 991
991 
Содержание
Чем ML-сценарии работы с данными отличаются от типовых аналитических нагрузок и почему колоночные форматы не справляются с ними: сложности Parquet и ORC в хранении данных для машинного обучения.
Почему колоночные форматы не справляются со всеми ML-сценариями
Хотя колоночный формат хранения данных хорошо подходит для многих современных сценариев, таких как машинное обучение или сложные аналитические запросы к большим наборам информации, он имеет некоторые проблемы с производительностью. Исторически колоночное хранение появилось позже строкового, когда все данные в одной строке таблицы располагаются вместе.
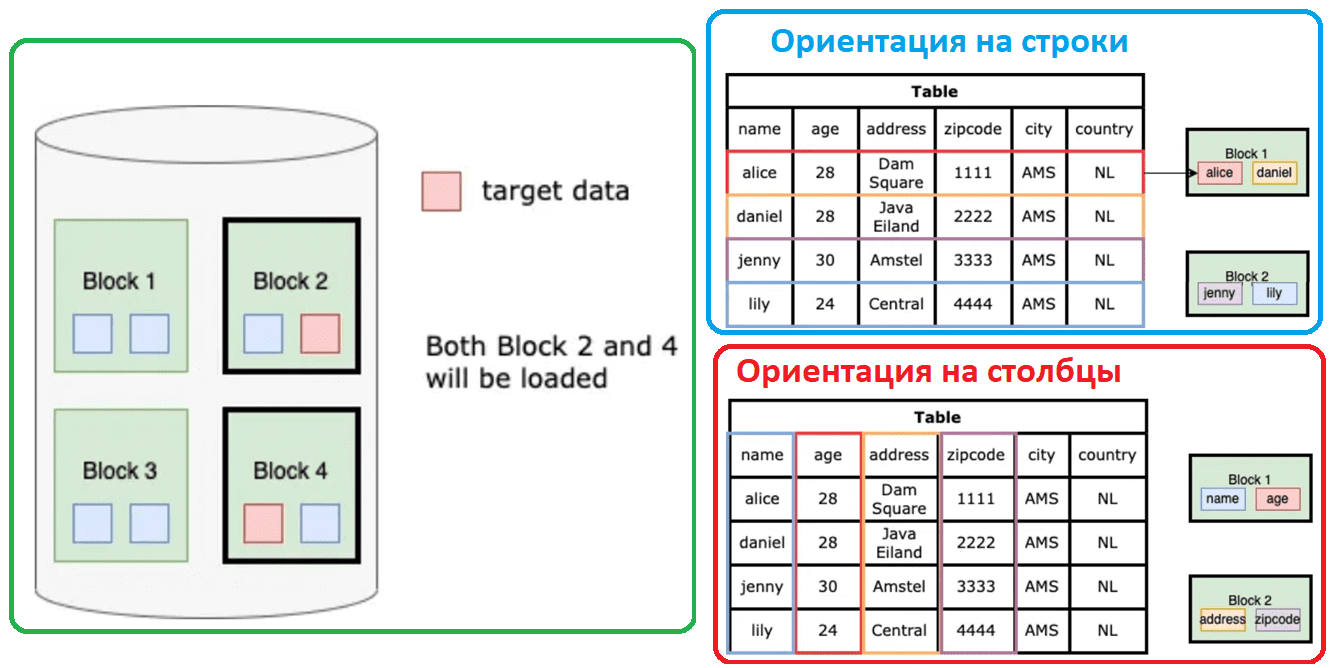
В 2013 году были выпущены два крупных проекта Apache Software Fondation: Parquet и ORC – открытые форматы файлов, которые упорядочивают данные в столбцы. Многие системы аналитической обработки больших объемов данных с открытым исходным кодом (Hadoop, Spark, Trino и пр.), поддерживают эти форматы файлов. Современные архитектуры данных, такие как Data Lake и LakeHouse тоже работают с этими форматами, позволяя обращаться к данными в столбцах с помощью классических SQL-запросов. Это неудивительно, поскольку в основе Parquet и ORC лежат технологии для традиционного анализа данных с помощью SQL, где типовыми рабочими нагрузками считаются следующие:
- сканирование больших объемов данных;
- соединения, сортировки, группировки и относительно простые агрегации, такие как вычисление суммы, среднего значения и количества вхождений.
Однако, в машинном обучении встречаются совершенно другие сценарии. Например, итеративные алгоритмы обучения, такие как градиентный спуск, требуют многократного прохода по одним и тем же данным для обновления моделей. Структура хранения данных в столбцах оптимизирована для одноразового сканирования, что приводит к множественным чтениям одного и того же столбца, снижая эффективность. Кроме того, Machine Learning часто предполагает выполнение сложных математических операций и трансформаций данных, например, нормализацию, создание новых признаков или взаимодействие между ними. Эти операции требуют доступа к различным столбцам одновременно и выполнения оперативных вычислений, что неудобно в колоночных форматах, ориентированных на партиционированное хранение.
