 889
889 
В конце декабря принято строить планы на следующие 12 месяцев. Посмотрим, что разработчики Apache Flink обещают реализовать в релизе 2.0, который должен выйти к концу 2024 года.
Внедрение многоуровневой системы хранения состояний
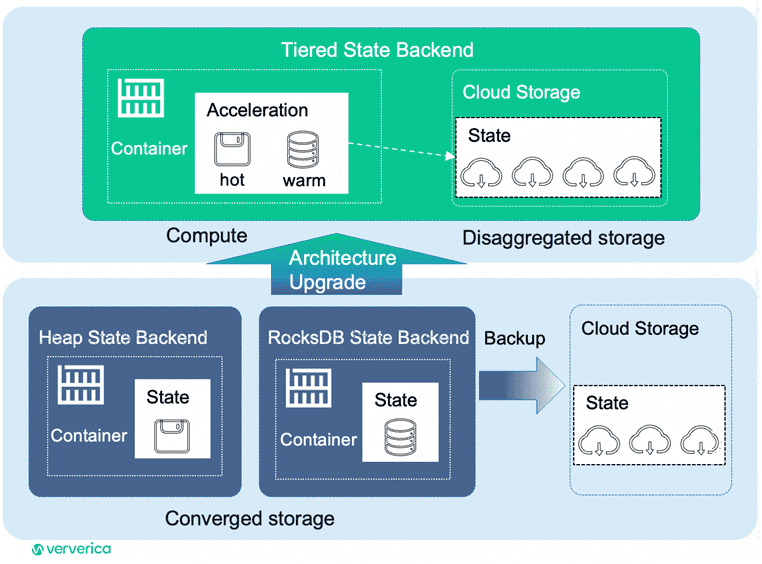
В Apache Flink 2.0 будет улучшена система управления хранилищем состояния путем перехода к полностью разделенной архитектуре хранения и вычислений, соответствующей требованиям облачной среды. Пока система хранения состояний Flink не полностью воплощает архитектуру разделения хранения и вычислений. Все данные о состоянии хранятся в локальных экземплярах встроенной key-value СУБД RocksDB, и во время распределенных моментальных снимков в удаленное хранилище передаются только инкрементальные данные, чтобы гарантировать удаленное хранение полных данных о состоянии. Планируется, что Flink будет полностью перемещать данные о состоянии в удаленное хранилище, используя локальные диски и память исключительно для кэширования и ускорения. Это позволит создать многоуровневую систему хранения, многоуровневую архитектуру состояния бэкэнда.
Для этого предлагается внедрить многоуровневый подход к системе хранения данных, чтобы для оптимизации производительности доступа хранить их на разном оборудовании в зависимости от сценариев использования. Также для повышения производительности будет внедрена оптимизация запросов: хэш-индексация или сортированная индексация.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
31 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Изменение API Apache Flink
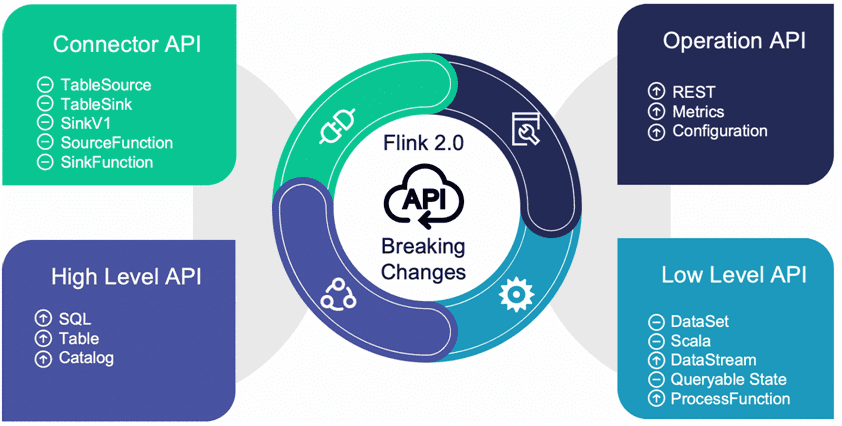
Как мы недавно рассказывали здесь, пока Apache Flink предоставляет 3 API для разработчика: низкоуровневый ProcessFunction, базовый DataStream/DataSet, а также декларативный табличный API и SQL. В версии 2.0 будет выполнена реструктуризация API с явным выделением следующих категорий:
- низкоуровневый API с processFunction и DataStream;
- высокоуровневый табличный API и SQL;
- API коннекторов с функциями источников и приемников данных;
- операционный API для мониторинга и управления, который включает метрики, конфигурацию и RESTful API.
Переход будет реализован в два этапа: сперва будут выполнены кардинальные изменения, связанные с удалением устаревших элементов API, таких как DataSet, SourceFunction и SinkFunction, TableSource и TableSink. Также будут очищены устаревшие классы, методы, поля в Java API и устаревшие параметры конфигурации, метрики и конечные точки REST API. Второй этап представляет собой редизайн API, который предполагает внедрение нового API состояния с возможностью запроса после реализации дезагрегированного состояния, а также рефакторинг API DataStream с использованием новой ProcessFunction. Это поможет устранить внутренние зависимости и предотвратить раскрытие внутренних API. Также будет выполнен рефакторинг конфигураций.
Несмотря на то, что Flink имеет надежную основу для низкоуровневого манипулирования потоками данных, для большинства конечных пользователей рекомендуется использовать SQL. SQL предоставляет высокоуровневый декларативный API, знакомый большинству дата-инженеров и разработчиков. Это позволяет им сосредоточиться на бизнес-логике предметной области, не тратя силы на тонкости обработки данных и непрерывной оптимизации. Уже сегодня Flink поддерживает DDL и DML-запросы, агрегацию и соединения. Однако, чтобы использовать потенциал Flink SQL более активно, его можно разделить на четыре основных типа:
- OLTP SQL — для традиционных манипуляций с данными и выполнения SQL-запросов;
- OLAP SQL — для ETL-процессов хранилища данных;
- Stream SQL — для уникальной логики обработки потоковых данных, включая оконные функции;
- Data Lake SQL — для выполнения общих задач архитектуры данных LakeHouse, например, создание таблиц и пр.

Благодаря этим мощным возможностям SQL пользователи могут решать широкий спектр задач привычными средствами. В версии 2.0 ожидается поддержка еще большего количества SQL-операторов для покрытия всех сценариев использования с помощью этого инструмента.
В заключение рассмотрим процесс выпуска релизов:
- сперва выйдет выпуск 1.19, затем через 4-5 месяцев 1.20, и к концу 2024 года можно ожидать версию 2.0;
- публичные API должны быть признаны устаревшими в версии 1.19, а API PublicEvolving — в версии 1.20, чтобы удалить их в версии 2.0;.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
31 марта, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

