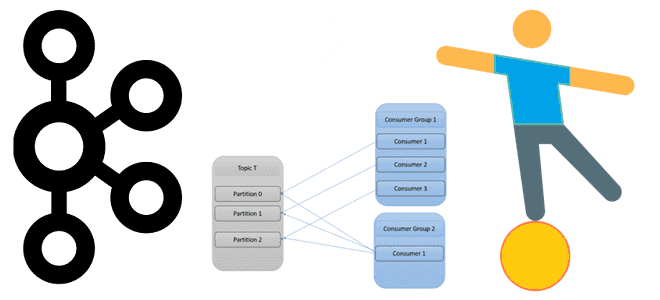
Для параллельной обработки сообщений из своих топиков Kafka использует механизм группы приложений-потребителей, о чем мы писали здесь. Читайте далее, что происходит при изменении состава группы потребителей, чем опасна частая перебалансировка и как ее избежать. Что такое перебалансировка потребителей и почему она случается? Выполняя роль интеграционного звена между приложениями-продюсерами и приложениями-потребителями...
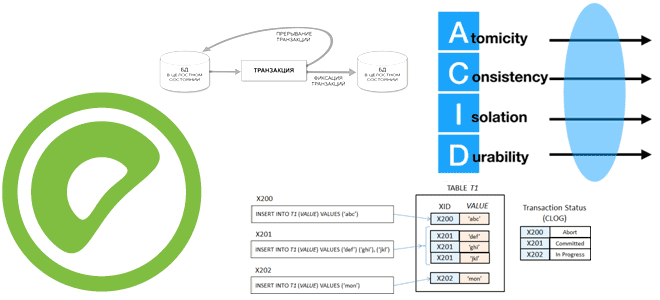
Недавно мы писали про трудности реализации ACID-требований к транзакциям в распределенных базах данных и способах их решения. Сегодня рассмотрим, как это работает в Greenplum с Arenadata DB: уровни изоляции, идентификаторы транзакций, моментальные снимки и MVCC-модель управления параллелизмом. Как GP и Arenadata DB реализуют распределенные транзакции Будучи основанной на PostgreSQL, Greenplum...
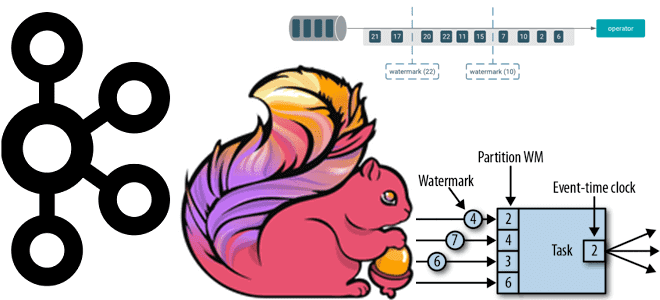
Почему вместо автоматической фиксации топиков Kafka приложению-потребителю Apache Flink лучше использовать контрольные точки, как создаются и обрабатываются водяные знаки и при чем тут оконные операторы потоковой обработки данных. Смещение в топиках Kafka для потоковых приложений Apache Flink Благодаря мощному API пакетной и потоковой обработки, Apache Flink часто используется для разработки...
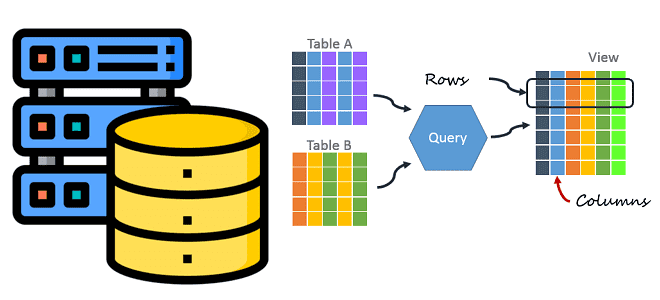
Как данные хранятся на диске при разной ориентации хранилища в СУБД: чем отличаются колоночные базы от строковых с точки зрения практического использования в дата-инженерии. Сравнительная таблица с примерами и выводами. Как данные хранятся на диске и при чем здесь ориентация СУБД Способы хранения данных в СУБД можно разделить на 2...

Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее. Что такое RAPIDS Accelerator для Apache Spark и как он работает Системы Machine Learning, особенно проекты глубокого обучения, уже...
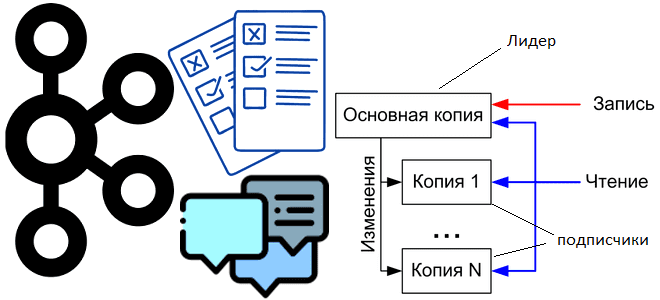
Сегодня рассмотрим, как внутренние механизмы Apache Kafka обеспечивают отказоустойчивость это потоковой платформы передачи событий, а также разберем, почему до сих пор приходится выбирать между доступностью и надежностью. Выборы нового лидера при сбое прежнего и ожидание подтверждений об успешной репликации. Поиск компромисса между надежностью и доступностью в Apache Kafka Для обеспечения...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...
Как протестировать работу приложения Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Разбираем особенности ручного и автоматизированного тестирования Flink SQL на уровне отдельных функций, модулей и их интеграционного взаимодействия. Модульное и интеграционное тестирование приложений Apache Flink SQL Тестирование является неотъемлемой частью любого процесса разработки ПО,...

Сегодня в рамках обучения администраторов SQL-on-Hadoop рассмотрим, как защитить данные в кластере Apache HBase от несанкционированного доступа. Аутентификация и авторизация пользователей, операторы управления доступом к таблицам, метки видимости и шифрование данных. Механизмы защиты данных в Apache HBase Как и любое хранилище, колоночно-ориентированная мультиверсионная NoSQL-СУБД типа key-value Apache HBase, которая работает...
Какие подходы позволяют увеличить емкость СУБД, чтобы повысить объем хранящихся в ней данных и ускорить вычисления. Разбираем тонкости масштабирования распределенной базы данных с массово-параллельной обработкой Greenplum: действия администратора по добавлению новых узлов в кластер. Как увеличить емкость базы данных: 4 подхода к масштабированию Чтобы увеличить емкость СУБД, т.е. объем хранимых...