 1166
1166 
Зачем Trino статистика таблиц, как MPP-движок создает план выполнения SQL-запросов к разным источникам данных, применяя CBO-оптимизацию, а также полную или частичную передачу обработки предикатов в базовое хранилище.
Внутренние оптимизации Trino
В отличие от MapReduce с материализацией промежуточных результатов на диске, в массово-параллельной архитектуре Trino промежуточные результаты передаются между рабочими узлами без сохранения на диск, что ускоряет вычисления. Будучи MPP-движком для выполнения аналитических запросов к разным хранилищам без фактического копирования данных, Trino не просто транслирует SQL-операторы внешним источникам, о чем мы писали здесь, но и применяет оптимизации. Оптимизация запросов в Trino основана на статистике таблиц, которая предоставляется планировщику запросов с помощью коннекторов. Для таблицы отслеживается общее количество строк, а по каждому столбцу в таблице для создания оптимального плана выполнения запроса используются следующие данные:
- размер данных, которые необходимо прочитать;
- доля NULL-значений;
- количество отдельных значений;
- наименьшее и наибольшее значения в столбце.
Набор статистики, доступный для конкретного запроса, зависит от используемого коннектора и таблицы. Например, коннектор Hive в настоящее время не предоставляет статистику по размеру данных. Статистику таблиц можно отобразить через SQL-интерфейс Trino с помощью команды SHOW STATS.
При создании плана выполнения SQL-запроса Trino поддерживает несколько оптимизаций:
- на основе затрат (CBO, Cost-Based Optimization);
- адаптивные оптимизации, которые динамически корректируют планы выполнения запросов на основе статистики времени выполнения. Эти оптимизации доступны только при включенном отказоустойчивом выполнении, о котором мы поговорим в другой раз.
Оптимизации позволяют создать наиболее оптимальный план выполнения SQL-запроса — набор шагов для получения результата с минимальными затратами ресурсов, в т.ч. временных.
Основные компоненты плана выполнения запроса включают:
- операции доступа к данным, например, полное сканирование таблицы или использование индексов;
- варианты соединения таблиц, например, вложенные циклы, хэш-соединения и пр.;
- условия фильтрации и сортировки – какие будут применены и когда;
- группировка данных – как и когда она будет выполняться, а также каким образом будет происходить вычисление агрегатных функций.
При работе с соединениями таблиц через SQL-оператор JOIN, оптимизатор CBO рассматривает различные варианты упорядочивания и перечисления соединений. Это позволяет находить наиболее эффективную стратегию выполнения. Порядок, в котором выполняются соединения в запросе, существенно влияет на скорость его выполнения. Прежде всего, оптимизатор оценивает различные последовательности, в которых могут выполняться соединения. Порядок соединений может значительно влиять на объем промежуточных данных и общее время выполнения запроса.
С учетом распределенной архитектуры Trino особое влияние на производительность имеет размер обрабатываемых и передаваемых по сети данных. Если соединение, которое производит большой объем данных, выполняется на ранней стадии выполнения запроса, то последующие этапы должны обрабатывать большие объемы данных дольше, чем необходимо. Это увеличивает время и ресурсы для обработки запроса. Оптимизатор анализирует, сколько строк будет сгенерировано на каждом этапе соединения и насколько селективными являются условия фильтрации, чтобы сократить объем обрабатываемых данных. CBO старается избегать перекрестных соединений (картезианских произведений), которые могут привести к экспоненциальному увеличению объема данных.
Trino использует статистику таблиц, предоставляемую коннекторами, для оценки стоимости различных порядков соединений и автоматически выбирает порядок соединений с наименьшей вычисленной стоимостью. Стратегия перечисления соединений регулируется свойством сеанса join_reordering_strategy , а свойство конфигурации optimizer.join-reordering-strategy предоставляет значение по умолчанию (AUTOMATIC). Вместо AUTOMATIC, которое включает полное автоматическое перечисление соединений, можно задать параметру optimizer.join-reordering-strategy одно из следующих свойств:
- ELIMINATE_CROSS_JOINS – исключить ненужные перекрестные соединения;
- NONE – использовать чисто синтаксический порядок соединения
Если при выборе AUTOMATIC статистика недоступна или стоимость не может быть вычислена, применяется стратегия ELIMINATE_CROSS_JOINS.
После перечисления соединений, Trino выбирает стратегии распределения данных для выполнения соединений в распределенной среде. Для этого используются алгоритмы на основе хэша. Для каждого оператора соединения создается хэш-таблица из одного входа соединения. Затем выполняется итерация другого входа. Для каждой строки хэш-таблица запрашивается для поиска соответствующих строк. Есть два типа распределений соединений:
- партиционированное, когда каждый узел, участвующий в запросе, создает хэш-таблицу только из части данных;
- широковещательное, когда каждый узел, участвующий в запросе, строит хэш-таблицу из всех данных, которые реплицируются на каждый узел.
Разделенные соединения требуют перераспределения обеих таблиц с использованием хэша ключа соединения. Эти соединения могут быть намного медленнее широковещательных, но они позволяют работать с большим объемом данных, т.е. создавать гораздо более крупные соединения в целом. Широковещательные соединения быстрее, если сторона сборки – первая из соединяемых таблиц намного меньше другой. Однако, широковещательные соединения требуют, чтобы таблицы на стороне сборки после фильтрации помещались в память на каждом узле, тогда как распределенные соединения должны помещаться только в распределенную память по всем узлам.
