Сколько ядер ЦП выделить на каждый исполнитель и каково оптимальное количество памяти для Spark-приложения при статическом и динамическом выделении ресурсов. Важные вопросы эффективной утилизации кластера, с которыми сталкивается каждый дата-инженер и разработчик распределенных программ.
Запуск распределенного приложения через spark-submit
Повысить эффективность работы приложения Apache Spark можно не только через оптимизацию кода и выравнивание распределения данных. Повысить производительность приложения поможет также корректная конфигурация при его запуске, чтобы использовать ресурсы кластера наиболее выгодным способом.
Напомним, Spark-приложения можно запускать как в локальном режиме (на клиенте, по умолчанию), так и в кластере. Варианты и параметры запуска указываются в специальном скрипте для распределения заданий независимо от типа диспетчера кластера, который называется spark-submit. В общем случае синтаксис этого скрипта выглядит следующим образом:
spark-submit –class <CLASS_NAME> –num-executors ? –executor-cores ? –executor-memory ?
Рассмотрим назначение указываемых параметров:
- –class – главный класс приложения в ООП-языках JAVA или Scala;
- –num-executors – число узлов-исполнителей распределенной программы;
- –executor-cores – число процессоров для исполнителя;
- — executor-memory – объем памяти в байтах для исполнителей;
- –driver-memory – объем памяти, выделяемой для driver-программы.
Перед тем, как явно указать значения вышеперечисленных параметров, стоит учитывать архитектуру и специфику работы Spark-приложений:
- при запуске приложения с помощью диспетчера кластеров, например, YARN, в фоновом режиме будут работать несколько системных служб (NameNode, Secondary NameNode, DataNode, JobTracker и TaskTracker). Поэтому при указании числа исполнителей –num-executors нужно убедиться, что для бесперебойной работы системных служб оставлено достаточно ядер ЦП, т.е. около 1 ядра на узел.
- Мастер приложения YARN (ApplicationMaster, AM) отвечает за согласование ресурсов с менеджером ресурсов (ResourceManager) и работу с менеджерами узлов (NodeManager) для выполнения и мониторинга контейнеров и потребления ими вычислительных ресурсов. При запуске Spark-приложения под управлением YARN нужно выделить ресурсы, которые потребуются AM, т.е. примерно 1024 МБ памяти и 1 исполнитель.
- у клиентов распределенной файловой системы Apache Hadoop (HDFS) часто случаются проблемы с множеством одновременных потоков. Обычно HDFS достигает полной пропускной способности записи примерно при 5 задачах на исполнителя. Поэтому рекомендуется задавать количество ядер на исполнителя менее 5.
- Помнить про различные разделы памяти Spark-приложения, которая делит пространство пространство кучи (Heap) JVM в драйвере и исполнителях на 4 разные части, о чем мы подробно рассказывали здесь. Хотя большинство операций в Spark происходит внутри JVM и использует ее кучу для своей памяти, каждый исполнитель может также иногда обращаться к внешнему пространству за пределами виртуальной машины Java через API-интерфейсы sun.Unsafe. Эта память вне кучи находится за пределами области сборки мусора и дает разработчику приложения более точный контроль над памятью. Подробнее о распределении памяти Spark-приложения поговорим далее.
Использование памяти в Spark-приложениях
Оперативная памяти в Spark нужна для выполнения вычислений и хранения промежуточных результатов. Память выполнения используется при перемешивании, соединении, сортировке и агрегации, а память хранения – при кэшировании и распространения внутренних данных по кластеру. Поскольку основным языком реализации самого Apache Spark является Scala, все операции выполняются внутри JVM, даже если пользовательский код написан на Python или R.
В Spark исполнение и хранилище совместно используют единый регион (M). Когда память выполнения не используется, хранилище может получить всю доступную память и наоборот. Выполнение может вытеснить хранилище, если это необходимо, но только до тех пор, пока общее использование памяти хранилища не упадет ниже определенного порога (R) – области внутри M, где кэшированные блоки никогда не удаляются. Хранилище может не исключать выполнение из-за сложностей в реализации.
Такая конструкция обеспечивает следующие преимущества:
- приложения, не использующие кэширование, могут использовать для выполнения все пространство, избегая ненужного сброса данных на диск;
- приложения, использующие кэширование, могут зарезервировать минимальное пространство хранения (R), где их блоки данных не будут вытеснены;
- приемлемая производительность для различных рабочих нагрузок без необходимости погружения в тонкости внутреннего разделения памяти.
При необходимости ручной настройки разделов памяти Spark-приложения это можно сделать через следующие конфигурации:
- spark.memory.fraction – область памяти M для выполнения и хранения данных в JVM-куче. По умолчанию размер M равен 60% от исходного размера JVM-кучи, равного 300 МБ. Чем меньше это значение, тем чаще происходит утечка и вытеснение кэшированных данных. Эта конфигурация позволяет выделить память для внутренних метаданных и структур пользовательских данных, а также приблизительно оценить размер разреженных необычно больших записей. Остальное пространство (40%) зарезервировано для пользовательских структур данных, внутренних метаданных в Spark и защиты от ошибок OOM в случае разреженных и очень больших записей.
