
Чем ML-сценарии работы с данными отличаются от типовых аналитических нагрузок и почему колоночные форматы не справляются с ними: сложности Parquet и ORC в хранении данных для машинного обучения. Почему колоночные форматы не справляются со всеми ML-сценариями Хотя колоночный формат хранения данных хорошо подходит для многих современных сценариев, таких как машинное...
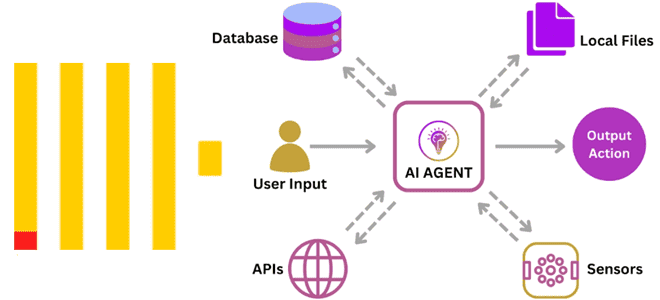
Зачем использовать ClickHouse для аналитики в реальном времени с агентами ИИ и как это сделать: современные вызовы внедрения LLM. Как реализовать ML-систему агентского ИИ с ClickHouse Продолжим разговор про агентский ИИ на основе LLM, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого...
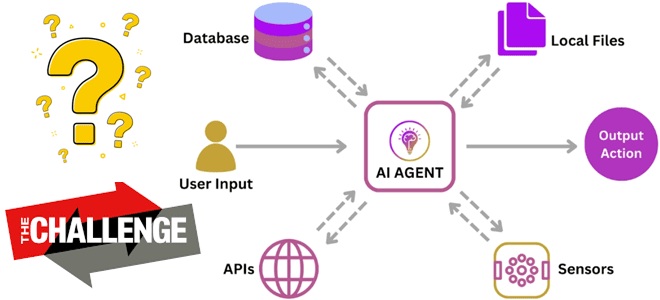
Чем хорош агентский ИИ, какие риски и проблемы с ним связаны, и как их избежать: технические и организационные меры внедрения ML-систем в реальный бизнес. Что сдерживает внедрение агентского ИИ Мы уже писали об агентском ИИ, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без...

Почему генеративный ИИ основан на потоковой обработке данных и EDA-архитектуре, для чего оценивать качество LLM-модели и как построить такую систему мониторинга: подходы и технологии. О важности потоковой обработки данных и EDA-архитектуры для LLM-систем Все больше современных бизнес-приложений включают в себя большие языковые модели (LLM, Large Language Model), чтобы автоматизировать поддержку...
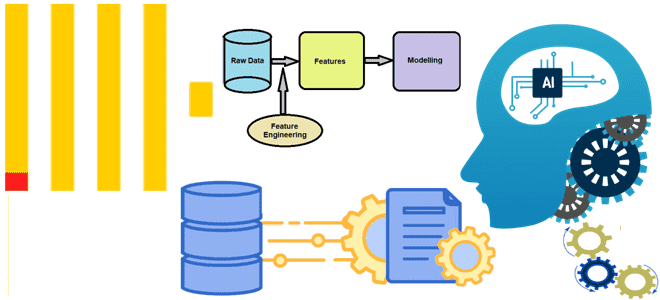
Что такое хранилище признаков, зачем это нужно в машинном обучении, каковы его главные компоненты и как использовать ClickHouse в качестве Feature Store для ML-задач. Хранилище признаков для машинного обучения: архитектура и принципы работы Feature Store Будучи колоночной базой данных, ClickHouse отлично подходит на роль хранилища фичей (Feature Store) для задач...

Как решать задачи машинного обучения в Greenplum с агентом gpMLBot и расширением PostgresML: возможности, ограничения и примеры. Что такое gpMLBot: Greenplum Automated Machine Learning Agent Чтобы использовать Greenplum как хранилище данных в задачах машинного обучения, в этой БД поддерживаются соответствующие механизмы. Одним из них является библиотека Apache MADlib, о которой...
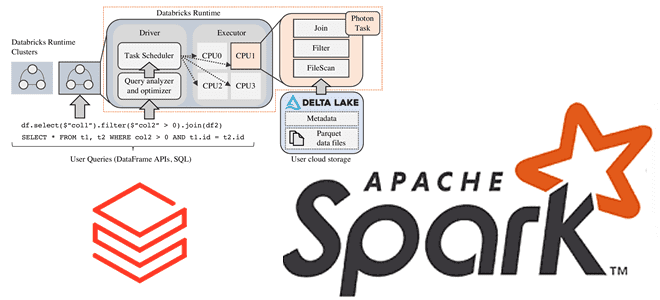
Зачем Databricks выпустила новый движок выполнения запросов Spark SQL для ML-приложений, как он работает и где его настроить: возможности и ограничения Photon Engine. Преимущества Photon Engine для ML-нагрузок Spark-приложений Чтобы сделать Apache Apark еще быстрее, разработчики Databricks выпустили новый движок выполнения запросов - Photon Engine. Это высокопроизводительный механизм запросов, который...
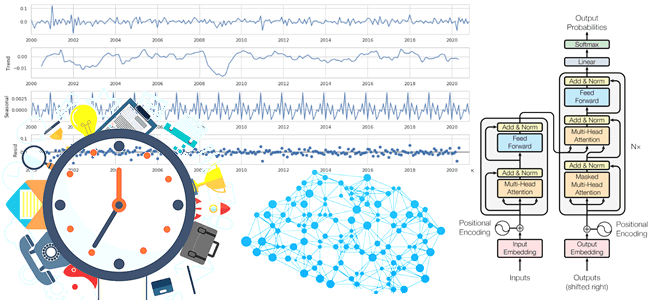
Почему генеративный ИИ хорошо подходит для прогнозирования временных рядов, как архитектура трансформеров учитывает влияние внешних переменных и сезонных факторов на измерения, и какие нейросетевые модели можно попробовать для этих задач. Проблемы прогнозирования временных рядов и их нейросетевые решения Прогнозирование временных рядов всегда было востребованной задачей в различных отраслях бизнеса. Временной...
Зачем Databricks выпустил Arc, чем это отличается от Splink, и как эти инструменты позволяют решать проблему связывания данных с помощью алгоритмов машинного обучения. Как работает связывание данных Продолжая разговор про качество данных и разрешение сущностей (entity resolution) , сегодня подробно рассмотрим этап связывания записей с использованием логики на основе правил...
Как качество данных связано с разрешением сущностей, чем entity resolution отличается от identity resolution, зачем нужны графы идентичности, как их построить и где использовать. Борьба за качество данных с entity resolution Результаты аналитической обработки данных напрямую зависят от их качества, о ключевых показателях и задачах обеспечения которого мы писали здесь....