 989
989 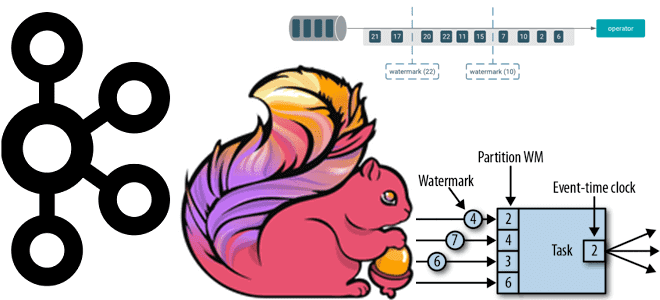
Содержание
Почему вместо автоматической фиксации топиков Kafka приложению-потребителю Apache Flink лучше использовать контрольные точки, как создаются и обрабатываются водяные знаки и при чем тут оконные операторы потоковой обработки данных.
Смещение в топиках Kafka для потоковых приложений Apache Flink
Благодаря мощному API пакетной и потоковой обработки, Apache Flink часто используется для разработки приложений реального времени, считывающих данные из топиков Kafka. Исходный код Kafka предоставляет класс построителя для создания экземпляра KafkaSource. Подробнее про источники данных для Apache Flink мы писали здесь. Следующий фрагмент Python-кода показывает, как создать KafkaSource для использования сообщений из самого раннего смещения топика input-topic с группой потребителей my-group и десериализовать только значение сообщения в виде строки.
source = KafkaSource.builder() \
.set_bootstrap_servers(brokers) \
.set_topics("input-topic") \
.set_group_id("my-group") \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
env.from_source(source, WatermarkStrategy.no_watermarks(), "Kafka Source")
Для разбора сообщений Kafka требуется десериализатор, который может быть настроен с помощью метода setDeserializer(KafkaRecordDeserializationSchema), где KafkaRecordDeserializationSchema определяет, как десериализовать запись потребителя Kafka. Если требуется только значение записи потребителя Kafka, можно использовать метод setValueOnlyDeserializer(DeserializationSchema) в построителе, где параметр DeserializationSchema определяет, как десериализовать двоичные файлы значения сообщения Kafka. Также можно использовать десериализатор Kafka для десериализации значения сообщения Kafka.
Источник Kafka может использовать сообщения, начинающиеся с разных смещений, если указан OffsetsInitializer. Можно реализовать собственный инициализатор смещения, но это не поддерживается в PyFlink. Если инициализатор смещений не указан, по умолчанию будет использоваться OffsetsInitializer.earliest().
По умолчанию KafkaSource настроен на потоковую работу, поэтому никогда не останавливается до тех пор, пока задание Flink не завершится сбоем или не будет отменено. Используя метод setBounded(OffsetsInitializer), можно указать смещение остановки и запуска источника в пакетном режиме. Когда все разделы достигнут своих остановочных смещений, источник завершит работу.
Также можно настроить KafkaSource на работу в потоковом режиме с остановкой на смещении, заданном с помощью метода setUnbounded(OffsetsInitializer). Источник завершит работу, когда все разделы достигнут указанного сдвига остановки.
Как правило, при использовании Kafka в качестве источника данных, Flink полагается на свою собственную политику при фиксации смещения топика, фиксируя его после выполнения контрольной точки. Впрочем, разработчик может также программно включить фиксацию смещения в самом топике Kafka, установив конфигурацию ENABLE_AUTO_COMMIT_CONFIG в значение true.
Обычно используется только один из этих способов, поскольку при одновременном включении контрольных точек Flink и автоматической фиксации Kafka может возникнуть проблема рассинхронизации интервала между ними. В этом случае сбой задания Flink чреват потерей данных. Поэтому рекомендуется отключать автоматическую фиксацию Kafka и использовать контрольные точки Flink для фиксации смещения топика. Если же необходима и автоматическая фиксация, следует синхронизировать ее интервал с периодом создания контрольной точки Flink. Другие сложности реализации строго-однократной доставки сообщений в потоковой обработке данных с Apache Flink и Kafka мы рассматривали в этой статье.
