 1125
1125 
Сегодня разберем, как повысить эффективность использования объектов XCom в Apache AirFlow и сделать свои конвейеры обработки данных еще более гибкими с помощью настройки триггерных правил.
Возможности TaskFlow API для XCom
Объекты XCom позволяют задачам DAG в Apache AirFlow обмениваться данными. Это очень удобно для реализации конвейера с атомарными задачами, которые проще разрабатывать и отлаживать. Подробнее об этом мы писали здесь и здесь, а также показывали на практическом примере здесь и здесь.
Этот механизм позволяет задачам взаимодействовать друг с другом, в т.ч. когда они полностью изолированы и выполняются на разных узлах кластера. XCom идентифицируется по ключу (key), идентификатору задачи (task_id) и идентификатору DAG (dag_id). XCom-объекты хранятся в базе данных метаданных: записываются с помощью метода xcom_push() и извлекаются с помощью метода xcom_pull() в экземплярах задач. Эти переменные могут иметь любое сериализуемое значение, но предназначены только для небольших объемов данных.
Улучшить опыт работы с XCom поможет TaskFlow API, появившийся в AirFlow 2.0. Он обеспечивает кросс-коммуникацию между задачами с помощью обычных Python-функций, используя механизм XCom. Как уже было отмечено выше, в традиционных операторах AirFlow выходные данные можно передать в XCom с помощью метода xcom_push(). Однако при использовании TaskFlow, о котором мы писали здесь и здесь, любая функция Python, украшенная декоратором @task, по умолчанию передает возвращаемое значение в XCom. Поэтому вручную отправлять выходные данные в XCom уже не нужно. Чтобы получить доступ к этим выводам в другой задаче, можно использовать ее свойство .output.
Преобразовать любую Python-функцию в задачу TaskFlow можно с помощью декоратора @task. Если нужно использовать функцию без поведения TaskFlow, то получить доступ к исходной функции можно через ее метод .fn(). А получить обычную задачу из функции, декорированной TaskFlow, поможет ее метод .task. Наконец, чтобы использовать задачу TaskFlow с другими конфигурациями, пригодится метод .override().
Например, следующий участок кода преобразует функцию my_task в задачу TaskFlow:
@task
def my_task(param="default"):
return f"Param is {param}"
Используем ее с другим параметром:
overridden_task = my_task.override({"param": "overridden"})
Вызовем обычное поведение функции:
normal_function_output = my_task.fn()
Получим из задачи TaskFlow обычную функцию:
traditional_task_instance = my_task.task
Это полезно, когда надо преобразовать внешнюю функцию Python в несколько задач на основе отдельных входных данных, например, когда в библиотеке есть устаревший код или общие служебные функции. Вместо того, чтобы переписывать их, можно преобразовать эти функции в задачи Taskflow, и вернуться обратно к обычной функции, когда они не находятся в контексте DAG. Это позволяет легко создавать новые задачи для нескольких DAG из одной функции.
Также создать несколько экземпляров задачи на основе динамического списка ввода позволяет динамическое сопоставление задач, о котором мы писали здесь. Dynamic Task Mapping считается одной из ключевых фич AirFlow 2.3. Эта возможность позволяет программно запускать задачи на основе непредсказуемых входных условий. Экземпляры задач можно настроить как вышестоящие или нижестоящие по отношению к другим задачам, чтобы, например, параллельно обработать несколько файлов перед их массовой загрузкой в одну нижестоящую задачу. И TaskFlow, и традиционные операторы также поддерживают этот метод попеременно. Поэтому Dynamic Task Mapping может сделать любые операции динамичными. Например, следующий код возвращает задаче upstream_task входное значение в качестве выходного, а последующая задача downstream_task принимает переменное количество аргументов (*args). Каждый аргумент будет представлять результат вышестоящей задачи. При определении downstream_task используется список выходных значений оператора upstream_outputs, чтобы передать его в качестве отдельных аргументов. А внутри downstream_task идет перебор полученных аргументов и их вывод на экран.
