В этой статье для разработчиков Spark-приложений рассмотрим, как избежать искаженных данных с помощью простого и давно известного в криптографии приема, который принято называть «соль». Почему неравномерное распределение данных может вызвать ошибку нехватки памяти и как сбалансировать распределение ключей, добавив столбец со случайными числами.
Перекосы и перемешивания
Искажение или неравномерное распределение данных по узлам кластера Apache Spark может стать причиной ошибки нехватки памяти (OOM, Out Of Memory), о которой мы писали здесь и здесь. В случае искажения данных OOM случается, когда неравномерно распределенные ключи создают очень большой раздел при операциях перемешивания (shuffle), таких как агрегации и соединения. По сути, перемешивание – это внутренний механизм Spark для перераспределения данных, чтобы они по-разному группировались по разделам. Перемешивание считается довольно затратной операцией, т.к. чаще всего это не просто однозначное копирование 1:1, а передача данных через множество исполнителей и узлов.
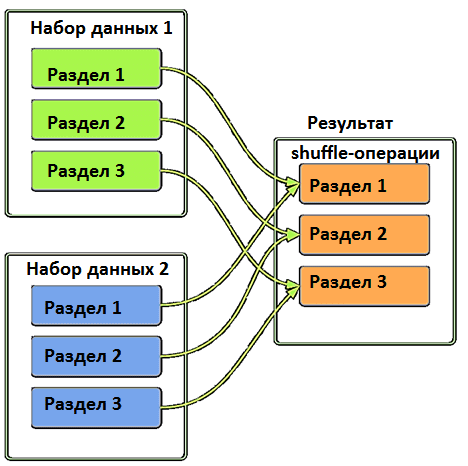
Чтобы определить, как данные группируются и куда копируются, используются ключи хеширования. При наличии ключевого столбца большего размера, чем другие, он вызывает искажение данных. Таким образом, перекосы случаются не столько из-за кластерной архитектуры Spark, сколько и из-за особенностей самого набора данных.
Например, при анализе продаж одних и тех же товаров с разделением по городам, вероятность получить перекос очень высока из-за огромной разницы между населением крупных мегаполисов и маленьких населенных пунктов. Решить проблему несбалансированного распределения ключей можно, сделав их немного разными, чтобы они могли обрабатываться равномерно. В частности, можно найти другое поле, добавить его как составной ключ или хешировать весь набор ключей. Но это работает только в том случае, если новое поле для разделения обеспечивает равномерное распределение составного ключа.
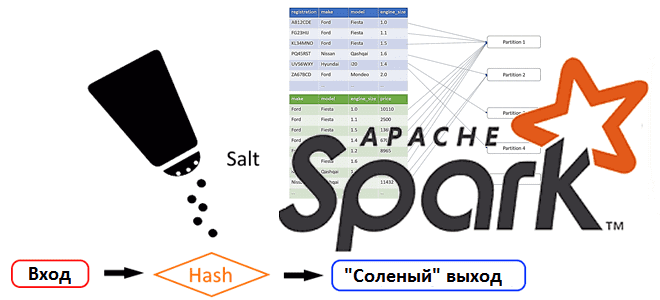
Более универсальным и простым решением является искусственный ввод случайного числа, чтобы соединить его с текущим ключом и сделать распределение по разделам равномерным. Идея намеренного добавления некоторых служебных данных к основной полезной нагрузки пришла из криптографии и называется соль (SALT). Как это сделать в Apache Spark, рассмотрим далее.
Как добавить соли в Spark
В криптографии соль или модификатор входа хеш-функции — это строка данных, которая передаётся хеш-функции вместе с входным массивом данных (прообразом) для вычисления хеша (образа). Соль повышает сложность определения первоисточника – прообраза хэш-функции методом перебора по словарю возможных входных значений, а также позволяет скрыть факт использования одинаковых прообразов. Если одна и та же соль добавляется для всех входных значений, она называется статическая. Если соль генерируется отдельно для каждого входа, ее считают динамической. Чаще всего эта техника используется для защиты паролей и электронных ключей.