Еще раз про водяные знаки в Apache Flink
Следует отметить, что обеспечение целостности данных в потоках данных в реальном времени может быть сложной задачей. Для отслеживания хода событий во времени в Apache Flink используется механизм водяных знаков.
Входящий поток данных делится на подпотоки, каждый из которых может обрабатываться отдельно. Данные разделяются и назначаются окнам на основе ключа, указанного разработчиком приложения, в дополнение к типу оператора окна, который может основываться на времени, сеансе, подсчете и пр.
Время обработки представляет собой локальное время механизма потоковой обработки, когда оператор начал обрабатывать входящее событие, а время события — это метка времени, когда оно было сгенерировано в источнике данных. Проблема со временем обработки заключается в том, что оно не учитывает порядок событий, поскольку они могут поступать не по порядку из-за проблем с сетью, ETL-конвейером, источником данных и т.д. Но время события представляет собой точное время фактической генерации событий, поэтому может использоваться в качестве источника истины для определения порядка обработки.
В Apache Flink оператор окна, основанный на времени, использует время события. Поэтому для него определяется начало и конец окна, и по прибытии каждого события механизм определяет, принадлежит ли событие этому окну или нет. Если временная метка события находится между началом и концом окна, событие поступило с опозданием, нужен способ сообщить оператору об этом. Таким способом является водяной знак (watermark) – временная метка, значение которой сообщает оператору в определенный момент времени, что в будущем не должно поступать событий с временной меткой, меньшей, чем эта метка. И поэтому любое открытое окно с временной меткой меньше, чем значение водяного знака, может быть запущено для передачи содержимого оператору обработки.
Потоковая обработка данных с помощью Apache Flink
Код курса
FLINK
Ближайшая дата курса
15 июня, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Чтобы использовать водяные знаки в Apache Flink, в конвейере нужно указать фреймворку, как создавать водяные знаки и как назначать их входящему потоку данных. Для этого используется метод assignTimestampsAndWatermarks(), при вызове которого Flink генерирует водяные знаки для всего потока на основе стратегии WatermarkStrategy. Впрочем, существует много других доступных политик водяных знаков. Также разработчик Flink-приложения может реализовать свою собственную политику, используя класс WatermarkGenerator.
.assignTimestampsAndWatermarks( (WatermarkStrategy.<Object>forBoundedOutOfOrderness(Duration.ofMillis(1000)) .withTimestampAssigner((event, ts) -> event.getEventTimeMillis())) )
Метод forBoundedOutOfOrderness() — это тип стратегии водяных знаков в Flink, который допускает некоторую задержку для ожидания более поздних событий в зависимости от продолжительности. В примере вышеприведенного участка кода этот период равен 1000 мс.
Метод withTimestampAssigned() используется для извлечения метки времени из события, которая используется для создания водяного знака. В нашем пример источник события предоставляет метод с именем getEventTimeMillis(), который возвращает метку времени события в миллисекундах. Способ извлечение метки времени зависит от конвейера обработки данных.
Созданный водяной знак сериализуется для отправки по сети от TimestampsAndWatermarksOperator() другим нижестоящим операторам. Сериализация во Flink выполняется с помощью класса StreamElementSerializer.java, который содержит два основных важных метода: serialize(value, output) и deserialize(source). Примечательно, что параметр value в методе serialize(value, output) может быть событием с меткой времени, событием без метки времени, водяным знаком, статусом водяного знака и т. д. Для водяного знака метод serialize(value, output) сериализует его, извлекая временную метку из параметра value в качестве водяного знака. Затем метод deserialize(source) десериализует водяной знак и создает новый объект водяного знака с десериализованной временной меткой.
Узнайте больше про применение Apache Flink и Kafka для потоковой обработки событий в распределенных приложениях аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Потоковая обработка данных с помощью Apache Flink
- Apache Kafka для инженеров данных
- Администрирование Arenadata Streaming Kafka
[elementor-template id=»13619″]
Источники

