
Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

В этой статье мы рассмотрим наиболее значимые факторы по выбору образовательных курсов по Apache Kafka и другим технологиям больших данных (Big Data). А также расскажем, как эти условия реализуются в нашем учебном центре, чтобы сделать повышение квалификации ИТ-специалистов и руководителей максимально эффективным. Что важно при выборе курсов по Кафка Проанализировав...
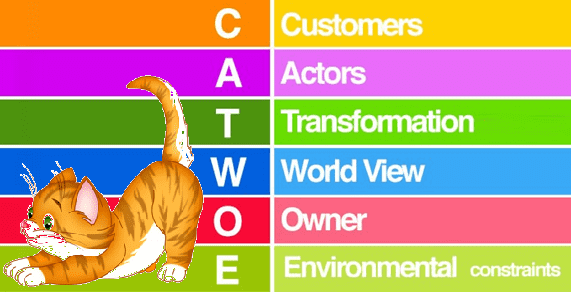
Сегодня мы поговорим о том, что такое CATWOE и зачем эта техника бизнес-анализа нужна руководителю. Также рассмотрим практическое применение этого метода на примере реального бизнес-кейса по цифровизации крупного предприятия и внедрения Big Data системы промышленного интернета вещей (Industrial Internet of Things, IIoT) в виде RFID-технологий. Как сэкономить время на бизнес-анализ...

Вчера мы писали, что cybersecurity биометрии пока не слишком надежна: обмануть можно как дактилоскопический сканер на смартфоне, так и крупную систему больших данных (Big Data). Сегодня поговорим о мерах обеспечения информационной безопасности биометрических данных: многофакторной аутентификации, защите цифровых шаблонов и кратной верификации. А также расскажем, когда государственная цифровизация в России...

Сравнив между собой наиболее популярные методы биометрии, сегодня мы подробнее рассмотрим, насколько они устойчивы к фальсификациям. Читайте в этой статье, как хакеры обманывают сканер отпечатков пальцев, путают Big Data системы уличной видеоаналитики и выдают себя за другое лицо с помощью модной технологии машинного обучения (Machine Learning) под названием Deep Fake....
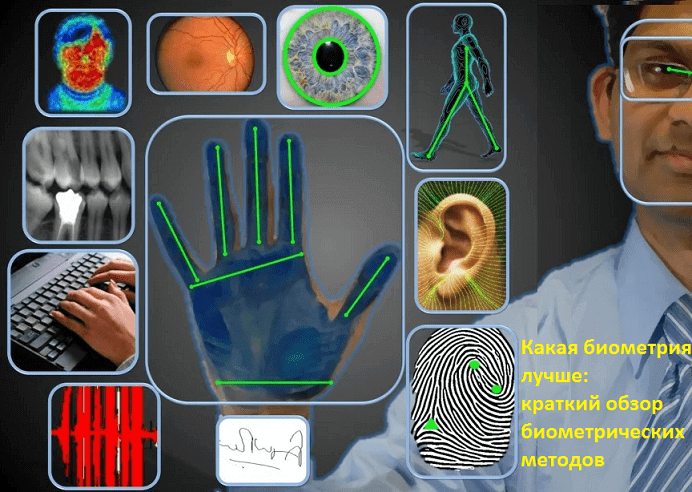
Продолжая рассматривать уязвимости биометрических систем, сегодня мы поговорим про отличия разных методов биометрии. Проанализируем быстроту их работы и устойчивость к фальсификации, а также используемые технологии Big Data и Machine Learning. Кроме того, сравним ставшие привычными способы идентификации личности по фотографии лица, снимкам глаз, отпечаткам пальцев и ладоней с более «экзотическими»...

В прошлой статье мы рассказывали о самых крупных утечках данных из биометрических Big Data систем в России и за рубежом. Сегодня рассмотрим характерные уязвимости биометрии: естественные ограничения методов идентификации личности с помощью машинного обучения (Machine Learning, ML) и целенаправленные атаки. 2 главные уязвимости биометрических Big Data систем на базе Machine...

В то время, как нацпрограма «Цифровая экономика» активно продвигает использование биометрических персональных данных россиян в качестве основных идентификаторов для государственных Big Data систем и коммерческих сервисов, информация продолжает утекать. В этой статье мы собрали наиболее крупные инциденты с утечками данных из биометрических систем в России и за рубежом. Как утекают...

Мы уже рассказывали, как машинное обучение применяется для прогнозирования будущих событий в финансовом секторе, нефтегазовой промышленности, логистике, HR-менеджменте, девелопменте, страховании, муниципальном управлении, маркетинге, ритейле и других отраслях экономики. Сегодня рассмотрим еще несколько практических примеров такого приложения Machine Learning и в этом контексте разберем одно из ключевых понятий Data Science по...

Продолжая тему Cybersecurity, сегодня мы поговорим про биометрические системы: что это такое, как они работают и чем нарушают требования GDPR и № 152-ФЗ. Также в этом материале мы собрали для вас примеры таких наиболее известных проектов на базе технологий Big Data и Machine Learning. Что такое биометрические персональные данные и...