 1086
1086 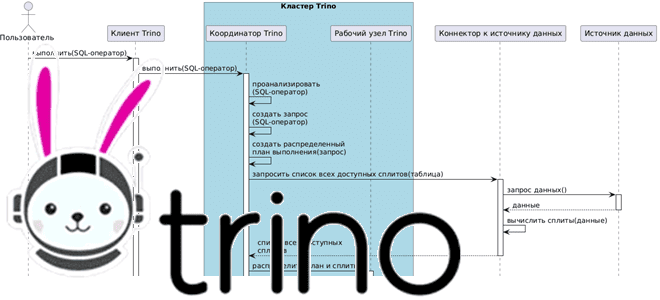
Как взаимодействуют рабочие узлы Trino между собой и с координатором кластера, а также с клиентскими приложениями и драйверами при выполнении SQL-запросов к данным из внешних источников без их фактического копирования.
Последовательность выполнения запросов в кластере Trino
Продолжая разбираться с Trino, сегодня рассмотрим, как этот аналитический движок с массово-параллельной архитектурой (MPP, Massively Parallel Processing) обрабатывает данные из внешних источников без их фактического копирования. Подключившись с помощью коннекторов к реляционным базам и/или NoSQL-хранилищам, включая озера данных и Data LakeHouse, а также потоковым платформам типа Apache Kafka, Trino выполняет распределенные SQL-операторы над исходными данными, не копируя их. Параметры подключения к источнику данных задаются в конфигурациях коннектора, хранящихся в каталоге. Как это сделать, мы рассказывали вчера.
Сопоставляя нереляционные модели хранения данных с отображениями в виде таблиц, Trino выполняет операторы ANSI SQL в распределенном кластере из координатора и рабочих узлов. При этом Trino преобразует SQL-оператор в запрос и создает распределенный план его выполнения, который затем распределяется по рабочим узлам кластера. Оператор потребляет, преобразует и производит данные. Например, сканирование таблицы извлекает данные из коннектора и производит данные, которые могут быть использованы другими операторами, а оператор фильтра потребляет данные и производит подмножество, применяя предикат к входным данным.
Оператор можно рассматривать как текст SQL, который передается в Trino, а запрос относится к конфигурации и компонентам, созданным для выполнения этого оператора. Запрос охватывает этапы, задачи, разделения, коннекторы и источники данных для получения результата.
Распределенный план запроса реализуется как ряд взаимосвязанных иерархических этапов, запущенных на рабочих узлах. Иерархия этапов запроса напоминает дерево. У каждого запроса есть корневая стадия, которая отвечает за агрегацию выходных данных с других этапов. Координатор кластера Trino использует этапы для моделирования распределенного плана запроса. Этап реализуется как серия задач, распределенных по сети рабочих узлов Trino и обрабатывающих разделения (сплит, split) – разделы более крупного набора данных. Задача Trino имеет входы и выходы, и выполняется параллельно рядом драйверов. На самом низком уровне плана распределенного запроса этапы извлекают данные через сплиты из коннекторов. На более высоком уровне плана распределенного запроса промежуточные этапы извлекают данные из других этапов. Когда Trino планирует запрос, координатор запрашивает у коннектора список всех сплитов, доступных для таблицы. Координатор отслеживает, какие машины выполняют какие задачи, и какие сплиты обрабатываются какими задачами.
Задачи содержат один или несколько параллельных драйверов. Драйверы действуют на основе данных и объединяют операторы для создания выходных данных, которые затем агрегируются задачей и затем доставляются другой задаче на другом этапе. Драйвер — это последовательность экземпляров операторов, физический набор операторов в памяти. Это самый низкий уровень параллелизма в архитектуре Trino. Драйвер имеет один вход и один выход.
Распределенная архитектура Trino требует соединения результатов, полученных на разных рабочих узлах кластера. За это отвечают обмены, которые передают данные между узлами Trino для разных этапов запроса. Задачи производят данные в выходной буфер и потребляют данные из других задач с помощью клиента обмена.
