 1031
1031 
Как повысить скорость выполнение SQL-запросов в Spark-приложениях, используя Gluten – новый вычислительный движок, объединяющий несколько векторизированных механизмов выполнения с поддержкой аппаратных ускорителей.
Что такое Gluten и как он появился в Apache Spark
Когда данных много, их обработка может длиться долго. Чтобы ускорить вычисления с Big Data, разработчики распределенных приложений и дата-инженеры применяют различные приемы оптимизации настроек инфраструктуры, исходного кода и самих данных. Для Apache Spark, который считается самым популярным вычислительным движком аналитики больших данных, в 2022 году был представлен очередной инструмент повышения скорости выполнения SQL-запросов под названием Gluten.
Этот проект с открытым исходным кодом от компаний Intel и Kyligence заменяет Gazelle – SQL-механизм на основе Apache Arrow. В 2021 году Intel выпустил Gazelle, чтобы раскрыть возможности своей технологии Intel Advanced Vector Extensions (Intel AVX) с использованием SIMD-инструкций в векторизованном механизме SQL, которая позволяет Apache Spark преодолеть ограничения обработки данных на основе строк и JVM. Spark SQL отлично работает со структурированными строковыми данными, используя WholeStageCodeGen для повышения производительности кода Java JIT. Но Java JIT имеет не очень высокую производительность при использовании SIMD-инструкций, особенно при сложных запросах. Кросс-платформенное табличное представление данных в памяти Apache Arrow обеспечивает удобный для ЦП колоночный макет данных, оптимизированный для SIMD, а также включает эффективный SQL-движок на основе LLVM Gandiva. Плагин Gazelle повторно реализует уровень выполнения Spark SQL с обработкой колоночных данных, повышая его производительность.
Несмотря на статус открытого кода и регулярные обновления в Github-репозитории, основным недостатком Gazelle было ограниченное участие сообщества. Поэтому компания Intel решила объединить свои усилия с другими векторизованными SQL-движками, которые активно развиваются с корпоративной поддержкой и пользуются спросом у энтузиастов профессионального сообщества. Например, Velox и движок Clickhouse, разработанный Kyligence.
Gluten в переводе с латыни означает клей, иллюстрируя идею кооперации нескольких векторизованных SQL-движков для их использования с Apache Spark. Такая интеграция делает возможным перенос функций и операторов в векторизованную библиотеку, внедрение механизмов компиляции «точно в срок» и использование аппаратных ускорителей, например, GPU и FPGA. Как устроен этот движок, рассмотрим далее.
Архитектура и принципы работы
Gluten повторно использует большую часть инфраструктуры Spark: планирование ресурсов, оптимизатор логического плана Catalyst и пр., а также предоставляет несколько новых компонентов для обработки API между JVM и собственными библиотеками.
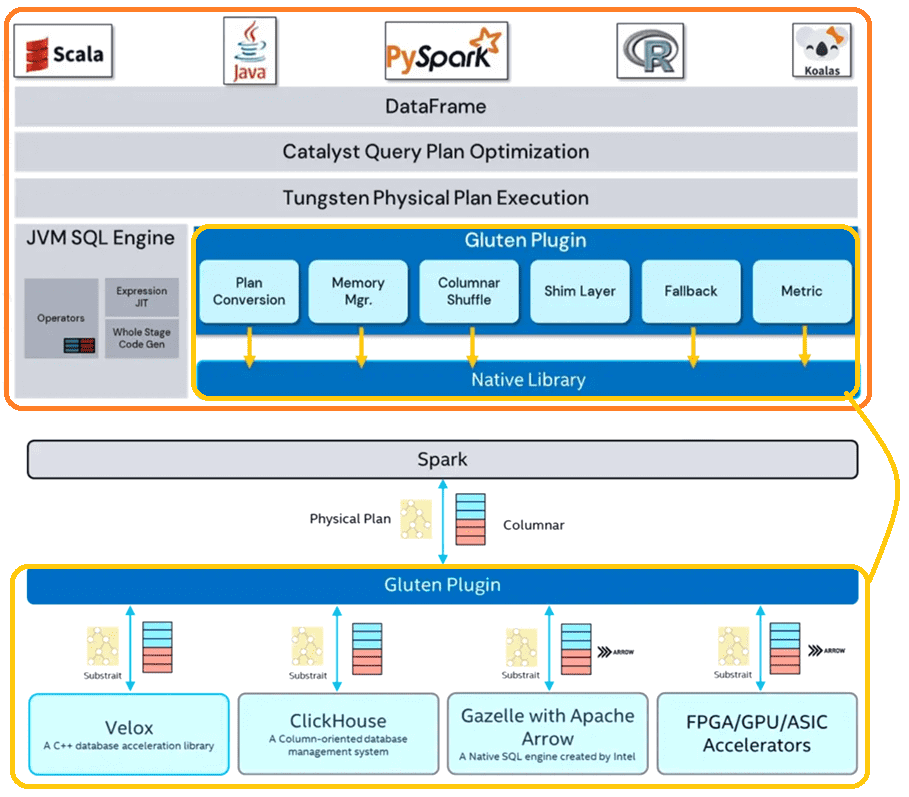
В Apache Spark есть несколько нативных библиотек, которые можно разгрузить с помощью Gluten. В частности, Velox как часть Gluten, представляет собой библиотеку ускорения базы данных C++, которая предоставляет повторно используемые, расширяемые и высокопроизводительные компоненты обработки данных. Также в Gluten реализован базовый бэкенд на вычислительном движке Arrow. Впрочем, Gluten может быть легко расширен на любые библиотеки ускорителей в качестве серверной части, чтобы реализовать следующие функции:
- преобразование плана запроса, которое трансформирует физический план в план нижнего уровня на каждом этапе;
- использование унифицированного управления памятью в Spark для управления собственным распределением памяти;
- перетасовка столбцов для непосредственного перемешивания данных с помощью службы в ядре Spark и переопределения оператора обмена для поддержки колоночного формата данных;
- для неподдерживаемых операторов или функций Gluten заменяет исходный оператор, используя нативные преобразователи C2R и R2C для преобразования данных столбцов и внутренних данных строк;
