YCSB (Yahoo! Cloud Serving Benchmark) – это набор программ с открытым исходным кодом, используемых для оценки возможностей восстановления и обслуживания ПО. Он часто используется для сравнения относительной производительности NoSQL-СУБД. Оригинальный тест был разработан исследователями Yahoo! и выпущен в 2010 году с целью облегчить сравнение производительности облачных систем обслуживания данных нового поколения. При этом была заявлена ориентация на рабочие нагрузки обработки транзакций, которые отличались от нагрузок, измеренных эталонными тестами для более традиционных СУБД. YCSB часто сравнивают с другим эталонным тестом TPC-H от Совета по производительности обработки транзакций. При этом YCSB назывался эталонным тестом для больших данных, а TPC-H — эталонным тестом системы поддержки принятия решений.
На практике YCSB часто используется многими вендорами разных СУБД для эталонного сравнения производительности их продуктов с аналогами, включая Apache HBase, Cassandra, MongoDB, Aerospike, Couchbase, Riak, Elasticsearch, Oracle NoSQL, OrientDB, Redis, Scalaris, Tarantool и Voldemort.
Для проверки нашей гипотезы о пользе размещения нескольких региональных серверов на одном узле кластера HBase, набор тестов YCSB-бенчмарка повторяет следующие шаги в каждой итерации:
- создание таблицы из 50 регионов;
- прошивки с новыми записями около 150 ГБ;
- рабочая нагрузка A, «интенсивное обновление», которая состоит из равного количества операций чтения и записи. Обновления выполняются без предварительного чтения элемента подобно cookie-файлам пользовательского сеанса на веб-сайте.
- рабочая нагрузка F, «чтение-изменение-запись», когда каждый элемент будет прочитан, изменен и затем перезаписан, как в базе данных, где записи читаются и изменяются пользователем.
Для каждой рабочей нагрузки будут восстановлены время выполнения (в секундах) и частота операций (в операциях в секунду). Тесты проводились на кластере HDP 2.6.5, на 4-х узлах «bare-metal» с 180 ГБ ОЗУ и 4 дисками по 3 ТБ каждый. Пропускная способность сети передачи данных внутри кластера составляла 10 ГБ/с. Все региональные серверы этих 4-х worker’ов использовались исключительно для тестового набора и не несли никакой другой рабочей нагрузки. В каждой ситуации тестовый набор запускался не менее трех раз.
Сперва тестировалось удаление узла из кластера и последующее добавление региональных серверов на разные хосты для измерения производительности. Результаты средних значений показаны в таблице.
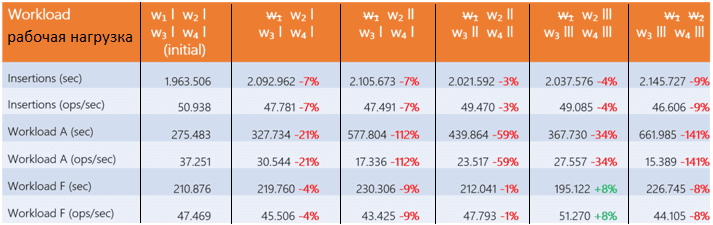
Эксперимент показал, что добавление одного или нескольких RegionServer на каждый хост не компенсирует потерю узла. Более того, дисбаланс региональных серверов между хостами приводит к резкому падению производительности, т.к. мастер рассматривает каждый RegionServer независимо, как если он установлен на отдельной машине. Так регионы равномерно распределяются по каждому региональному серверу. Хост с большим количеством региональных серверов должен обрабатывать больше регионов, и рабочая нагрузка распределяется между узлами кластера неравномерно. Таким образом, RegionServer не компенсирует потерю машины.
Далее конфигурация узлов данных и региональных серверов серверы была оптимизирована. Узлам данных выделили максимальное количество потоков и оперативной памяти через задание параметров dfs.datanode.max.transfer.threads и dtnode_heapsize соответственно.
На региональных серверах оптимизировано количество обработчиков (hbase.regionserver.handler.count) и выделенной оперативной памяти (hbase_regionserver_heapsize).
В следующей таблице показана исходная и улучшенная производительность (после оптимизации параметров конфигурации) с 2-мя региональными серверами на один узел.
