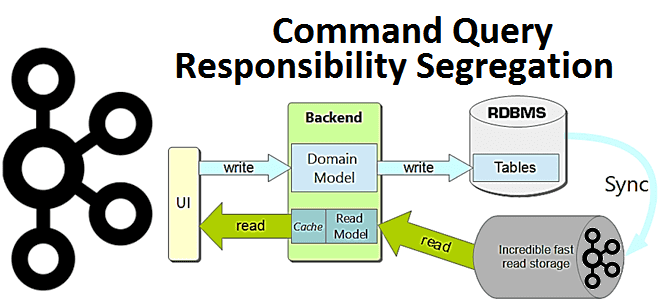
В этой статье для разработчиков распределенных приложений и ИТ-архитекторов разберем достоинства и недостатки паттерна проектирования CQRS, а также рассмотрим пример его реализации на Apache Kafka, Spring Cloud Stream и MongoDB. Что такое CQRS: основы проектирования архитектуры приложений Спрос на приложения, управляемые событиями, постоянно растет как для решения новых бизнес-задач, так...

Продвигая наш новый курс по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим применение теории графов к задаче анализа социальных связей на практическом примере возможностей библиотеки Graph Data Science СУБД Neo4j и ее языка запросов Cypher. А также разберем сопутствующую теорию: что такое центральность графа, почему эта мера не подходит для сетей...

Добавляя в наши курсы для дата-инженеров интересные кейсы, сегодня рассмотрим, как реализовать Лямбда-архитектуру для комплексной аналитики больших данных с помощью Apache Flink, Kafka и Cassandra на примере системы интернета вещей. Объединение пакетной и потоковой обработки данных средствами Flink API и библиотек этого фреймворка. Постановка задачи на примере IoT-системы Несмотря на...

В Apache HBase индексация таблиц возможна только по одному полю. Обойти это ограничение позволяет Apache Phoenix - инструмент обращения к NoSQL-хранилищу средствами SQL-запросов. В этой статье для дата-инженеров, архитекторов ИТ-решений и аналитиков данных рассмотрим типы вторичной индексации таблиц HBase в Phoenix и проблемы согласованности вторичных индексов, с которыми столкнулись специалисты...

Недавно мы писали про сложности обработки вложенных структур данных в JSON-файлах при работе с Apache Hive и Spark. В продолжении этой темы про парсинг, сегодня поговорим, как быстро преобразовать данные формата JSON в простой читаемый файл CSV или плоскую таблицу, чтобы анализировать их с помощью типовых методов DataFrame API или...

Мы уже рассказывали про связь Greenplum с другими источниками и приемниками данных с помощью PXF-фреймворка, а также отдельных коннекторов к некоторым системам. Сегодня рассмотрим, какие вообще есть коннекторы данных в этой MPP-СУБД и что такое Tanzu Greenplum Text. Коннекторы и фреймворки для интеграции GP и Arenadata DB с внешними системами...

В этой статье для дата-инженеров и администраторов кластеров разберем, как автоматически масштабировать поды Kubernetes с Apache AirFlow в зависимости от метрик рабочей нагрузки из внешней платформы Datadog с помощью демона StatsD, а также ресурса и контроллера HorizontalPodAutoscaler. Автоматическое горизонтальное масштабирование в Kubernetes Одна из сильных сторон Kubernetes заключается в его...

Недавно мы писали про развертывание Apache Kafka на Kubernetes с помощью open-source проекта Strimzi. Сегодня рассмотрим, как обеспечить безопасный доступ к данным на таком кластере, применив различные методы аутентификации и авторизации. Лучшие практики cybersecurity на практическом примере. Постановка задачи: пример приложения с безопасным доступом к данным Напомним, Strimzi – это...

Сегодня поговорим про совместное использование Apache NiFi с его легковесным агентом – MiNiFi. Преимущества для ETL-процессов в IoT-системах и не только, ограничения практического применения, а также пример контейнеризации и выполнения Docker-образа на Raspberry PI4 ARM64. Internet of Things и Apache NiFi на периферии Интернет вещей (Internet of Things, IoT) приводит...

В этой статье для дата-инженеров и администраторов SQL-on-Hadoop, рассмотрим, что такое Trino и как это работает с Apache Hive. А также при чем здесь Presto и зачем коннектор со своей средой выполнения использует Hive Metastore. Что такое Trino и при чем здесь Presto SQL Trino – это механизм запросов для...