 736
736 
Содержание
Хотя распределенные системы с микросервисной архитектурой дают множество преимуществ, процесс их проектирования достаточно сложен. В частности, нужно учитывать возможность возникновения неопределенности параллелизма или состояния гонки, и заранее предусмотреть способы решения этих проблем. Одним из них является Apache Kafka, которая гарантирует упорядоченность событий. Рассмотрим на практическом примере, как это работает.
Что такое состояние гонки или проблемы многотопочности и параллелизма в распределенных системах
Состояние гонки или неопределенность параллелизма считается ошибкой проектирования многопоточной системы, когда ее работа зависит от того, в каком порядке выполняются части кода. Сложность отладки этой ошибки в том, что она возникает в случайные моменты времени и пропадает при попытке её локализовать. Хотя вероятность такой ошибки в распределенных системах низкая, в случае Big Data платформ она обязательно реализуется из-за большого количества сервисов и огромного количества событий, потребляемых ими. Например, может случиться проблема, которая имеет один шанс на миллион. Но если сервис обрабатывает около 100 сообщений в секунду, эта ошибка возникает примерно 3 раза в час. Огромный масштаб и пропускная способность микросервисов, управляемых событиями, делают состояние гонки вполне вероятным.
Итак, состояние гонки — это нежелательное и неожиданное поведение, возникающее при параллельном выполнении кода в многопоточном режиме. Проблемы параллелизма незаметны и часто проявляются только в производственных средах из-за огромной разницы в пропускной способности между локальными или рабочими средами или средами разработки. Поэтому неизбежность этих проблем параллелизма и высокая пропускная способность сервисов, управляемых событиями, подчеркивают необходимость продуманной стратегии проектирования таких распределенных систем. При этом следует помнить, что в сервисах, управляемых событиями, есть возможность горизонтального масштабирования путем добавления нескольких экземпляров одного и того же сервиса. Этот подход делает недействительными традиционные способы борьбы с состоянием гонки путем выполнения блокировки в памяти, поскольку разные запросы могут направляться к разным экземплярам. Распределенные системы часто используют внешние инструменты для управления распределенным параллелизмом, например, Apache Zookeeper. Однако использование сервисов, управляемых событиями, может привести к существенному изменению концепции параллелизма. Сквозная маршрутизация сообщений может быть очень эффективным и масштабируемым подходом к решению проблемы параллелизма с помощью общего архитектурного решения, а не внешних инструментов или реализации конкретного сервиса.
Проиллюстрируем это на практическом примере. Предположим, онлайн-маркетплейс продает продукты и позволяет пользователям подписываться на уведомления о новинках и появлении заинтересовавших их товаров снова в наличии. Пользователь может подписаться на получение уведомлений по электронной почте, SMS, мобильному приложению и пр. о том, что запас заинтересовавшего клиента продукта увеличился. Сервис, хранящий информацию о товарах и запасах, отправляет событие при изменении товарного запаса. Служба подписки должна понимать, когда продукты меняются со склада 0 на 1, и отправлять уведомление всякий раз, когда это происходит.
Служба подписки обрабатывает события ProductStockIn, чтобы реагировать на изменения складских запасов товара. Поскольку подписки актуальны только при изменении запаса с 0 на 1, служба сохраняет внутреннее состояние с текущим запасом каждого продукта. Поток события ProductStockIn состоит из следующих действий:
- Сервис продукта публикует событие;
- Служба подписки обрабатывает событие;
- Выполняется получение сведений о запасах и проверка, изменился ли запас с 0 до 1;
- Выполняется получение информации о текущих подписках;
- Отправляется уведомление для каждой подписки;
- Данные о местных запасах обновляются.
В однопоточной парадигме эта последовательность действий не вызовет никаких проблем. Но для повышения эффективности процессов и достижения разумной производительности следует добавить в сервис параллелизм. Но если сервис обработает два или более событий, может случиться состояние гонки, что приведет к тому, что одна и та же подписка будет опубликована дважды. Если сервис обрабатывает два события смены запаса, например, с 0 на 1 и с 1 на 2, одновременно выполняя проверку на шаге 3, она будет проходить в обоих событиях, создавая состояние гонки и отправляя одно и то же уведомление дважды.
Классический способ решения этой проблемы состоит в простой блокировке выполнения потока с помощью традиционных методов обработки параллелизма: мьютекс, семафор и пр. Но традиционные способы подходят только для сервисов с одним экземпляром.
