 1074
1074 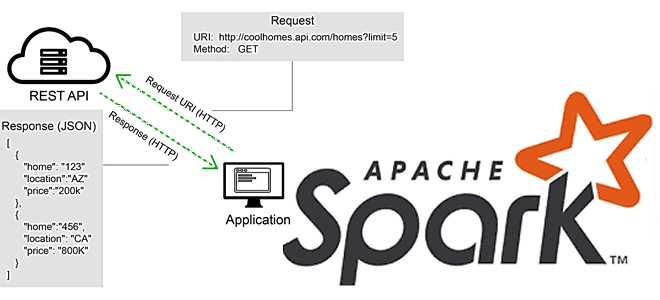
Содержание
В этой статье для разработчиков Apache Spark разберем, что не так с вызовами REST API в этом фреймворке, и как решить эту проблему с помощью готовых библиотек или создания собственных UDF-функций на PySpark и не только. Для наглядности рассмотрим практический пример вызова REST API на PySpark с библиотекой Rest Data Source.
Куда пропало распараллеливание при вызовах REST API в Apache Spark и как его найти
Несмотря на то, что Apache Spark реализует модель распределенных вычислений в кластере, далеко не все операции в нем выполняются параллельно. Разработчику Spark-приложений необходимо знать о таких случаях. Одним из них является выполнение кода на драйвере, а не на всех узлах кластера. Например, при подключении к REST API данные получает только один драйвер Spark, что эквивалентно запуску программы на одном узле. При большом объеме данных выполнения вызовов REST API происходит в цикле, где каждая итерация будет последовательной. Поэтому перед разработчиком встает вопрос, как распараллелить эту концепцию, используя возможности фреймворка распределенных вычислений.
В общем случае решить эту проблему можно, используя REST API, который будет вызываться несколько раз, чтобы получить нужные данные. Чтобы воспользоваться преимуществами параллелизма Apache Spark, каждый вызов REST API следует инкапсулировать в определенную пользователем функцию (UDF, User Defined Function), привязанную к нужным данным в структуре DataFrame. Каждая строка в DataFrame будет представлять один вызов службы REST API. После выполнения действия в DataFrame результат каждого отдельного вызова REST API будет добавлен к каждой строке как структурированный тип данных.
Например, для этого можно написать собственную UDF на PySpark, который будет подключаться к REST API и загружать данные. Эта UDF будет вызываться в датафрейме с функцией Column. Поскольку REST API работает по HTTP(S)-протоколу, входными данными в эту UDF будут URL-адрес и выполняемое действие. Эти данные будут переданы как столбцы в UDF. В результате подключение к API и загрузка данных будут выполняться исполнителями, а не драйвером, и каждая строка будет устанавливать индивидуальное подключение к API. Примеры описания собственной UDF на PySpark и Scala приведены в источниках [1, 2, 3]. Есть и другой путь – воспользоваться решением сообщества, упакованными в готовую библиотеку, что мы и рассмотрим далее.
Core Spark - основы для разработчиков
Код курса
CORS
Ближайшая дата курса
6 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Библиотека REST как источник данных для Apache Spark: практический пример
Rest Data Source – это библиотека с открытым исходным кодом для параллельного вызова сервисов/API на основе REST для нескольких наборов входных параметров и сопоставления результатов, возвращаемых сервисом REST в Dataframe. Службы на основе REST типа Google Search API, Watson NLP API и пр. обычно принимают только один набор входных параметров за раз и возвращают соответствующие записи. Однако, в реальных задачах Data Science один и тот же API часто требуется вызывать несколько раз, чтобы учесть большой набор различных входных параметров, например, проверка адресов для набора целевых клиентов, получение информации из нескольких тысяч твитов, сбор сведений из реестра с множеством записей и т. д.
В Apache Spark Автоматизировать вызов API целевого сервиса распределенным способом для различных наборов входных параметров поможет библиотека Rest Data Source. Результаты возвращаются в DataFrame в структуре, специфичной для API, без указания пользователем этой схемы. Пакет с API для нескольких языков программирования, поддерживаемых Spark (R, Python, Scala), позволяет выполнять несколько параллельных вызовов целевого микросервиса для набора различных входных параметров, которые можно передать как временную таблицу Spark.
В этой временной таблице имена столбцов таблицы должны совпадать с ключами целевого API. Каждая строка в таблице и соответствующая комбинация значений параметров будут использоваться для выполнения одного вызова API. Результат нескольких вызовов API возвращается как Spark DataFrame из строк с выходной структурой, соответствующей ответу целевого API. Все типы данных преобразуются в строку при генерации полезной нагрузки. Объекты и другие сложные типы данных также поддерживаются в качестве полезной нагрузки. При этом объекты должны быть преобразованы в строки JSON. В Spark SQL для этого можно использовать функцию to_json().
