
Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее.
Что такое RAPIDS Accelerator для Apache Spark и как он работает
Системы Machine Learning, особенно проекты глубокого обучения, уже довольно давно и успешно используют графические процессоры (GPU) для ускорения вычислений. Однако, в аналитике больших данных эта практика пока не очень распространена. Впрочем, недавно мы рассматривали, как векторизованный вычислительный движок Gluten, поддерживающий аппаратные ускорители, снижает время выполнения SQL-запросов в Spark-приложениях. Проект развивает эту идею, представляя собой ускоритель для Apache Spark, который использует графические процессоры, чтобы ускорить вычисления с помощью библиотеки RAPIDS cuDF. Библиотека RAPIDS Accelerator имеет встроенное ускоренное перемешивание на основе UCX, которое можно настроить для использования связи между графическими процессорами и удаленного прямого доступа к памяти (RDMA, Remote Direct Memory Access).
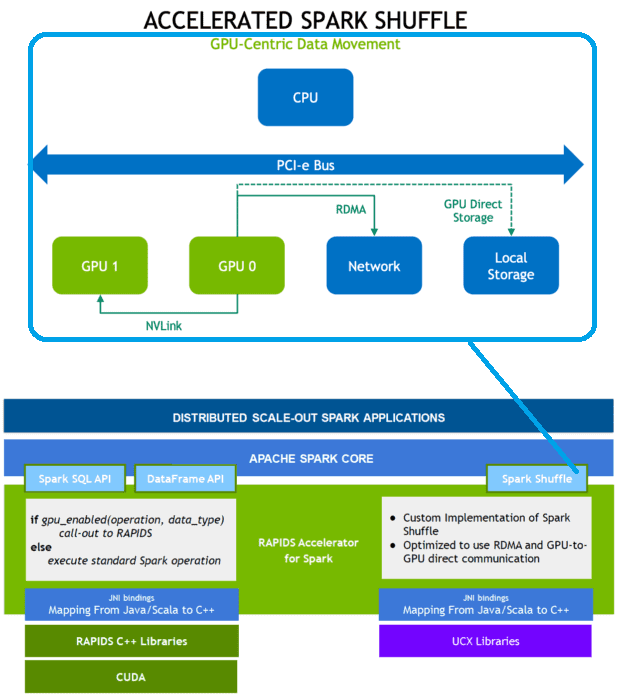
Напомним, удалённый прямой доступ к памяти представляет собой аппаратное решение для прямого доступа к оперативной памяти другого компьютера при помощи высокоскоростной сети, позволяя получить доступ к данным в удалённой системе без использования операционных систем обоих компьютеров.
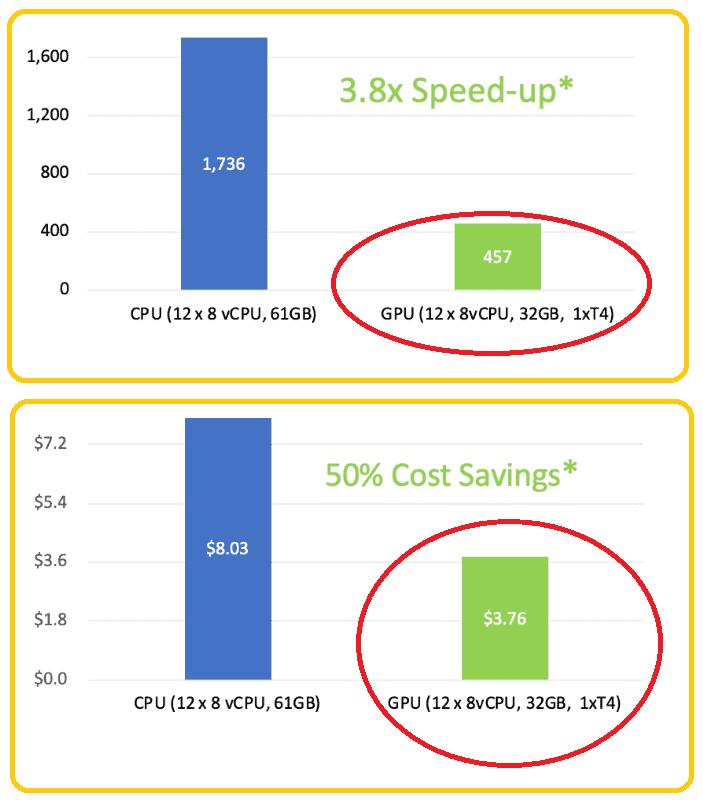
Фреймворк обработки данных RAPIDS представляет собой набор библиотек для запуска сквозных конвейеров обработки данных полностью на графическом процессоре. Возможности библиоткеи RAPIDS похожи на Python, но внутри используются оптимизированные примитивы NVIDIA® CUDA® и высокоскоростная память GPU. Rapids Accelerator для Apache Spark использует преимущества производительности графического процессора при одновременном снижении затрат на инфраструктуру. Бенчмаркинговое сравнение ETL-конвейера для набора данных около 200 ГБ показало значительное сокращение времени и стоимости вычислений на GPU по сравнению с обычным ЦП.
Примечательно, что использовать возможности RAPIDS в Spark-приложениях можно почти без изменения их исходного кода. Достаточно лишь запустить Spark с помощью JAR-файла плагина RAPIDS Accelerator для Apache Spark и включите параметр конфигурации spark.conf.set(‘spark.rapids.sql.enabled‘,’true‘)