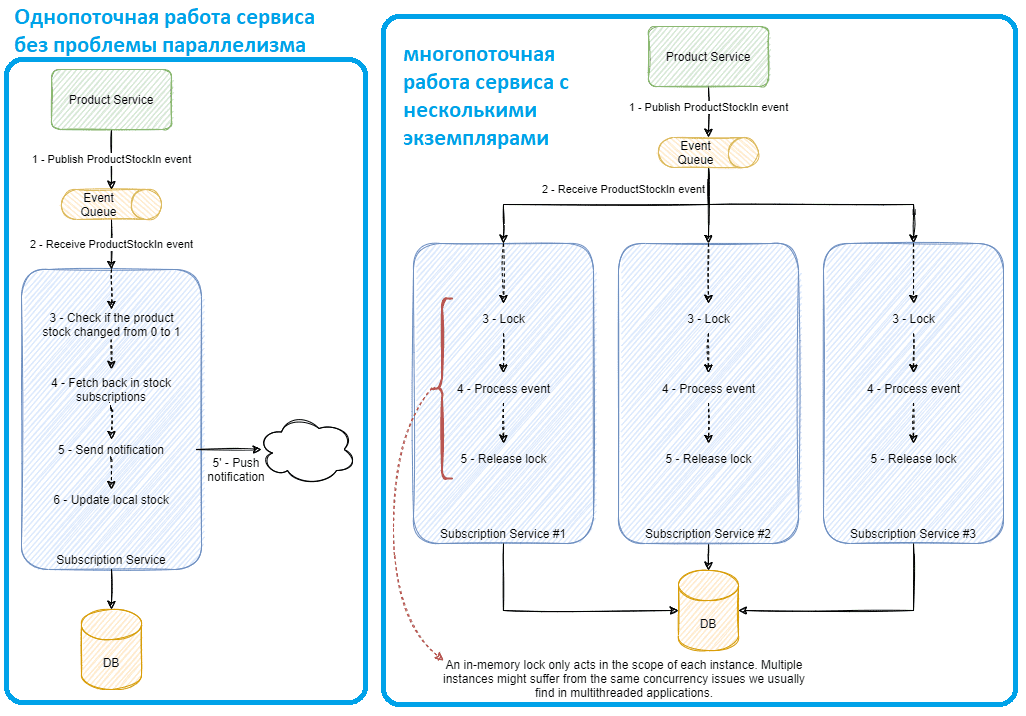
Поскольку блокировка в памяти совместно используется только экземпляром, выполняющим блокировку, другие экземпляры сервиса по-прежнему могут обрабатывать и обрабатывать другие события одновременно. Два события изменения товарного запаса для одного и того же продукта могут обрабатываться разными экземплярами, и, даже если оба заблокируют свое выполнение, оно будет ограничено только этими экземплярами, а потому состояние гонки может возникнуть в обоих экземплярах. Таким образом, с учетом горизонтального масштабирования для сервисов, управляемых событиями, традиционные подходы не подходят.
Альтернативой локальной блокировке является использование базы данных для предотвращения проблем параллелизма c помощью механизма транзакций. Но на практике гарантировать согласованность транзакций между внешними зависимостями не так-то просто. Кроме того, согласованность транзакций также ограничена технологиями, которые ее поддерживают, а многие NoSQL-СУБД не предоставляют таких ACID-гарантий, как реляционные базы данных.
Также решением может стать один из следующих способов борьбы с состоянием гонки:
- стратегия пессимистического параллелизма предотвращают гонку, блокируя параллельный доступ к желаемому ресурсу заранее. Эти стратегии следует применять в сценариях с высокой степенью параллелизма, когда очень вероятно, что два процесса будут обращаться к одному и тому же ресурсу в одно и то же время. Этот способ снижает производительность и ограничивает общий параллелизм решения.
- стратегия оптимистичного параллелизма предполагает отсутствие состояния гонки. Когда возникает проблема с параллелизмом, выполняется повторная попытка выполнения неудачной операции или выдача ошибки. Этот способ лучше всего подходит для сред с низкой вероятностью состояния гонки и имеет отличную производительность, поскольку здесь нет блокировок, а просто происходит реакция на сбой. Но если вероятность проблемы с параллелизмом высока, повторная попытка выполнения операции обычно обходится гораздо дороже, чем ограничение доступа к ресурсу.
Как эти стратегии реализуются с использованием Apache Kafka, рассмотрим далее.
Упорядочивание событий в Apache Kafka
Поскольку Apache Kafka является распределенной платформой потоковой передачи событий, она изначально ориентирована на распределенные многопоточные системы и включает возможности предупредить состояние гонки благодаря самой архитектуре и принципам ее работы. Опубликованные события отправляются в разделенные на разделы топики Kafka, похожие на очереди сообщений, но сохраняющие каждое событие даже после потребления, как распределенный лог.
Когда приложение-продюсер публикует событие в заданном топике, оно сохраняется в определенном разделе. Чтобы назначить события разделам, Kafka хэширует ключ, в результате чего получается раздел. Если ключ не предоставляется, он циклически проходит через каждый раздел. Но именно ключ гарантирует, что все события с одним и тем же ключом будут перенаправлены в один и тот же раздел. Приложения-потребители обрабатывают события из топиков. Поскольку сервисы, управляемые событиями, обычно масштабируются по горизонтали, для увеличения пропускную способность службы могут быть добавлены ее новые экземпляры. Например, рассматриваемая служба подписки может иметь несколько экземпляров, одновременно использующих один и тот же топик Kafka, что потенциально может привести к проблемам параллелизма: один раздел используется одним и только одним экземпляра сервиса, а Kafka гарантирует порядок в каждом разделе, но не в топике.