Клиенты и протоколы
Для отправки в Trino SQL-запросов и получения ответных результатов используются клиенты – клиентские приложения или драйверы и библиотеки для подключения к Trino. Trino поддерживает клиентские драйверы для Go, JavaScript и Python, а также JDBC-драйвер. JDBC-драйвер позволяет пользователям получать доступ к Trino с помощью Java-приложений и приложений, работающих в JVM. JDBC-драйвер Trino работает с Java версии 8 или выше. Версия драйвера JDBC должна быть идентична версии кластера MPP-движка или новее. Также всем пользователям, подключающимся к Trino с помощью JDBC-драйвера, должен быть предоставлен доступ к таблицам запросов в схеме system.jdbc.
Все клиентские драйверы и клиентские приложения взаимодействуют с координатором Trino с использованием клиентского протокола на основе HTTP-вызовов. Клиент отправляет SQL-запрос координатору кластера Trino, который обрабатывает его и возвращает результаты частями. Каждая часть результатов сопровождается URI-адресом, который клиент использует для запроса следующей порции данных, пока не получит все.
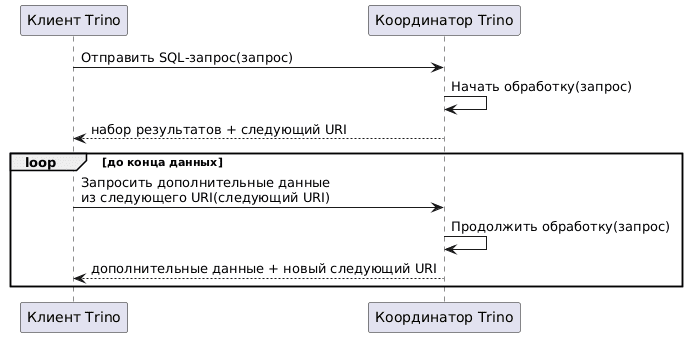
Клиентский протокол поддерживает два режима: обычный (прямой) и режим спулинга с повышенной пропускной способностью. Протокол спулинга использует объектное хранилище для хранения данных, куда параллельно записывают данные набора результатов координатор и все рабочие узлы. Координатор только предоставляет URL-адреса для всех отдельных сегментов данных в объектном хранилище кластеру. Протокол спулинга также позволяет сжимать данные. После того, как клиент получил, т.е. загрузил себе данные, они автоматически удаляются из объектного хранилища.
JDBC-драйвер MPP-движка автоматически использует протокол спулинга для повышения пропускной способности клиентских взаимодействий, если это настроено в кластере. При желании можно настроить кодировку, задав параметр encoding. Процесс JVM, использующий JDBC-драйвер, должен иметь сетевой доступ к объектному хранилищу спулинга.
По сравнению с обычным протоколом, спулинг имеет следующие преимущества:
- обеспечивает более высокую пропускную способность при передаче данных, особенно для больших наборов результатов;
- приводит к более быстрому завершению обработки запросов в кластере, независимо от того, извлекает ли клиент все данные, поскольку они считываются из объектного хранилища;
- снижает нагрузку на ЦП и ввод-вывод координатора;
Если для некоторых запросов и/или клиентов (клиентских драйверов и приложений) не подходит режим спулинга, протокол автоматически меняется на прямой (обычный). Обычно для использования режима спулинга требуются более новые клиентские драйверы или клиентские приложения. При этом клиенты должны иметь доступ к объектному хранилищу. Также требуется хранение и настройка объектов в кластере Trino. Как настроить конфигурации безопасного доступа при этом, читайте в нашей новой статье.
Прямой протокол передает все данные от рабочих узлов к координатору, который возвращает их клиенту. Этот протокол работает медленнее спулинга, особенно для запросов, возвращающих много данных из-за последовательного предоставления и потребления данных. Это увеличивает нагрузку на ЦП и ввод-вывод координатора. Однако, прямой обычный протокол не требует специфических настроек, хранения или настройки объектов в кластере Trino, а также работает со старыми клиентскими драйверами и клиентскими приложениями без поддержки протокола спулинга.
Освойте использование Trino на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