При запуске Spark-приложения на платформе контейнерной виртуализации Kubernetes необходимо создать его Docker-образ, используя базовые образы с поддержкой CUDA, например, nvidia/cuda. JAR-файл плагина RAPIDS Accelerator для Apache Spark следует поместить в каталог Spark/jars и скопировать скрипт обнаружения графического процессора в каталог spark/bin. При этом рекомендуется устанавливать часовой пояс в формате UTC в образе Spark, чтобы ускорить производительность заданий, поскольку, начиная с Spark RAPIDS версии 22.10, для данные временных меток (timestamp) могут работать на графических процессорах только с зоной UTC.
Из-за того, что технология еще достаточно новая, пока есть некоторые несовместимости Spark RAPIDS с классическим фреймворком, о которых необходимо знать дата-инженеру и разработчику распределенных приложений. Какие именно, мы рассмотрим далее.
Проблемы совместимости: SQL и не только
Хотя в большинстве случае SQL-плагин позволяет получить результаты, полностью идентичные Apache Spark, но есть некоторые операторы, где отличается порядок вывода. Обычно это агрегаты и соединения, которые могут использовать хэш для распределения рабочей нагрузки между нижестоящими задачами. В этих случаях плагин RAPIDS Accelerator для Apache Spark не гарантирует идентичный порядок вывода, что и Spark. Также не может быть гарантирована стабильность сортировки при распределенных рабочих нагрузках из-за отсутствия гарантий порядка, в котором восходящие данные поступают в задачу. Стабильность сортировки гарантируется только в одной ситуации: чтение и сортировка данных из файла с использованием одной задачи или одного раздела.
Ускоритель RAPIDS по умолчанию выполняет нестабильную сортировку вне ядра, допуская сбор части данных, если они больше, чем может поместиться в памяти GPU, но не гарантирует упорядочение строк при неоднозначном порядке ключей. Чтобы обеспечить стабильность сортировки, следует установить для конфигурации spark.rapids.sql.stableSort.enabled значение true. В этом случае RAPIDS попытается отсортировать все данные для этой задачи или раздела одновременно на графическом процессоре.
Для большинства основных операций с плавающей запятой, таких как сложение, вычитание, умножение и деление, плагин RAPIDS дает тот же результат, что и Spark. Для таких функций, как как sin, cos и пр., вывод может быть другим, но в пределах погрешности округления, присущей вычислениям с плавающей запятой. Порядок операций для вычисления значения может различаться между базовой реализацией JVM, используемой ЦП, и реализацией стандартной библиотеки C++, используемой графическим процессором.