- spark.memory.storageFraction – размер R – пространства хранения в M, где кэшированные блоки защищены от вытеснения при выполнении. По умолчанию 50% от размера M.
По сути, оба параметра устанавливают объем пространства JVM, который будет использоваться в качестве памяти для хранения и кэширования данных. Но spark.memory.fraction определяет общий объем памяти, выделенной как для перемешивания, так и для хранения данных, а потому должно быть установлено так, чтобы это количество пространства кучи соответствовало поколению JVM. Объем памяти, защищенной от вытеснения, определяется параметром spark.memory.storageFraction.
Общая память вне кучи для исполнителя Spark контролируется конфигурацией spark.executor.memoryOverhead, по умолчанию равной 10% памяти исполнителя при минимальном размере 384 МБ. Даже если пользователь явно не задает этот параметр, фреймворк сам выделит 10% памяти исполнителя или 384 МБ, в зависимости от того, что больше для накладных расходов JVM. Этот объем дополнительной памяти, выделяемой для каждого процесса-исполнителя, увеличивается по мере роста размера исполнителя. Об этом мы упоминали здесь и здесь.
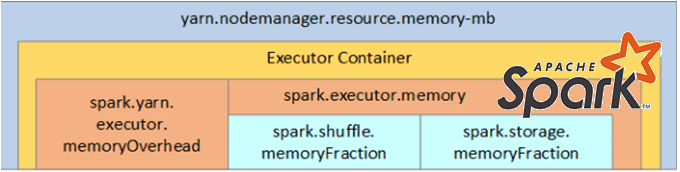
Таким образом, полную память, необходимую для Spark-исполнителя, которую выделяет YARN, можно рассчитать по следующей формуле:
spark-executor-memory + spark-yarn-executor-memoryOverheadspark-yarn-executor-memoryOverhead = Max(384MB, 7% of spark.executor-memory)
Например, запросив 20 ГБ на исполнителя, менеджер приложений YARN на самом деле получит на 7% больше, т.е. примерно 23 ГБ памяти. При этом стоит помнить, что запуск исполнителей со слишком большим объемом памяти часто приводит к чрезмерным задержкам сборки мусора. И напротив, запуск исполнителей с малым количеством ресурсов, например, с одним ядром и минимальным объемом памяти для выполнения одной задачи сводит на нет преимущества выполнения нескольких задач в одной JVM.
Есть 2 способа настройки исполнителя и основных параметров задания Apache Spark в зависимости от характера размещения ресурсов:
- статическое (Static Allocation) — значения конфигурационных параметров задаются как часть spark-submit;
- динамическое (Dynamic Allocation) — значения назначаются в зависимости от требований (размер данных, объем необходимых вычислений) и освобождаются после использования, чтобы повторно использовать ресурсы для других приложений.
Как распределить ресурсы в этих настройках, рассмотрим далее.
Статическое и динамическое размещение ресурсов
Рассмотрим кластер из 10 узлов, каждый из которых содержит 16 ядер ЦП и 64 ГБ ОЗУ. Проанализируем различные варианты распределения вычислительных ресурсов на исполнителя. Сперва выделим по 1-му ядру на 1-го исполнителя. Тогда значения параметров spark-config будут следующими:
--num-executors = In this approach, we'll assign one executor per core = total-cores-in-cluster = num-cores-per-node * total-nodes-in-cluster = 16 x 10 = 160--executor-cores = 1 (one executor per core)--executor-memory = amount of memory per executor = mem-per-node/num-executors-per-node = 64GB/16 = 4GB
Таким образом, в случае одноядерных исполнителей нельзя воспользоваться преимуществами запуска нескольких задач в одной и той же JVM. Кроме того, общие/кэшированные переменные, такие как широковещательные переменные и аккумуляторы, будут реплицироваться в каждом ядре узлов, т.е. 16 раз. Кроме того, не остается достаточно памяти для процессов системных сервисов Hadoop/YARN и ApplicationManager. Поэтому такой подход нельзя назвать оптимальным.
Рассмотрим альтернативу с одним исполнителем на узел, т.е. на каждого исполнителя будет приходится все 16 ядер ЦП. Значения параметров spark-config при таком подходе будут следующими:
--num-executors = In this approach, we'll assign one executor per node = total-nodes-in-cluster = 10--executor-cores = one executor per node means all the cores of the node are assigned to one exec = total-cores-in-a-node = 16--executor-memory = amount of memory per executor = mem-per-node/num-executors-per-node = 64GB/1 = 64GB
В случае 16 ядерных исполнителей пропускная способность HDFS ухудшится, и это приведет к чрезмерному количеству мусора. Поэтому нужен разумный баланс между двумя крайностями.
