1851
1851 
Как с помощью SQL-запросов анализировать огромные объемы данных из множества источников в реальном времени без их фактического копирования. Архитектура и принципы работы MPP-движка Trino.
Что такое Trino и зачем он нужен
Массово-параллельная архитектура (MPP, Massively Parallel Processing) с разделяемой памятью, когда система состоит из отдельных узлов, которые вместе выполняют одну задачу, довольно часто встречается в технологиях стека Big Data. Например, этот подход реализован в Greenplum и ClickHouse, что мы разбирали здесь. Такая архитектура особенно хороша для OLAP-сценариев, т.е. аналитики больших объёмов данных, которые постоянно растут. Такие системы быстро и экономично масштабируются горизонтально, поскольку представляют собой кластер независимых серверов, количество которых определяет скорость вычислений в MPP-системе. Кроме того, MPP-архитектура имеет высокую отказоустойчивость: система доступна, т.е. кластер отвечает на запросы даже при отказе некоторых узлов.
Еще одним популярным вариантом применением MPP-подхода стала аналитика данных в реальном времени без их фактического копирования из множества разнородных хранилищ. Объединять данные без их физической интеграции в комплексный отчет или дашборд позволяют специальные аналитические движки, такие как dbt или Trino. Подробно о том, чем похожи эти два инструмента, и чем отличаются, читайте в нашей новой статье. Они не зависят от конкретного хранилища данных и могут работать с разными источниками, обеспечивая высокую производительность благодаря параллельным вычислениям. Обычно такие механизмы поддерживают универсальные интерфейсы для работы с разными базами данных, такие как SQL для выполнения запросов, имеют наглядный GUI и REST API.
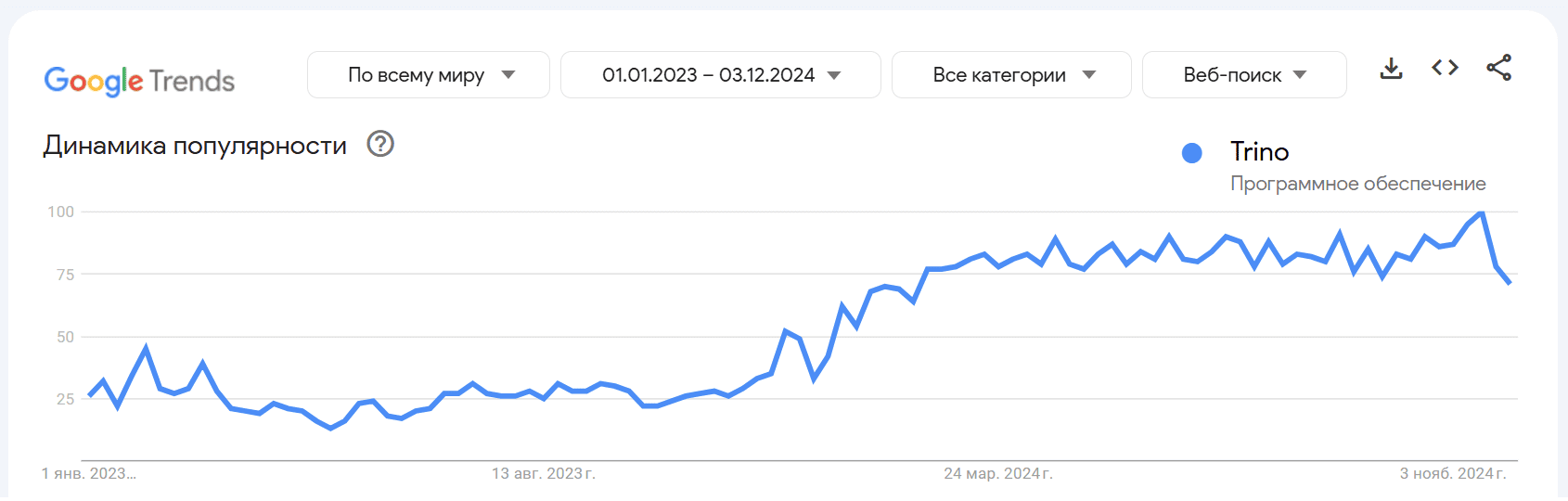
Поскольку подобные движки позволяют выполнять сложные аналитические сценарии, в т.ч. с транзакционными системами, в реальном времени и без изменения фактической архитектуры данных, они становятся все более востребованными. Об этом свидетельствует постоянно растущее количество поисковых запросов о Trino в Google Trends.
Trino представляет собой MPP-механизм SQL-запросов ко множеству источников данных, от реляционных баз до более сложных хранилищ типа Data Lake и lakeHouse. Этот движок был создан в 2012 году для Apache Hive и раньше назывался Presto, о чем мы уже упоминали здесь. Trino не хранит данные, а только взаимодействует с различными хранилищами, анализируя и обрабатывая запросы к ним, включая создание и оптимизацию планов выполнения. С помощью каких архитектурных приемов и технологий это реализуется, рассмотрим далее.
