
О том, что такое spill-эффект, мы недавно писали на примере Apache Spark. Однако, проблема переброса данных из оперативной памяти на жёсткий диск и обратна характерна и для Greenplum. Где посмотреть количество и объем spill-файлов, а также как устранить причину их образования с помощью конфигурационных параметров и инструментов администратора. Что такое...
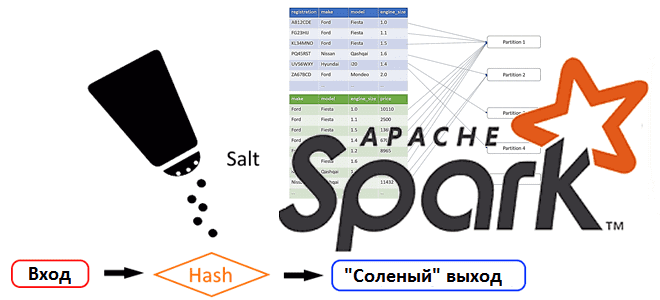
В этой статье для разработчиков Spark-приложений рассмотрим, как избежать искаженных данных с помощью простого и давно известного в криптографии приема, который принято называть «соль». Почему неравномерное распределение данных может вызвать ошибку нехватки памяти и как сбалансировать распределение ключей, добавив столбец со случайными числами. Перекосы и перемешивания Искажение или неравномерное распределение...

Ранее мы писали о том, как фотохостинг Pinterest с помощью новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, объединяет пакетную и потоковую аналитику больших данных, чтобы еще лучше обслуживать более 475 миллионов своих пользователей. Сегодня поговорим про контроль сетевого трафика и синхронизацию источников данных через генерацию...

Недавно мы рассказывали про KubeMQ – stateless-сервис обмена сообщениями для Kubernetes, который может заменить собой сложное развертывание Apache Kafka на этой платформе управления контейнерами. Сегодня разберем, как устроен KubeMQ и сравним его с Apache Kafka по нескольким параметрам, наиболее интересным для разработчиков распределенных приложений и администраторов. Операторы и пользовательские ресурсы...
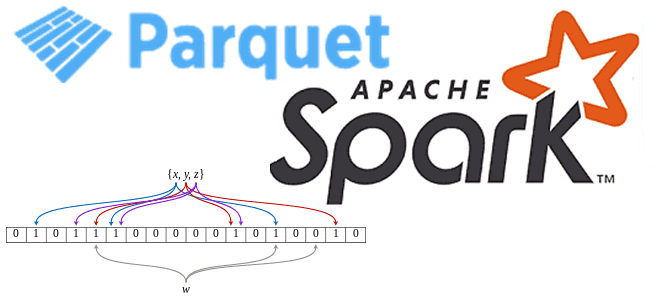
Сегодня рассмотрим, что такое фильтр Блума и как эта структура данных используется в Apache Spark для чтения Parquet-файлов. Про хеширование, UUID, достоинства и недостатки Bloom-фильтра для бинарного колоночного формата хранения больших данных в распределенных системах. Что такое фильтр Блума Фильтр Блума активно используется во многих информационных системах для быстрого поиска...
Мы уже писали, зачем нужна статистика таблиц при оптимизации SQL-запросов на примере Greenplum. Сегодня рассмотрим, как собрать статистические данные в таблицах Apache Hive, каким образом это поможет оптимизатору запросов и какие есть способы сбора статистики в этом популярном инструменте стека SQL-on-Hadoop. Еще раз о пользе статистики для оптимизации запросов в...
Продвигая наши курсы по прикладной Data Science и графовой аналитике больших данных в бизнес-приложениях, сегодня рассмотрим специальную DS-библиотеку в Neo4j и ее возможности для фильтрации подграфов. А также разберем, чем версия сообщества отличается от Enterprise Edition, как запустить анализ слабо связанных компонент и алгоритм определения центральности на проекции графа в памяти. Graph...

Сегодня разберем пример европейской логистической компании Sixfold, которая смогла увеличить пропускную способность своей системы мониторинга транспортных отгрузок на базе Apache Kafka и Kubernetes. Также рассмотрим, как дата-инженеры Sixfold справились с проблемами изоляции при последовательной обработке сообщений и транзакционной записи в топики Kafka с базами данных отдельных микросервисов на подах Kubernetes....
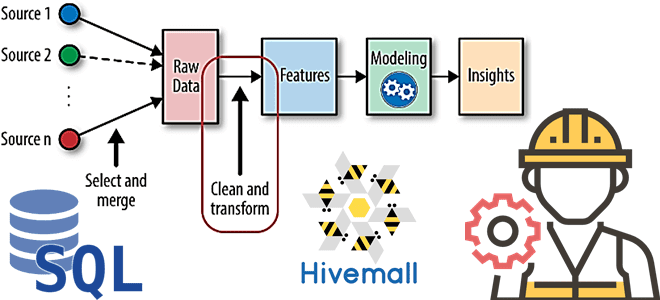
В рамках наших курсов для дата-инженеров и специалистов в области Data Science, сегодня рассмотрим, как реализовать один из важнейших этапов машинного обучения – Feature Engineering. Читайте далее, как генерировать признаки для ML-модели с помощью SQL, напрямую обращаясь к источникам данных и хранилищам фич, а также что такое Apache Hivemall и...

Развивая наши курсы для дата-инженеров по Apache AirFlow, сегодня рассмотрим, как автоматизировать развертывание сложных DAG’ов с помощью Docker и Kubernetes на примере управления конвейерами обработки данных. Лучшие практики и советы от инженеров данных DataOps-компании Databand. 4 вопроса дата-инженера к production-развертыванию конвейеров Apache Airflow Apache AirFlow считается одним из самых популярных...