- Согласно вышерассмотренным рекомендациям, назначим по 5 ядер на исполнителя для хорошей пропускной способности HDFS , т.е. –executor-cores = 5.
- Оставим 1 ядро на узел для системных служб Hadoop/YARN, т.е. количество доступных ядер на узел снизится до 15 = 16–1
- Общее количество доступных ядер в кластере станет 15 x 10 = 150
- Общее количество доступных исполнителей равно отношению числа ядер к числу ядер на исполнителя, т.е. 30=150/5
- Оставим 1 исполнителя для ApplicationManager, т.е. –num-executors = 29
- Определим количество исполнителей на узел, разделив их общее количество на число узлов. Получим 3=30/10
- Память на одного исполнителя равно отношению общего количества памяти на узле на число исполнителей на нем. Получается 21=64/3 ГБ.
- Накладные расходы на JVM-кучу составят 7% от 21 ГБ, т.е. 3 ГБ. Поэтому фактический размер памяти исполнителя –executor-memory будет 18=21 – 3 ГБ
Таким образом, рекомендуемая конфигурация в случае статического размещения ресурсов будет следующая: 29 исполнителей, по 18 Гб памяти и по 5 ядер.
При включенном динамическом размещении ресурсов верхний предел количества исполнителей не ограничен, т.е. Spark-приложение может потреблять все доступные ресурсы, если это необходимо. Поэтому включать конфигурацию spark.dynamicAllocation.enabled в значение true следует с осторожностью в кластере, где помимо Spark также работают другие приложения, которым тоже нужны ядра ЦП для выполнения задач. В этом случае нужно назначать ядра ЦП на уровне кластера, выделив их нужное количество для приложений на основе YARN в зависимости от доступа пользователя. В частности, можно создать специального пользователя Spark (spark_user), а затем указать минимальное и максимальное количество ядер для него. Эти ограничения предназначены для обмена данными между spark и другими приложениями, работающими на YARN.
Когда конфигурация spark.dynamicAllocation.enabled установлена в значение true, не нужно явно назначать ресурсы исполнителям, т.к. в скрипте запуска spark-submit номера статических параметров относятся ко всей продолжительности задания. Можно задать начальное количество исполнителей через конфигурацию spark.dynamicAllocation.initialExecutors, которое будет меняться в зависимости от нагрузки, т.е. задач, ожидающих выполнения задач. В конечном итоге это приблизится к числу, которое явно указывается при вызове spark-submit статическим способом. В динамическом же размещении после установки начального количества исполнителей, можно лишь указать их минимальное (spark.dynamicAllocation.minExecutors) и максимальное (spark.dynamicAllocation.maxExecutors) число. Запросить новых исполнителей или отдать действующих исполнителей поможет параметр spark.dynamicAllocation.executorIdleTimeout, по умолчанию равный 60 секунд.
Фактический запрос инициируется, когда есть ожидающие задачи в течение секунд spark.dynamicAllocation.schedulerBacklogTimeout, а затем снова запускается через период, указанный в spark.dynamicAllocation.sustainedSchedulerBacklogTimeout, если очередь ожидающих задач сохраняется. Количество исполнителей, запрашиваемых в каждом раунде, экспоненциально увеличивается по сравнению с предыдущим раундом. Например, приложение добавит 1 исполнителя в первом раунде, а затем 2, 4, 8 и так далее исполнителей в последующих раундах. Это гарантирует, что приложение не будет запрашивать слишком много исполнителей в начале и перекликается с оправданием медленного старта TCP. Также Spark-приложение имеет возможность своевременно увеличить использование своих ресурсов, если нужно много исполнителей.
Приложение Spark удаляет исполнителя, если он простаивает большее количество секунд, чем указано в конфигурации spark.dynamicAllocation.executorIdleTimeout. Это условие является взаимоисключающим с условием запроса, т.е. исполнитель не должен бездействовать при наличии запланированных задач.
Таким образом, если разработчику нужен больший контроль над временем выполнения задания и мониторинг его на наличие неожиданного объема данных, целесообразно задавать используемые исполнителями ресурсы вручную через статическое размещение и явное указание в spark-submit. При переходе на динамический режим ресурсы будут использоваться в фоновом режиме, а задания, связанные с очень большими объемами данных, могут неожиданно и негативно повлиять на другие приложения.
Узнайте больше практических деталей по применению Apache Spark для задач дата-инженерии, разработки распределенных приложений и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://joydipnath.medium.com/how-to-determine-executor-core-memory-and-size-for-a-spark-app-19310c60c0f7
- https://spoddutur.github.io/spark-notes/distribution_of_executors_cores_and_memory_for_spark_application
- https://spark.apache.org/docs/latest/tuning.html
- https://spark.apache.org/docs/latest/job-scheduling.html