В ML часто приходится иметь дело с разреженными матрицами и неравномерным распределением данных, что затрудняет эффективное хранение и обработку в колоночных форматах, изначально оптимизированных для плотных и равномерно распределенных данных. Некоторые модели машинного обучения требуют агрегации данных во времени или на регулярной основе, что может быть сложно реализовать с использованием стандартных SQL-агрегаций, оптимизированных для одноразового выполнения.
Модели машинного обучения часто требуют постоянного обновления данных и быстрой индексации новых записей. Колоночные форматы оптимизированы для операций чтения и записи больших блоков данных целиком, а не для частых вставок и обновлений. Наконец, многие ML-приложения требуют обработки данных в реальном времени или с минимальной задержкой. Колоночные форматы, ориентированные на пакетную обработку, не обеспечивают необходимую скорость и гибкость для таких сценариев.
Еще 3 проблемы колоночных форматов
Помимо вышеперечисленных сложностей с реализацией ML-сценариев на колоночном хранении данных, обработка столбцов не всегда эффективна из-за сериализации и десериализации данных. Часто таблицы входных данных для ML-алгоритмов являются одновременно очень широкими и разреженными и содержат широкий спектр признаков, каждый из которых представлен отдельным столбцом. С одной стороны, колоночные хранилища являются идеальным решением для таких широких таблиц, т.к. можно читать только нужные данные, избегая полного сканирования всей строки со множеством столбцов.
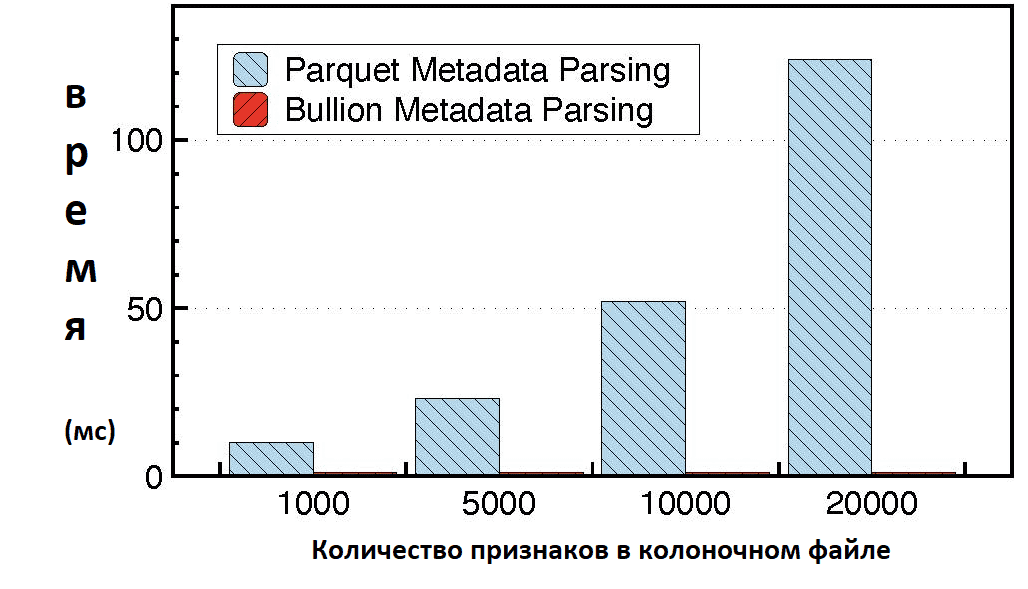
С другой стороны, чтобы найти эти столбцы, необходимо десериализовать и проанализировать метаданные. Для очень широких и разреженных таблиц время чтения метаданных может превышать время выполнения самого запроса. Это подтверждают эксперименты, в которых измерялась производительность чтения данных в формате Parquet. Java-реализация этого формата (parquet-java) использовалась для извлечения одного столбца из набора данных, состоящего из переменного числа признаков. Производительность Parquet существенно зависит от числа столбцов признаков, при этом время извлечения линейно увеличивается с числом признаков. По мере того, как таблицы становятся шире и разреженнее, время чтения метаданных становится более значительным и более проблематичным. В качестве альтернативы Parquet рассматривался Bullion – колоночная система хранения, адаптированная для рабочих нагрузок машинного обучения. Bullion решает сложности соответствия данных, оптимизирует кодирование длинных последовательностей разреженных признаков, эффективно управляет проекциями широких таблиц. Также Bullion обеспечивает квантование признаков в хранилище и последовательное чтение с учетом качества для мультимодальных обучающих данных. Наконец, эта колоночная система хранения предоставляет комплексную каскадную структуру кодирования, которая объединяет различные схемы сериализации с помощью модульных интерфейсов и обеспечивает прямой доступ к метаданным из нижних колонтитулов файлов. Этот метод позволяет устранить накладные расходы на чтение метаданных, повышая производительности.