Принципы работы MPP-движка Trino
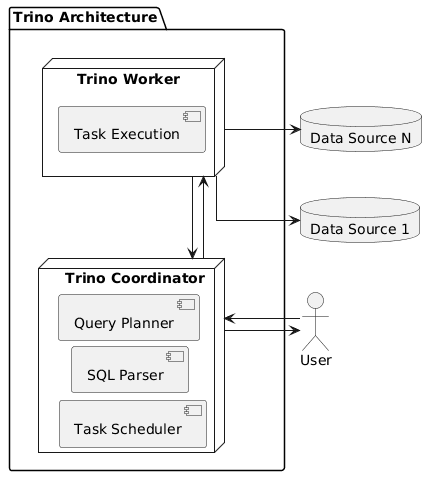
Будучи распределенным механизмом, Trino обрабатывает данные параллельно на нескольких серверах, которые бывают двух типов: координаторы и рабочие узлы. Кластер Trino состоит из одного координатора и может включать несколько рабочих узлов. Пользователи подключаются к координатору с помощью клиента, чтобы отправлять SQL-запросы и получать результаты. Как это реализуется, читайте в нашей новой статье. Клиенты Trino – это полнофункциональные клиентские приложения или клиентские драйверы и библиотеки, которые позволяют подключаться к любому приложению, поддерживающему этот драйвер, в т.ч. пользовательские приложения и скрипты. Поскольку Trino работает с ANSI SQL, любой клиент, поддерживающей другие языки запросов или использующий GUI для построения запроса, должен преобразовывать свои запросы в SQL.
Для подключения к каждому источнику данных Trino использует соответствующие коннекторы, о который мы рассказываем в новой статье. По сути, коннектор выполняет роль драйвера для базы данных, позволяя Trino взаимодействовать с ней через стандартный API. Коннектор реализует интерфейс поставщика услуг Trino (SPI, Service Provider Interface). Trino содержит множество встроенных коннекторов:
- для озер данных и Data LakeHouse, включая Delta Lake, Hive, Hudi и Iceberg;
- для реляционных баз данных MySQL, PostgreSQL, Oracle и SQL Server;
- для множества NoSQL-хранилищ, включая Cassandra, ClickHouse, OpenSearch, Pinot , Prometheus, SingleStore и Snowflake;
- служебные коннекторы JMX, System и TPC-H.
Подключившись к источнику данных с помощью коннектора, Trino выполняет операторы SQL, определенные в стандарте ANSI SQL из предложений, выражений и предикатов, и преобразует их в запросы, которые выполняются в распределенном кластере. Как уже было отмечено выше, кластер Trino состоит из координатора и рабочих узлов. Когда выполняется SQL-оператор, Trino создает запрос вместе с его планом выполнения, который затем распределяется по ряду рабочих узлов. Какие оптимизации при этом используются, читайте в нашей новой статье.
Архитектура Trino
Координатор взаимодействует с рабочими узлами, получая доступ к подключенным источникам данных. Этот доступ настраивается в каталогах, о которых мы поговорим в следующей статье. Обработка каждого запроса является stateful-операцей. Рабочая нагрузка координируется координатором и распределяется параллельно по всем рабочим процессам на рабочих узлах в кластере. Каждый узел запускает Trino в одном экземпляре JVM, а обработка дополнительно распараллеливается с помощью потоков. Поэтому рекомендуется запускать только один процесс Trino на одном компьютере. Запуск нескольких JVM на одном компьютере может быстро истощить доступную память, что приведет к снижению производительности или сбоям. Подробнее о причинах OOM-ошибки и способах ее устранения читайте в нашей новой статье.
Координатор Trino — это сервер, который отвечает за разбор операторов, планирование запросов и управление рабочими узлами Trino. Это центральная точка кластера Trino, а также узел, к которому подключаются клиенты для отправки SQL-операторов на выполнение. Для разработки и/или тестирования можно настроить один экземпляр Trino для выполнения обеих ролей, т.е. и как координатор, и как рабочий узел. Координатор отслеживает активность каждого рабочего узла и координирует выполнение запроса. Он создает логическую модель запроса, включающую ряд этапов, транслируя ее в ряд связанных задач, выполняемых на рабочих узлах. Координаторы общаются с рабочими узлами и с клиентами с помощью REST API. Аналогично происходит взаимодействие рабочих узлов друг с другом.
Рабочий узел Worker— это сервер Trino, который отвечает за выполнение задач и обработку данных. Рабочие узлы извлекают данные из источников с помощью коннекторов и обмениваются друг с другом промежуточными данными. Координатор отвечает за извлечение результатов из рабочих и возврат конечных результатов клиенту. Когда запускается рабочий процесс Trino, он объявляет о себе серверу обнаружения в координаторе, что делает его доступным для выполнения задач. Как они выполняются, рассмотрим в следующий раз.
Освойте использование Trino на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://trino.io/docs/current/overview/concepts/
- https://trino.io/ecosystem/client/
- https://habr.com/ru/companies/cedrusdata/articles/729004/