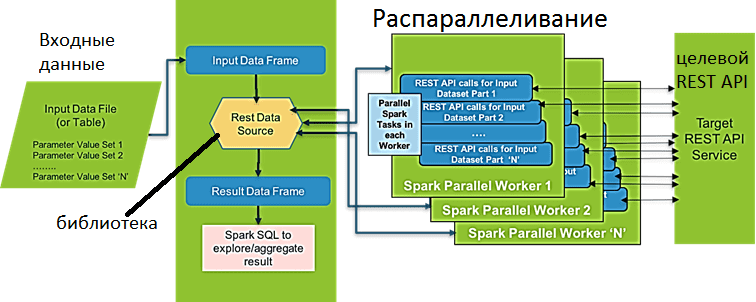
Библиотека Rest Data Source поддерживает следующие опции вызова целевого сервиса REST [4]:
- url — целевой URI микросервиса, обязательный параметр;
- input – имя временной таблицы Spark с набором входных параметров. Если эта таблица содержит сложные типы данных, которые необходимо отправить в качестве полезной нагрузки, следует сперва преобразовать объект в строку JSON.
- method — метод протокола HTTP(S), по умолчанию POST. Также поддерживается GET.
- userId – идентификатор пользователя, если целевому API нужна базовая аутентификация;
- userPassword – пароль пользователя на случай, если целевому API требуется базовая аутентификация;
- oauthToken — значение ключа авторизации, переданное в ЗАГОЛОВОК для авторизации на основе токена-носителя;
- partitions – номер раздела для увеличения параллелизма в Spark, по умолчанию равен 2;
- connectionTimeout – время подключения к целевому API, по умолчанию равно 1000 миллисекунд;
- readTimeout— время чтения большого набора данных, возвращаемого целевым API, по умолчанию равно 5000 миллисекунд;
- schemaSamplePcnt – процент записей во входной таблице, которые будут использоваться для вывода схемы данных, по умолчанию равен 30, а минимальное значение равно 3. Рекомендуется увеличить это число в случае сообщения об ошибке или неверном определении схемы данных.
- callStrictlyOnce – гарантия строго однократного вызова серверного API для каждого набора входных параметров. По умолчанию этот параметр установлен в значение «N», что позволяет вызывать API серверной части несколько раз: один раз для вывода схемы данных, а затем для других операций. Если установить значение «Y», серверный API будет вызываться только один раз во время определения схемы для всех наборов входных параметров и будет кэширован. Эта опция полезна, когда вызов целевого API является платным или ограничен числом запросов в час/в день. Из-за кэширования результатов потребление памяти увеличится.
Чтобы понять, как это работает, рассмотрим практический пример вызова REST API на PySpark с библиотекой Rest Data Source. Предположим, требуется прочитать значения входных параметров из CSV-файла с именем sodainput.csv. Этот файл содержит два столбца: регион (region) и источник (source), которые соответствуют двум фильтрам, поддерживаемым SODA API для источника данных Socrata, а потому не требуют переименования. Вызовем API 3 раза, по одному для каждой из различных комбинаций значений «регион» и «источник».
Сперва создадим целевую строку url Soda API для источника данных Socrata
sodauri = ‘https://soda.demo.socrata.com/resource/6yvf-kk3n.json’
Далее прочитаем данные из CSV-файла в датафрейм Spark:
sodainputDf = spark.read.option(‘header’, ‘true’).csv(‘/home/biadmin/spark-enablement/datasets/sodainput.csv’)
Создадим временную таблицу Spark из sodainputDf:
sodainputDf.createOrReplaceTempView (‘sodainputtbl’)
Создадим карту параметров для передачи в библиотеку REST Data Source:
prmsSoda = {‘url’: sodauri, ‘input’: ‘sodainputtbl’, ‘method’: ‘GET’, ‘readTimeout’: ‘10000’, ‘connectionTimeout’: ‘2000’, ‘partitions’: ’10’}
Сохраним результаты вызова Soda API для трех разных точек входных данных в датафрейм:
sodasDf = spark.read.format («org.apache.dsext.spark.datasource.rest.RestDataSource»). options (** prmsSoda) .load()
Датафрейм, созданный рассмотренной библиотекой, вернет набор строк с той же структурой, которая будет содержать поля ввода для вызова API и вывод в новом столбце. Непосредственно результат вывода зависит от целевого REST API и его структуру можно получить с помощью метода printSchema() в API DataFrame Apache Spark. Чтобы проверить структуру возвращаемых результатов, посмотрим схему данных: sodasDf.printSchema().
Наконец, можно применить аналитический SQL-запрос или любую другую обработку полученных результатов:
sodasDf.createOrReplaceTempView(«sodastbl»)spark.sql(«select source, region, inline(output) from sodastbl»).show()
Исходный код пакета REST Data Source для Apache Spark, рекомендации по установке и примеры практического использования приведены в источниках [4, 5].
Освойте всю практику использования Apache Spark для разработки распределенных приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники
- https://medium.com/geekculture/how-to-execute-a-rest-api-call-on-apache-spark-the-right-way-in-python-4367f2740e78
- https://medium.com/@smdbilal.vt5815/making-parallel-rest-api-calls-using-pyspark-c951666c59d5
- https://github.com/jamesshocking/Spark-REST-API-UDF-Scala
- https://github.com/sourav-mazumder/Data-Science-Extensions/tree/master/spark-datasource-rest
- https://medium.com/@sourav.mazumder00/using-spark-as-a-parallel-processing-framework-for-accessing-rest-based-data-services-cd4c98526784