Поэтому при публикации сообщение в топике, нет никакой гарантии, что потребитель получит эти сообщения, если произойдет сетевой сбой или перебалансировка. Но Kafka гарантирует порядок в одном разделе, а каждый раздел потребляется одним и только одним экземпляром в группе потребителей. Разделы назначаются одному узлу кластера, поэтому один и тот же топик может физически храниться на нескольких машинах вместе со своими репликами для отказоустойчивости. Это обеспечивает высокую масштабируемость и доступность. Однако, глобальный порядок на нескольких машинах не гарантирован, т.к. Kafka обеспечивает упорядочение в отдельном разделе топика, но не всех разделов.
Тем не менее, с Apache Kafka в сервисах, управляемых событиями, можно использовать возможности маршрутизации событий в определенные разделы. Поскольку каждый раздел используется только одним экземпляром, можно направлять каждый набор событий в определенные экземпляры в зависимости от ключа маршрутизации, спроектировав систему так, чтобы избежать параллелизма в рамках одного и того же объекта.
Для нашего примера можно использовать идентификатор продукта в качестве ключа маршрутизации: все события одного и того же товара будут направляться в один и тот же раздел, который используется только и только экземпляром сервиса. Поэтому все события для этого товара будут обрабатываться только одним экземпляром сервиса, исключая состояние гонки.
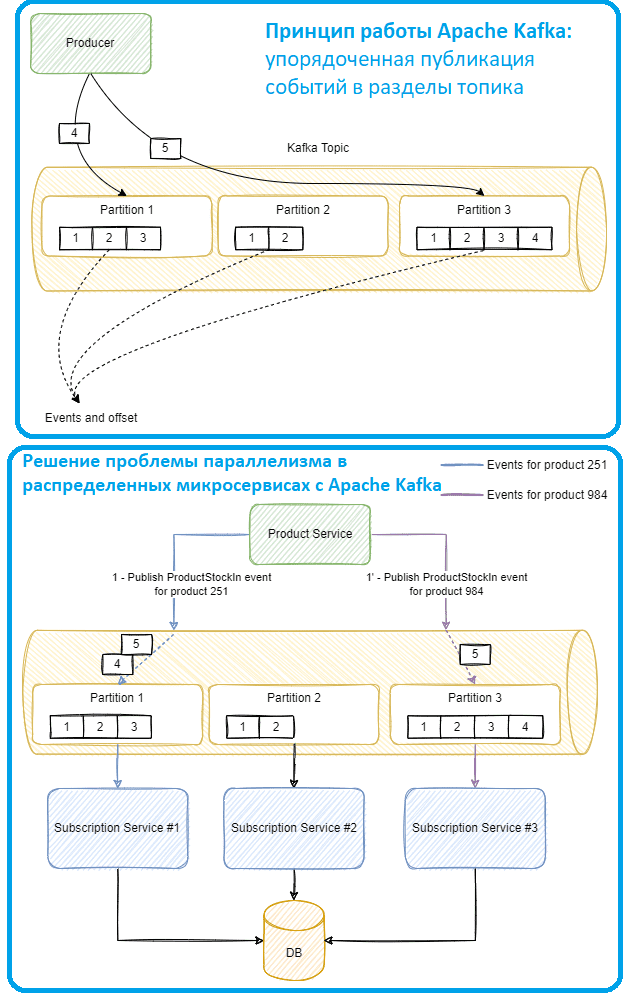
К примеру, все запасы в событиях для продукта 251 гарантированно будут потребляться экземпляром сервиса подписки №1 и только им. Поскольку ни один другой экземпляр не может обрабатывать события для того же продукта, можно применить традиционные способы обработки параллелизма, т. е. стратегии борьбы с состоянием гонки внутри процесса, такие как блокировки, превратив проблему распределенного параллелизма в проблему внутрипроцессного параллелизма, что намного проще решить. Внутри службы подписки можно использовать ту же стратегию, перенаправляя события в определенные потоки. Эта сквозная маршрутизация событий может устранить состояние гонки особенно масштабируемым и устойчивым способом. А поскольку Kafka гарантирует упорядоченность внутри одного раздела, события также упорядочены. Это позволяет избежать сложностей обработки нестандартных событий.
Таким образом, проще решить проблему параллелизма при проектировании распределенной системы, продумав ее архитектуру так, чтобы состояние гонки не возникало. Это более эффективно и производительно, поскольку не требует блокировки ресурсов, как при пессимистичных подходах, или повторных операций, как при оптимистичных стратегиях.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