@task(multiple_outputs=True)
def upstream_task(value):
"""Function to return a value."""
return {"output": value}
@task
def downstream_task(*args):
"""Function for the downstream task."""
for arg in args:
print(f"Received value: {arg['output']}")
# Dynamic values for task instances
values = ['value_1', 'value_2', 'value_3']
upstream_outputs = [upstream_task(value) for value in values]
downstream_task(*upstream_outputs)
Наконец, метод .map() в API TaskFlow предлагает упрощенный подход к преобразованию выходных данных задач. Позволяя задачам динамически применять преобразования к исходным выходным данным, рабочие процессы можно легко адаптировать к различным входным данным без перепроектирования конвейера. К примеру, следующий код обрабатывает список приветствий с помощью .map(), чтобы эффективно применить фильтр ко всем, автоматически пропуская определенные сообщения или добавляя определенные изменения. Это гарантирует, что рабочий процесс останется последовательным и эффективным, независимо от того, как будут меняться входные данные от одного запуска к другому.
@task
def list_strings():
"""Return a list of strings."""
return ["skip_hello", "hi", "skip_hallo", "hola", "hey"]
def skip_strings_starting_with_skip(string):
"""Transform the string based on its content."""
if len(string) < 4:
return string + "!"
elif string[:4] == "skip":
raise AirflowSkipException(f"Skipping {string}; as I was told!")
else:
return string + "!"
@task
def mapped_printing_task(string):
"""Print the transformed string."""
return "Say " + string
# Generate the list of strings
string_list = list_strings()
# Transform the list using the .map() method
transformed_list = string_list.map(skip_strings_starting_with_skip)
# Use dynamic task mapping on the transformed list
mapped_printing_task.map(transformed_list)
Рекомендации по настройке триггерных правил
Задача меняет свое состояние в зависимости от правила ее триггера. По сути, правило триггера меняет поведение задачи, особенно если в DAG есть ветвления. Всего в Apache AirFlow есть 8 правил триггера, о чем мы подробно писали здесь. Например, задача с правилом триггера ALL_DONE будет выполняться всегда, потенциально маскируя сбои. Правило триггера one_failed запустит нижестоящую задачу запускается при сбое хотя бы одной вышестоящей. По умолчанию в AirFlow задано правило триггера all_success, когда зависимая задача выполняется, если все вышестоящие задачи выполнены успешно. Поэтому при проектировании DAG дата-инженеру следует учитывать влияние триггерных правил задач на выполнение и конечное состояние всего конвейера.
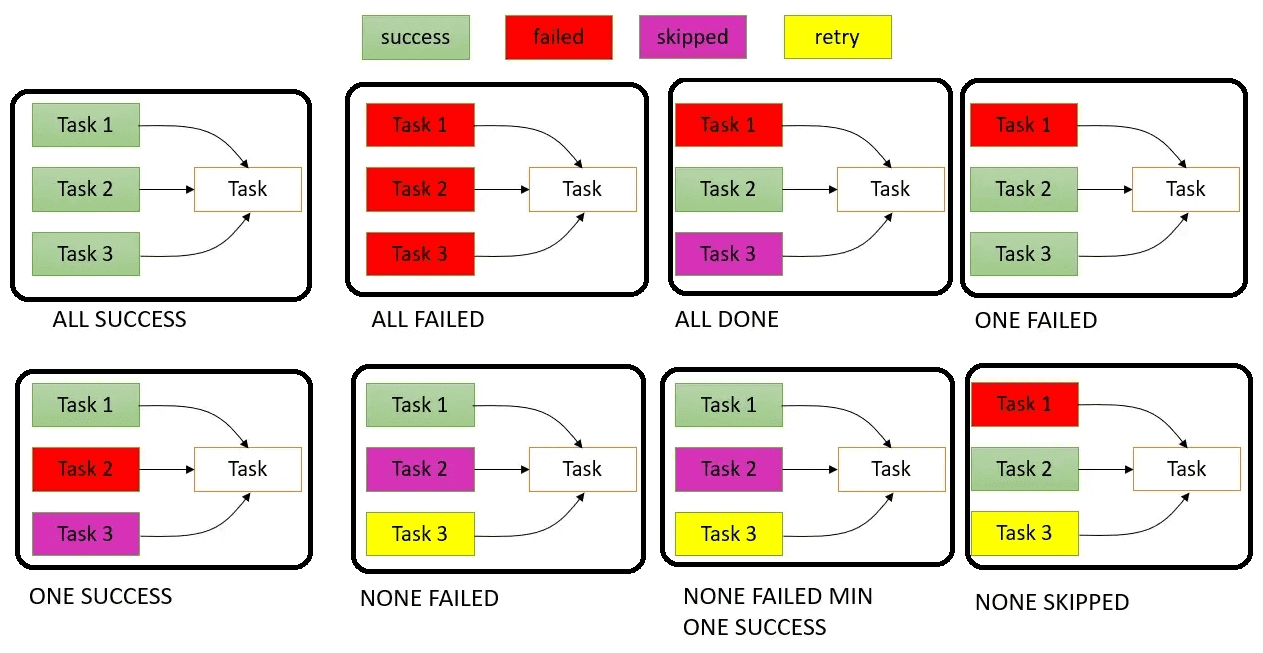