Криптографический характер SALT вносит случайность в ключ без учета контекста исходного набора данных: ключ комбинируется с разными случайными числами, чтобы все данные для этого ключа обрабатывать в одном разделе. Это исключает накладные расходы на сетевую передачу и снижает вероятность возникновения OOM-ошибки. Еще одни преимуществом SALT является отсутствие семантической связи с отдельными ключами, и разработчику не придется беспокоиться о ключах с аналогичным контекстом и тем же значением.
Таким образом, в Apache Spark соль добавляет случайные значения для равномерного распределения данных по разделам. Это отлично подходит shuffle-преобразований типа операций агрегации и соединения. Чтобы показать, как это работает, рассмотрим пример.
Предположим, один из ключей партиционирования намного больше других. Применение соли будет выглядеть следующим образом:
- добавить новое поле и заполнить его случайными числами;
- объединить это новое поле и существующие ключи в составной ключ, выполнив любое преобразование;
- по завершении преобразования агрегировать окончательный результат.
На Spark Scala это может выглядеть так:
df.withColumn(“salt_random_column”, (rand*n).cast(IntegerType)) // n – желаемый размер разделов
.groupBy(groupByFields, “salt_random_column”)
.agg(aggFields)
.groupBy(groupByFields)
.agg(aggFields)
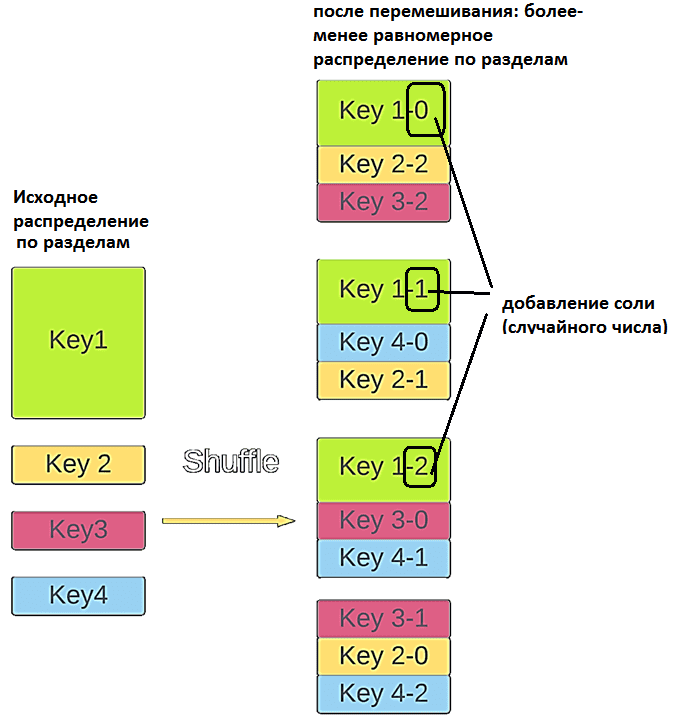
Изначально ключ 1 был намного больше других, что вызывало перекосы данных в других разделах. После применения SALT исходный ключ разделяется на 3 части, и новые ключи перемещаются в разные разделы. В этом случае ключ 1 попадает в 3 разных раздела, чтобы исходный раздел мог обрабатываться параллельно между ними.
Читайте в нашей новой статье про применение криптографических методов в Spark-приложениях с целью защиты данных. А всю практику по администрированию и использованию Apache Spark для разработки распределенных приложений и аналитики больших данных вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Apache Spark для разработчиков
- Анализ данных с Apache Spark
- Потоковая обработка в Apache Spark
- Машинное обучение в Apache Spark
- Графовые алгоритмы в Apache Spark
- https://towardsdatascience.com/skewed-data-in-spark-add-salt-to-compensate-16d44404088b
- https://en.wikipedia.org/wiki/Salt_(cryptography)