Trino автоматически выбирает, использовать ли партиционированное или широковещательное соединение, а также сам назначает сторону сборки. Стратегия распределения соединений регулируется свойством сеанса join_distribution_type, а свойство конфигурации join-distribution-type предоставляет значение по умолчанию AUTOMATIC, когда тип распределения соединений определяется автоматически для каждого. Если для всех соединений надо использовать широковещательное распределение, параметру join-distribution-type задается значение BROADCAST. А когда для всех соединений используется партиционированное распределение – значение PARTITIONED. Ограничить максимальный размер реплицированной таблицы, по умолчанию равный 100 МБ, можно, задав свойство конфигурации join-max-broadcast-table-size или свойства сеанса join_max_broadcast_table_size. Это позволяет улучшить параллелизм кластера и избежать неоптимальных планов, когда CBO-оптимизатор неверно оценивает размер объединенных таблиц.
По умолчанию Trino включает адаптивное переупорядочивание партиционированных соединений, чтобы динамически переупорядочивать входы соединений на основе фактического размера сторон во время выполнения запроса. Это особенно полезно, когда статистика таблиц недоступна заранее. Отключить эту оптимизацию можно, установиы свойство конфигурации fault-tolerant-execution-adaptive-join-reordering-enabled в значение false или задав свойство сеанса fault_tolerant_execution_adaptive_join_reordering_enabled.
Если не используется CBO-оптимизация, Trino по умолчанию применяет синтаксическое упорядочивание соединений, выполняя хэш-соединения в памяти. При обработке JOIN-оператора Trino загружает самую правую таблицу соединения в память в качестве стороны сборки, затем передает следующую самую правую таблицу в качестве второй стороны соединения. При многоступенчатом соединении нескольких таблиц, результат первого соединения остается в памяти в качестве стороны сборки, к которой соединяется третья самая правая таблица и т.д. Когда порядок соединения усложняется, Trino может выполнять несколько соединений более низкого уровня одновременно, следуя той же логике и применяя ее же при итоговом объединении результатов. Поэтому синтаксическое упорядочивание соединений в SQL-запросах оптимально выполнять от самых больших таблиц к самым маленьким, сокращая потребление памяти.
Проталкивание предикатов
Trino может перенести обработку запросов частично или полностью в подключенный источник данных, реализуя подход predicate pushdown. Это означает, что определенный предикат, функция агрегации или другая операция передается в базовую систему хранения для обработки. Это повышает производительность, сокращает сетевой трафик между Trino и источником данных, а также снижает нагрузку на него. Поддержка такого подхода специфична для каждого коннектора и источника данных.
Predicate pushdown оптимизирует фильтрацию на основе строк, используя выведенный фильтр на основе условия в предложении WHERE. Коннектор передает обработку запроса в источник данных. Если это прошло успешно, план запроса, посмотреть который можно с помощью оператора EXPLAIN, не включает операцию ScanFilterProject для этого предложения.
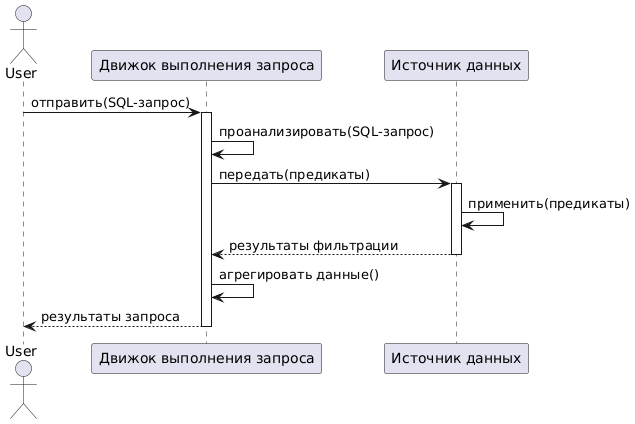
Проекция pushdown оптимизирует фильтрацию на основе столбцов. Она использует столбцы, указанные в предложении SELECT, и другие части запроса для ограничения доступа к этим столбцам. Коннектор передает обработку запроса в источник данных., который считывает и возвращает только необходимые для выполнения запроса столбцы. При успешном выполнении план выполнения запроса обращается только к соответствующим столбцам, сканируя таблицу. Это также можно посмотреть, добавив оператор EXPLAIN к запросу. Использование dereference pushdown ограничивает доступ только чтением указанных полей в пределах верхнего уровня или вложенных строк, сокращая объем данных, считываемых из источника.
Если агрегатная функция успешно передана в коннектор, план запроса не показывает этот оператор Aggregate, а содержит только операции, выполняемые Trino. Когда план выполнения запроса показывает операцию Aggregate, выполняемую Trino, то передать выполнение предиката в источник данных не получилось: Trino сам выполняет обработку агрегата. Так может случиться из-за добавления условия к запросу, использования другой агрегатной функции, которую нельзя передать в коннектор или отсутствия в нем pushdown для определенной функции. Сложные агрегации не поддерживают проталкивание в источник данных, например, ROLLUP, CUBE, GROUPING SETS, выражения внутри вызова функции агрегации, агрегации с упорядочением и с фильтром.
Некоторые коннекторы поддерживают делегирование операции соединения таблиц источнику данных, повышая производительность за счет сокращения объема вычислений на стороне Trino. При этом все предикаты, которые являются частью соединения, должны быть пригодны для проталкивания. Также соединяемые таблицы должны быть из одного каталога.
Передача большого списка предикатов в источник данных может снизить производительность. Поэтому Trino сжимает большие предикаты в более простой предикат. Чтобы повысить производительность, можно увеличить порог этого сжатия, изменив свойство конфигурации каталога domain-compaction-threshold или свойство сеанса каталога domain_compaction_threshold. По умолчанию эти значения равны 256.
Предложения LIMIT или FETCH FIRST сокращают количество возвращаемых записей для оператора. Это тоже может повысить производительность запроса и значительно сократить объем данных, передаваемых из источника в Trino.
Освойте использование Trino на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

