
Сегодня мы коснемся процесса управления требованиями и рассмотрим, как техника SQUARE (Security Quality Requirements Engineering) помогает снизить риски в проектах по цифровизации бизнеса и разработке Big Data систем. Читайте в нашем материале, что такое информационная безопасность, BABOK и Gherkin, а также когда и как формулировать требования к cybersecurity на ранних...

В этой статье мы снова поговорим про GDPR и наиболее крупные утечки данных, почему случаются такие инциденты cybersecurity. Также рассмотрим аналитические методы и техники, которые помогут обнаружить ключевые причины таких проблем и снизить риски их возникновения. Читайте в нашем материале, что такое диаграмма Исикавы и зачем нужен подход SQUARE при...
Рассказав о том, как машинное обучение работает в разных задачах cybersecurity, сегодня мы собрали для вас 5 примеров реального использования Machine Learning в информационной безопасности. Также в этой статье мы рассмотрим, способны ли эти методы искусственного интеллекта заменить существующие инструменты защиты данных и почему. Где и как машинное обучение используется...

Сегодня мы расскажем, как машинное обучение (Machine Learning, ML) используется в информационной безопасности для защиты данных от утечек, несанкционированного доступа, неправомерного использования пользовательских привилегий, вирусных атак и прочих угроз cybersecurity. Читайте в нашей статье, как нейросети и другие ML-модели выявляют мошеннические операции и другие аномалии в Big Data системах и...

Продолжая разговор о том, что такое цифровой двойник и где эта технология Industry 4.0 используется на практике, сегодня мы рассмотрим несколько реальных примеров такой цифровизации в отечественной и зарубежной промышленности. Читайте в нашей статье про практическую синергию технологий Big Data, ML, PLM и IIoT в нефтегазовой, теплоэнергетической и машиностроительной отраслях....

В этой статье мы разберем, что такое цифровой двойник – один из главных трендов развития 4-ой промышленной революции (Industry 4.0) на ближайшие 5 лет. Читайте в сегодняшнем материале, зачем нужен виртуальный макет завода, из чего состоит информационная модель изделия и где используются цифровые двойники. Также рассмотрим, как CALS- и PLM-технологии...

Сегодня мы расскажем, почему и зачем сейчас почти все сайты собирают cookies, что такое GDPR, как банки собираются оценивать кредитоспособность потенциального заемщика по истории его запросов в браузере и насколько это легально. Читайте в нашей статье про персональные данные, синергетический эффект технологий Big Data и финансовый скоринг на основе пользовательского...

На пороге 3-го десятилетия 21 века пришло время подвести итог прошедшим годам и cделать прогнозы на будущее. В этой статье мы поговорим о ключевых событиях минувших лет, помечтаем о том, что ждет Big Data и чего нам принесет эта ИТ-область. Также поделимся с вами своими планами на 2020 год: расскажем...
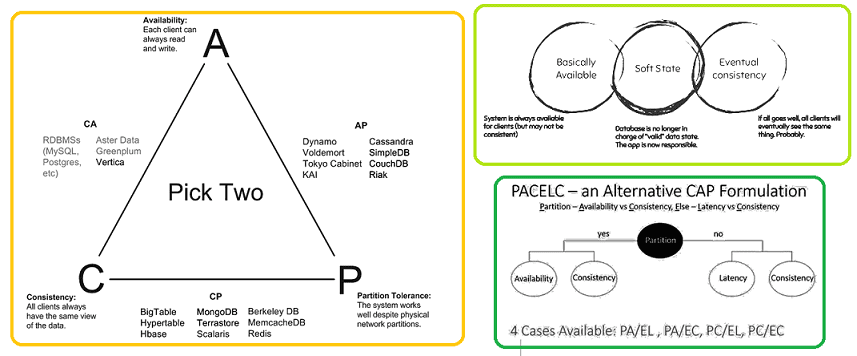
В этой статье мы расскажем про краеугольный камень распределенных Big Data систем – CAP-теорему, в которой одновременно возможно реализовать только 2 свойства из 3-х, по аналогии с треугольником ограничений в проектном менеджменте «Быстро-Качественно-Дешево». Также рассмотрим, за что критикуют модель CAP и почему современные NoSQL-СУБД стоит рассматривать с позиций BASE и...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...