В случае округления результаты могут отличаться больше, особенно, когда двоичное представление с плавающей запятой не может точно передать десятичное значение. Например, 1,025 не может быть точно представлено и оказывается ближе к 1,02499. Реализация функции round() в Spark сначала преобразует его в десятичное значение со сложной логикой, чтобы получить 1,025, а затем выполняет округление. Это приводит к тому, что round(1.025, 2) в Spark получает значение 1,03, а под ускорителем RAPIDS — 1,02. Язык программирования Python будет давать 1.02, а Java не имеет встроенной возможности делать такое округление, но можно выполнить простую операцию Math.round(1.025 * 100.0)/100.0, чтобы также получить 1.02.
Для тригонометрических функций реализация Spark опирается на встроенные функции Java JDK Math.toDegrees. Это angrad*180.0/PI в Java 8, и angrad*(180d/PI) в Java 9+. Таким образом, их результаты будут отличаться в зависимости от версии среды выполнения JDK. Ускоритель RAPIDS ведет себя аналогично Java 9+. Поэтому с JDK 8 или ниже переполнение тригонометрических значений на GPU не будет возникать даже при очень больших числах, в отличие от CPU.
Для агрегатов базовая реализация выполняет агрегаты параллельно, и из-за условий гонки внутри самих вычислений результат может быть разным при каждом выполнении запроса. Это связано с тем, как плагин ускоряет вычисления. Если запрос соединяется со значением с плавающей запятой, что нецелесообразно, и значение является результатом агрегации с плавающей запятой, тогда соединение может не работать корректно с плагином RAPIDS, но работало бы с обычным Spark. Начиная с 22.06 это поведение включено по умолчанию, но его можно отключить с помощью конфигурации spark.rapids.sql.variableFloatAgg.enabled.
Spark делегирует операции Unicode базовой JVM. Каждая версия Java соответствует определенной версии стандарта Unicode. Плагин SQL не использует JVM для поддержки Unicode и совместим с Unicode версии 12.1. Из-за этого могут быть случаи, когда Spark будет давать другой результат по сравнению с плагином RAPIDS.
Для разных форматов данных (CSV, JSON, ORC, Parquet) также есть определенные ограничения. В частности, парсер CSV с ускорением на графическом процессоре не поддерживает часовые пояса, игнорируя любую конечную информацию о часовом поясе. По умолчанию он отключен, и его можно включить, установив для конфигурации spark.rapids.sql.csvTimestamps.enabled значение true.
Кроме того, есть определенные проблемы совместимости с ANSI SQL. В Apache Spark операции условий, такие как if, coalesce и case/when, выполняют вычисление параметров отложено и построчно. На графическом процессоре более эффективно вычислять параметры независимо от условия, а затем выбирать, какой результат следует вернуть, исходя из условия. Это отлично работает, когда нет побочных эффектов, вызванных оценкой параметра, что характерно для большинства SQL-выражений в Spark. Но в режиме ANSI SQL многие выражения могут генерировать исключения, например, для выражения Add, если происходит переполнение. Это также верно для UDF-функций, которые определяются пользователем и могут иметь побочные эффекты, такие как создание исключений. Плагин RAPIDS предполагает отсутствие таких побочных эффектов, что может привести к ситуациям, особенно в режиме ANSI, когда ускоритель RAPIDS на GPU всегда будет выдавать исключение, а Spark-приложение на ЦП — нет.
Впрочем, несмотря на некоторые проблемы совместимости, Rapids Accelerator для Apache Spark имеет отличный практический потенциал для повышения производительности распределенных приложений аналитики больших данных и машинного обучения, позволяя использовать мощь графических процессоров для вычислительных нагрузок.
Узнайте больше про Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

