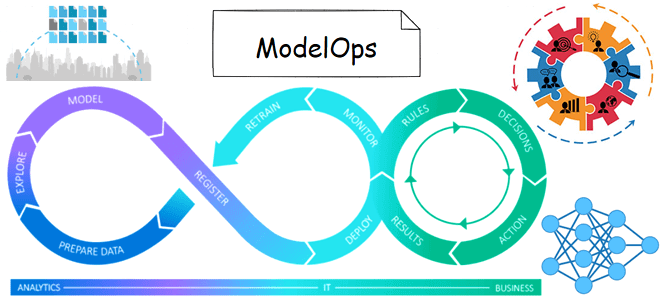
Пока инженеры данных и специалисты по Data Science привыкали к MLOps, начав понимать важность и необходимость этой концепции непрерывной разработки и эксплуатации систем машинного обучения, в Data Science появился новый термин с модным –Ops окончанием. Разбираемся, что такое ModelOps, чем это отличается от MLOps и как применить его на практике....
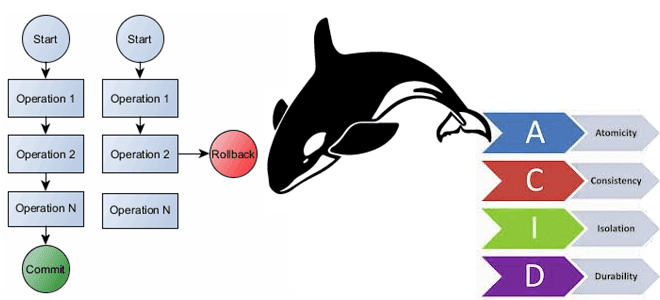
В этой статье для обучения архитекторов, дата-инженеров и аналитиков данных рассмотрим, как поддерживаются транзакции в Apache HBase и почему к ACID-свойствам также добавляется характеристика видимости обновлений. Насколько атомарны и консистентны мутации данных внутри строки HBase, почему сканирование не полностью согласовано и как разрешить устаревшие чтения или путешествия во времени в...

Сегодня рассмотрим несколько полезных приемов по работе с Apache Hive, которые пригодятся инженеру данных и специалисту по Data Science в проектах аналитики больших данных. Как разделить и сегментировать таблицы, зачем изменять значение конфигурации памяти этапов MapReduce, чем полезна автоматическая обработка асимметрии данных и еще пара лайфхаков для ускорения выполнения SQL-запросов...
Недавно мы писали про проблемы приложений Apache Flink в кластере Kubernetes. Сегодня рассмотрим, каким образом можно развернуть и запустить задания этого фреймворка распределенной обработки данных на самой популярной DevOps-платформе контейнерной виртуализации. Обзор операторов от Lyft, Google Cloud Platform, нативного расширения и возможностей платформы Ververica. Зачем и как выполнить развертывание Apache...

Хотя распределенные системы с микросервисной архитектурой дают множество преимуществ, процесс их проектирования достаточно сложен. В частности, нужно учитывать возможность возникновения неопределенности параллелизма или состояния гонки, и заранее предусмотреть способы решения этих проблем. Одним из них является Apache Kafka, которая гарантирует упорядоченность событий. Рассмотрим на практическом примере, как это работает. Что...

28 июня 2022 года в сотрудничестве с сообществом разработчиков Apache Spark компания Databricks анонсировала проект Lightspeed, новое поколение этого потокового движка. Читайте далее, что это такое и чем оно отличается от классического Apache Spark Structured Streaming. Потоковая обработка данных с Apache Spark Structured Streaming Потоковая передача событий весьма востребована современным...
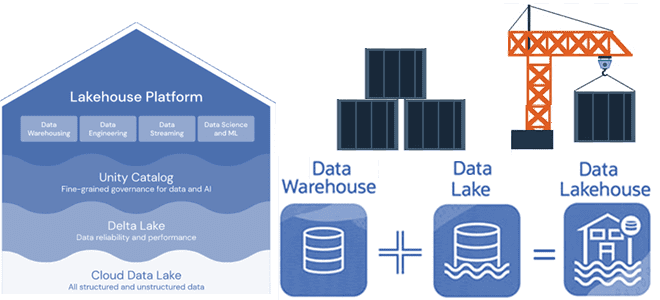
Недавно мы писали про новую гибридную архитектуру Lakehouse, которая объединяет лучше из мира озер и хранилищ данных. Сегодня разберем принципы работы и особенности построения этой архитектуры данных, включая технологии ее реализации с точки зрения дата-инженера и уделим внимание организации конвейеров аналитики больших данных. Архитектурная парадигма Lakehouse Напомним, Lakehouse — это...
Недавно мы рассказывали про стратегии обработки ошибок в потоковых конвейерах данных на Apache NiFi. В продолжении этой темы, сегодня более детально разберем, с какими исключениями может столкнуться дата-инженер, о чем они говорят и как их обойти. Виды исключений Apache NiFi При разработке собственного процессора может возникнуть несколько различных неожиданных ситуаций....

Сегодня рассмотрим, с какими нетиповыми ошибками может столкнуться дата-инженер при работе с Apache Flink, а также как решить эти проблемы. Где и что править, когда сервер BLOB-объектов завис из-за слишком большого количества подключений, почему не хватает памяти при развертывании Flink-приложений в кластере Kubernetes и как ускорить инициализацию заданий. Особенности работы...
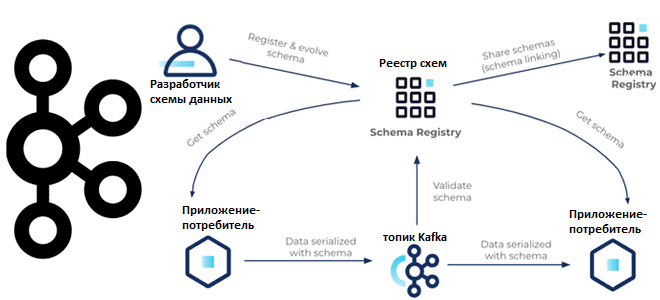
С какими проблемами качества данных сталкивается дата-инженер при работе с Apache Kafka и как реестр схем поможет их решить. Чем формат сериализации Apache AVRO отличается от JSON и Protobuf, как использовать Schema Registry и обеспечить совместимость данных: краткое пошаговое руководство для дата-инженера. Качество данных и реестр схем Apache Kafka Низкое...