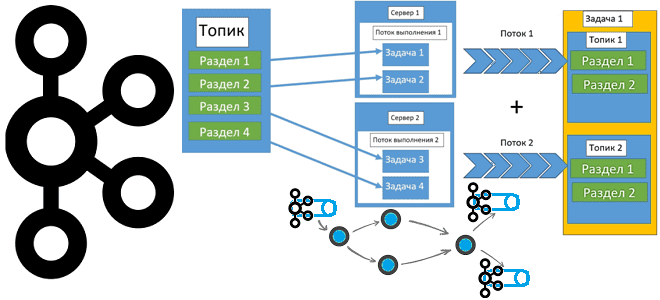
Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов, и как это все-таки сделать без изменения конфигурации топика. Почему нельзя просто взять и соединить потоки Kafka Streams с разным числом разделов Kafka Streams – это клиентская Java-библиотека для разработки потоковых приложений, которые работают с данными, хранящимися...

В конце декабря принято строить планы на следующие 12 месяцев. Посмотрим, что разработчики Apache Flink обещают реализовать в релизе 2.0, который должен выйти к концу 2024 года. Внедрение многоуровневой системы хранения состояний В Apache Flink 2.0 будет улучшена система управления хранилищем состояния путем перехода к полностью разделенной архитектуре хранения и...
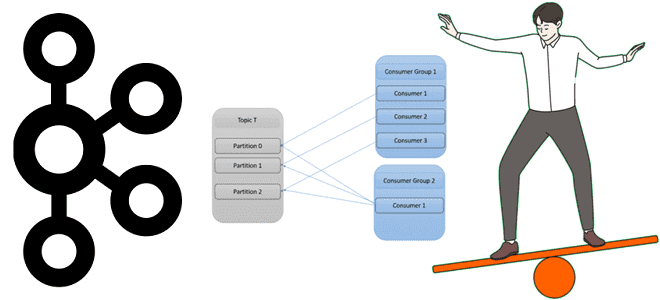
Чем group.instance.id отличается от group.id, зачем нужен member.id, каковы преимущества статического членства в группе потребителей перед динамическим и какие механизмы Kafka обеспечивают ребалансировку клиентских приложений. Еще раз про группы потребителей Apache Kafka Напомним, группы потребителей в Apache Kafka нужны для логического объединения нескольких потребителей с целью повышения надежности потоковой системы....
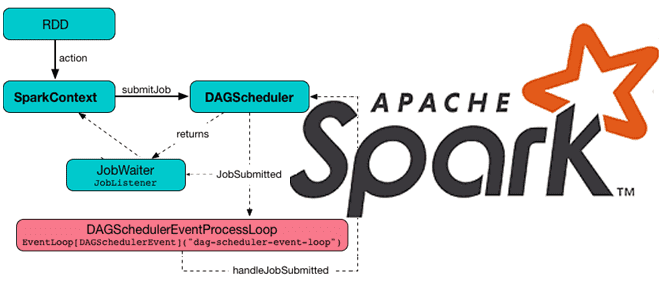
Какие механизмы и компоненты позволяют Apache Spark планировать задания и эффективно утилизировать ресурсы кластера. Чем статическое разделение ресурсов отличается от динамического, и как настроить планировщик для ускорения вычислений. Планирование заданий в Apache Spark Распределенный характер Apache Spark предполагает наличие инструментов для разделения ресурсов между вычислениями. В режиме кластера каждое приложение...

Сегодня познакомимся с возможностями и ограничениями open-source проект Diskquota, направленного на оптимизацию управления дисковым пространством базы данных Greenplum. Зачем ограничивать использование диска в Greenplum и как это сделать Эффективная утилизация аппаратных ресурсов, в т.ч. жесткого диска – один из факторов, позволяющих ускорить работу любой СУБД, в т.ч. Greenplum. Будучи популярным...
Анализ временных рядов нужен не только в Data Science, но и в мониторинге системных событий. Чем столбец с отметками времени в ClickHouse отличается от гипертаблиц в PostgreSQL и Greenplum c расширением TimescaleDB, и что выбирать для аналитики больших данных. ClickHouse для анализа временных рядов ClickHouse является колоночной СУБД для аналитической...

Что лучше: один или несколько кластеров Apache Kafka, когда и зачем разворачивать новый кластер вместо масштабирования существующего, какие задачи администрирования поручить локальным DevOps-инженерам, а что решать централизовано. Один или несколько кластеров Apache Kafka? Продолжая разговор про эффективное управление корпоративным кластером Apache Kafka, сегодня рассмотрим, когда и зачем нужно разворачивать новый...

Зачем размещать задания Apache Spark на узлах HDFS, какую пропускную способность сети передачи данных выбрать, почему не рекомендуется использовать RAID для жестких дисков, сколько выделить памяти и ядер ЦП. Рекомендации по настройке оборудования для Spark-приложений На практике большинство заданий Spark считывает входные данные из внешней системы хранения, например, файловой системы...
Что не так с архитектурой данных Lakehouse, зачем разработчики Apache Flink создали на основе табличного хранилища новую дата-платформу, чем хорош подход Streamhouse и как устроен Apache Paimon. Что такое архитектура данных Streamhouse Не успели дата-архитекторы освоиться с Lakehouse – архитектурой данных, которая объединяет преимущества хранилищ и озер данных, комбинируя масштабируемость...
Что такое профилирование кода, зачем это нужно и как работают Python-профилировщики в приложениях Apache Spark. Пример профилирования PySpark-программы. Что такое профилирование и почему это важно для PySpark-приложений Будучи написанном на java и Scala, Apache Spark также поддерживает декларативные API-интерфейсы Python, которые позволяют разработчику писать и запускать код на этом более...