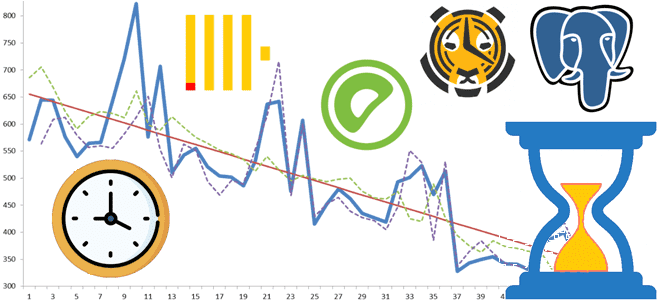
Анализ временных рядов нужен не только в Data Science, но и в мониторинге системных событий. Чем столбец с отметками времени в ClickHouse отличается от гипертаблиц в PostgreSQL и Greenplum c расширением TimescaleDB, и что выбирать для аналитики больших данных. ClickHouse для анализа временных рядов ClickHouse является колоночной СУБД для аналитической...

Что лучше: один или несколько кластеров Apache Kafka, когда и зачем разворачивать новый кластер вместо масштабирования существующего, какие задачи администрирования поручить локальным DevOps-инженерам, а что решать централизовано. Один или несколько кластеров Apache Kafka? Продолжая разговор про эффективное управление корпоративным кластером Apache Kafka, сегодня рассмотрим, когда и зачем нужно разворачивать новый...
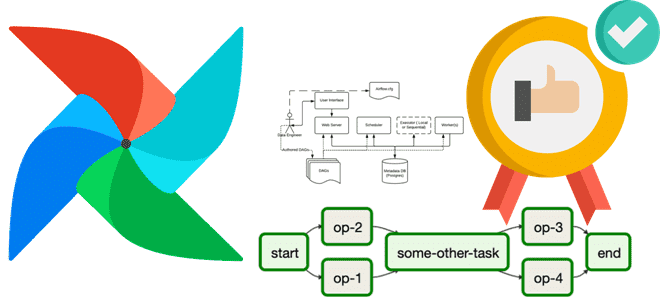
Сегодня разберем, как повысить эффективность использования объектов XCom в Apache AirFlow и сделать свои конвейеры обработки данных еще более гибкими с помощью настройки триггерных правил. Возможности TaskFlow API для XCom Объекты XCom позволяют задачам DAG в Apache AirFlow обмениваться данными. Это очень удобно для реализации конвейера с атомарными задачами, которые...

Зачем размещать задания Apache Spark на узлах HDFS, какую пропускную способность сети передачи данных выбрать, почему не рекомендуется использовать RAID для жестких дисков, сколько выделить памяти и ядер ЦП. Рекомендации по настройке оборудования для Spark-приложений На практике большинство заданий Spark считывает входные данные из внешней системы хранения, например, файловой системы...
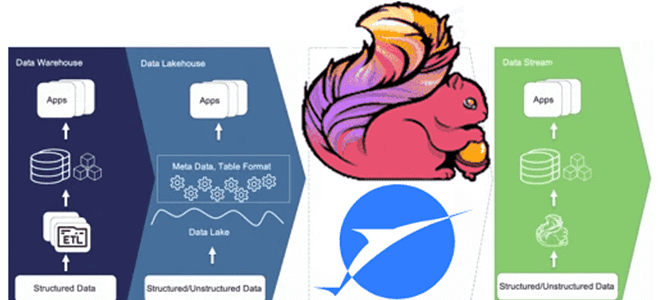
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
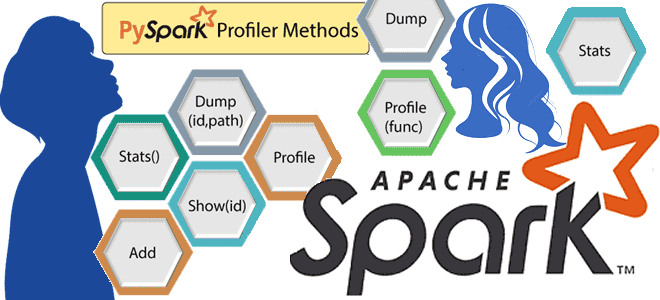
Что такое профилирование кода, зачем это нужно и как работают Python-профилировщики в приложениях Apache Spark. Пример профилирования PySpark-программы. Что такое профилирование и почему это важно для PySpark-приложений Будучи написанном на java и Scala, Apache Spark также поддерживает декларативные API-интерфейсы Python, которые позволяют разработчику писать и запускать код на этом более...

Что такое словарь в ClickHouse, какие бывают словари, как их создать и каким командами к ним обращаться. Пара примеров со словарями в самой популярной колоночной аналитической СУБД. Что такое словарь в ClickHouse Как колоночная база данных, ClickHouse предназначена для аналитической обработки огромных объемов данных в реальном времени. Аналитические сценарии предполагают...
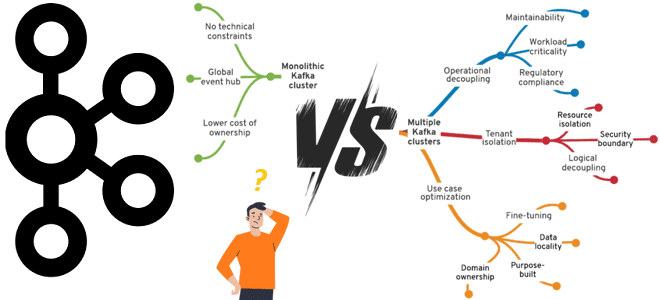
Что выбрать для эффективного управления корпоративным кластером Apache Kafka, от чего зависит уровень централизации и какие факторы влияют на принятие решений. Стратегии управления корпоративным кластером Apache Kafka Типовой вариант использования Apache Kafka – это потоковая интеграция корпоративных приложений. Чтобы эффективно использовать эту платформу потоковой передачи событий в масштабах предприятия, необходимо...
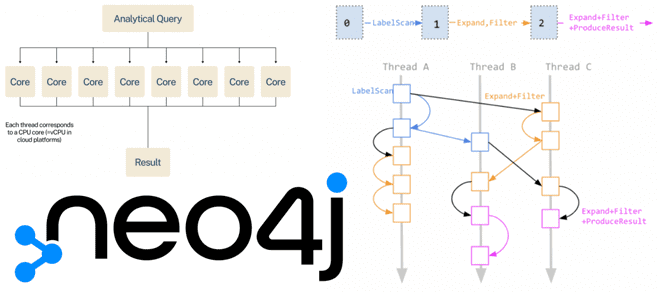
Как разработчики Neo4j улучшают производительность этой графовой СУБД с помощью нового блочного формата хранения данных и параллельной среды выполнения Cypher-запросов. Блочный формат хранения данных Наиболее важной новинкой Neo4j в релизе 5.14, вышедшего в конце ноября 2023 года, стал новый формат хранения данных – блочный, который размещает данные на диске в...
Как выполнить миграцию данных: лучшие практики и рекомендации на примере Greenplum. Особенности и принципы работы утилит gpbackup, gprestore и gpcopy. Миграция данных из Greenplum на 7 с утилитами gpbackup и gprestore Независимо от причины миграции данных из прикладной системы или корпоративного хранилища данных на новую технологию, эта процедура всегда остается...