Другим примером, показывающим проблемы популярных колоночных форматов для ML-нагрузок, является векторная обработка. Большинство алгоритмов машинного обучения используют числовые векторы в качестве входных данных, что мы разбирали здесь. Например, в рекомендательных системах нужно хранить события пользовательского поведения, совершенные с рекомендуемыми объектами. Предположим, есть столбец признаков clk_seq_cids, который представлен как вектор из 256 элементов int64 (list<int64> в Parquet), где каждый элемент представляет собой идентификатор объявления, на которое кликнул пользователь. Этот признак используется для отслеживания взаимодействия пользователя с рекламными кампаниями с течением времени.

Поскольку таблицы пользователей часто сортируются сначала по идентификатору пользователя, а затем по временной метке, столбец clk_seq_cids похож на временной ряд или скользящее окно, где последовательные значения в столбце отличаются лишь незначительно. Вектор особо не меняется существенно между разными моментами времени для одного и того же пользователя. Поэтому для хранения этого столбца можно применить схему сжатия дельта-кодирования, оптимизированную для скользящих окон. Это не только уменьшит размер столбца в хранилище, но и сократит время ввода-вывода для чтения в столбце и потенциально снизит затраты ЦП для операторов, которые могут работать напрямую с дельта-сжатыми данными без их предварительной распаковки.
Однако, текущие реализации дельта-кодирования в большинстве колоночных форматов хранения включая Parquet и ORC, поддерживают только стандартные примитивные типы данных: INT, BIGINT, DATE, TIMESTAMP, DECIMAL и пр. Отсутствие встроенных оптимизаций для сложных типов, таких как временные ряды или скользящие окна, снижает производительность их обработки. Это обусловлено историей развития колоночных форматов для рабочих нагрузок SQL, где векторы не встречаются редко. Впрочем, с учетом интереса к ML, возможно уже в скором будущем колоночные хранилища будут включать собственную поддержку и оптимизации векторных типов данных.
Наконец, как уже было сказано, колоночные хранилища ориентированы на чтение, а не на мутации данных. Поэтому довольно сложно обеспечить соблюдение требований GDPR, CCPA, CPRA и VCDPA, которые предписывают физическое удаление пользовательских данных в указанные сроки. Поскольку каждый столбец в строке хранится отдельно. Поэтому один запрос на удаление строки приводит к множеству отдельных изменений: по одному для каждого столбца в этой строке. Кроме того, колоночные форматы часто используют сжатие на основе блоков, что усложняет прямые изменения отдельных строк. Без оптимизации удаление одной строки в колоночном хранилище может потребовать перезаписи всего файла, что приведет к значительному потреблению ресурсов на IO-операции.
Поэтому в колоночном хранилище применяются векторы удаления, которые используют битовые карты для маркировки удаляемых строк. Векторы удаления отмечают изменения, не требуя перезаписи всего файла; вместо этого при считывании данных векторы объединяются с необработанными считываемыми данными, предотвращая попадание удаленных данных к операторам ниже по потоку. Поскольку этот подход физически не удаляет данные, а просто скрывает их от последующих чтений, он не соответствует правилам стандартов, требующим своевременного физического удаления.
Поэтому, вероятно, что в будущем колоночные форматы будут использовать алгоритмы сжатия и контрольные суммы, которые не требуют распаковки и перезаписи больших фрагментов данных только для удаления одной строки. Вместо этого можно применить кодирование словаря, бит-упакованное кодирование, дельта-кодирование и схемы кодирования длины серии, которые поддерживают четкое разграничение между строками, чтобы удалять их без необходимости распаковки окружающих данных. Хотя это немного снизит коэффициенты сжатия, производительность в целом будет улучшена, а требования регуляторов – удовлетворены.
Таким образом, современные колоночные форматы данных не всегда подходят для задач машинного обучения, где требуется гибкость, высокая динамика, сложные трансформации, итеративные процессы и быстрое точечное удаление. Поэтому активно развиваются новые форматы и системы хранения, оптимизированные под специфические ML-нагрузки, например, уже упомянутая Bullion или Nimble, о которых мы поговорим в следующий раз.
Узнайте больше про машинное обучение и ИИ на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