- сбор метрик из собственной библиотеки их отображение в пользовательском интерфейсе фреймворка;
Для поддержки нескольких релизов (3.2 и 3.3) Apache Spark в Gluten используется специальный shim-слой. Основное правило дизайна Gluten заключается в повторном использовании всего потока управления Spark и большого объема кода JVM для разгрузки части обработки данных с интенсивными вычислениями через следующие действия:
- преобразование физического плана этапа Spark в план Substrait и отправка в нативный движок выполнения;
- перенос обработки данных, критически важных для производительности, в собственную библиотеку;
- четкое определение интерфейсов JNI для собственных библиотек;
- простое переключение собственных бэкэндов;
- повторное использование распределенного потока управления Spark;
- управление обменом данными между JVM и нативным движком;
- расширение поддержки аппаратных ускорителей.
Gluten использует Substrait.io для построения дерева плана запроса, преобразуя физический план Spark в план Substrait для каждого бэкэнда, который затем передает через JNI, чтобы запустить конвейер выполнения в собственной библиотеке. Также Gluten использует существующий движок Spark JVM, чтобы проверить, поддерживается ли оператор нативной библиотекой. Если нет, Gluten возвращается к существующему оператору JVM за счет преобразования данных из столбцов в строки и из строк в столбцы.
Gluten использует существующую систему управления памятью Spark, вызывая API регистрации памяти для каждого действия по выделению/освобождению собственной памяти. Фреймворк управляет памятью для каждого потока задач. Если потоку требуется больше памяти, чем доступно, он может вызвать интерфейс переброса данных из памяти на диск для операторов, поддерживающих эту возможность. При этом система управления памятью Spark защищает от утечек памяти и нехватки памяти.
Gluten повторно Columnar Shuffle Manager от Gazelle на основе Apache Arrow в качестве диспетчера перемешивания по умолчанию. Сторонняя библиотека отвечает за преобразование данных в Arrow. Также разработчики могут реализовать свой собственный менеджер случайного воспроизведения. Gluten поддерживает функциональность показателей Spark, используя метрики по умолчанию для обработки данных Java на основе строк и расширяя это с помощью API на основе столбцов и дополнительных показателей, чтобы упростить процессы тестирования и отладки.
Таким образом, Gluten предназначен для администраторов и пользователей, которые хотят существенно улучшить производительность своего Spark-кластера. По сути, Gluten является подключаемым модулем, т.е. плагином для Apache Spark, разгружая его SQL-движок на собственный без каких-либо изменений API датафрейма или SQL-запроса. Дата-инженеры могут без проблем запускать свои задания Spark SQL на Gluten без изменений кода. Но в качестве плагина Gluten нуждается в некоторых конфигурациях, чтобы включить его при запуске контекста Spark. В заключение отметим, что этот проект все еще находится в стадии активной разработки и не имеет официального бинарного релиза. Поэтому единственный на сегодня способ использовать Gluten — это собрать из исходного кода, скопировать JAR-архив в JAR-файлы своего Spark-приложения, а затем включить подключаемый модуль Gluten при запуске Context. В будущем это неудобство будет устранено. Также разработчики планируют расширить поддержку аппаратных ускорителей, таких как графические процессоры, FPGA и пр., а также вторичной памяти, поддерживаемой Compute Express Link (CXL), что особенно важно для проектов машинного обучения.
Читайте в нашей новой статье про плагин RAPIDS Accelerator для Apache Spark, который позволяет запускать распределенные приложения аналитики больших данных и проекты машинного обучения на графических процессорах, благодаря программно-аппаратному ускорению.
Узнайте больше про Apache Spark для разработки приложений аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
Источники