Для нижестоящей задачи конфигурация trigger_rule=TriggerRule.ONE_SUCCESS полезна, когда есть несколько источников данных и надо двигаться по конвейеру дальше, как только любой из них станет доступен. Например, обновление библиотеки контента на платформе потокового мультимедиа из разных провайдеров. Даже если новый контент доступен только у одного провайдера, библиотеку платформы следует обновлять.
А настройка trigger_rule=TriggerRule.ALL_FAILED пригодится для оповещения или отката назад, например, при использовании нескольких систем резервного копирования для хранения критически важных данных. Если все процессы резервного копирования завершаются сбоем, должно быть активировано предупреждение, уведомляющее администраторов и DevOps-инженеров о необходимости ручного вмешательства.
Правило trigger_rule=TriggerRule.NONE_FAILED_OR_SKIPPED полезно, чтобы задача выполнялась независимо от того, были ли ее зависимости пропущены из-за условий ветвления. Например, процесс создания ежедневных отчетов собирает данные из различных отделов. Даже если некоторые отделы не предоставляют данные в определенные дни (и их задачи пропускаются), отчет все равно надо формировать на основе имеющихся данных.
Конфигурация trigger_rule=TriggerRule.ONE_FAILED нужна для обработки ошибок или оповещения, если что-то пойдет не так в любой из вышестоящих задач. К примеру, в многозадачном конвейере проверки данных, если на каком-либо этапе обнаруживается аномалия или происходит сбой, должна запускаться задача обработки ошибок, чтобы зарегистрировать проблему и предупредить дата-инженеров.
Наконец, trigger_rule=TriggerRule.NONE_FAILED позволит выполнять последующие операции на основе результата предыдущей конкретной задачи. Например, в процессе запуска продукта несколько задач связаны с логистикой, маркетингом и запасами, но финальная задача запуска должна выполняться только в том случае, если задача проверки качества выполнена успешно.
В заключение отметим, что добавленные в AirFlow 2.7 задачи установки/демонтажа для создания и удаления ресурсов, о чем мы писали здесь, по сути представляют собой особый тип триггерного правила. Они позволяют управлять ресурсами до и после определенных задач в DAG. Задача установки предназначена для подготовки необходимых ресурсов или условий для выполнения последующих задач. А задача демонтажа предназначена для очистки или демонтажа этих ресурсов после завершения задач, которые от них зависят, независимо от статуса их выполнения. Использование этих задач сокращает потребление ресурсов хранения и вычислений, повышая эффективность конвейера обработки данных на Apache AirFlow.
Узнайте больше про Apache AirFlow и его практическое использование в дата-инженерии на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