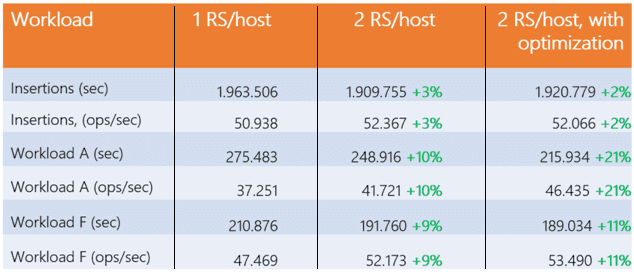
Выигрыш от добавления RegionServer на каждый рабочий процесс составил 10%, что незначительно и объясняет результаты первого исследования, усиленные рассмотрением реалистичной погрешности в 3%. Прибыль от 3 или более региональных серверов на один хост идентична предыдущему случаю, поэтому особой выгоды не наблюдается.
Добавив региональным серверам 10 ГБ оперативной памяти (hbase_regionserver_heapsize=30,720) и 4000 потоков для передачи данных DataNode (dfs.datanode.max.transfer.threads=20,480), получили 11% прироста для рабочей нагрузки A и 21% для F. Результаты эксперимента с 3-мя региональными серверами после оптимизации остались без изменений.
Увеличение количества потоков на узлах данных увеличивает количество запросов на чтение/запись к дискам, создавая задачи, ожидающие доступных операций ввода-вывода. Поэтому количество потоков по умолчанию было недостаточным при добавлении RegionServer для достижения порога производительности узлов данных.
С добавлением оперативной памяти региональным серверам можно предположить, что чтение выполняется в BlockCache, уменьшая количество запросов на чтение, поступающих на диск, и снижая количество задач, ожидающих диска. Это может объяснить преимущества рабочих нагрузок чтения, незначительные для рабочих нагрузок записи, с оптимизацией или без нее. Таким образом, имеет смысл протестировать влияние диска на производительность, что мы рассмотрим далее.
Выводы по тестированию
Изначально тестируемые машины работали с 4-мя дисками по 3 ТБ, и к каждой добавлено 8 дисков. Результаты испытаний представлены в следующей таблице:
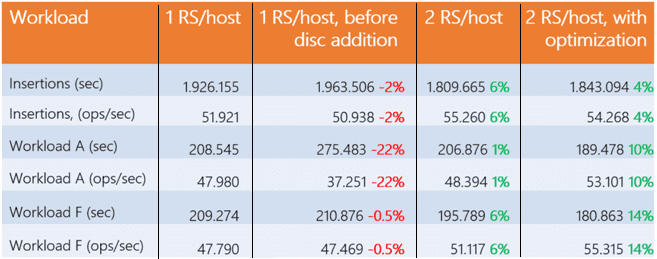
Эксперименты показали разницу в производительности 22% на рабочей нагрузке A по сравнению с исходным случаем, в то время как для двух других типов тестов они примерно одинаковы. С другой стороны, при той же рабочей нагрузке выигрыш увеличивается до 1% при использовании 2-х региональных серверов на хост, а затем до 10% при оптимизации конфигурации каждой машины. Таким образом, увеличение количества дисков существенно повлияло на производительность RegionServer, в отличие от добавления дополнительного экземпляра.
По результатам тестирования Apache HBase на YCSB-бенчмарке, можно сделать выводы, что производительность записи и чтения не удвоится за счет добавления второго RegionServer на каждый рабочий процесс. Узел данных выступает в качестве узкого места и, в лучшем случае, дает 21% прироста. Региональные серверы оптимизированы для самостоятельного использования максимальной производительности и работают в комплексе с диспетчерами узлов YARN и узлами данных HDFS. Впрочем, не удивительно, т.к. Apache HBase была изначально разработана так, чтобы иметь только один RegionServer на Worker, о чем свидетельствует прирост производительности с одним RegionServer при добавлении дисков.
С другой стороны, это может быть полезно в случае кластера с профицитом регионов, которые поровну распределяются между каждым региональным сервером без потери производительности. Кроме того, для определенных вариантов использования, таких как рабочая нагрузка F, можно рассмотреть возможность удаления физического узла, чтобы сократить расходы на лицензирование и его эксплуатацию без значительного снижения производительности.
Узнайте больше подробностей по администрированию и использованию Apache HBase для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
Источники

